 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 你对实时计算了解多少?
发布日期:2016-3-28 10:3:41
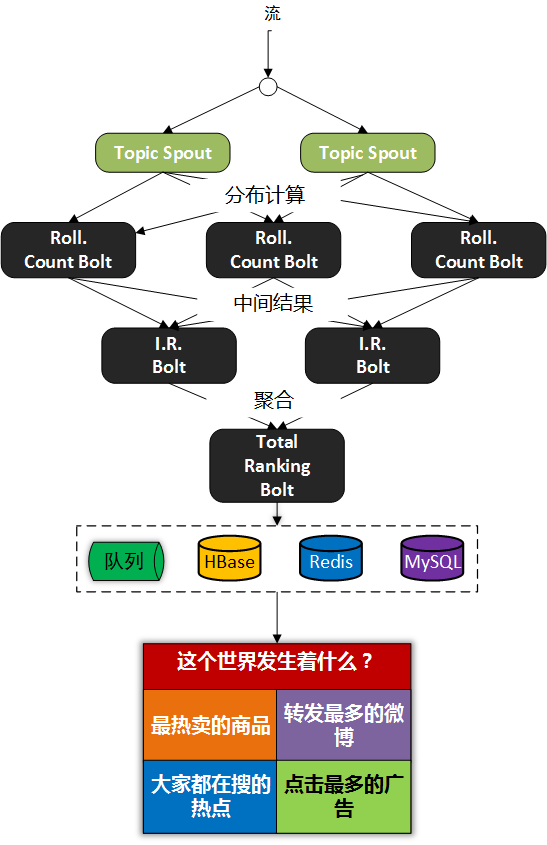
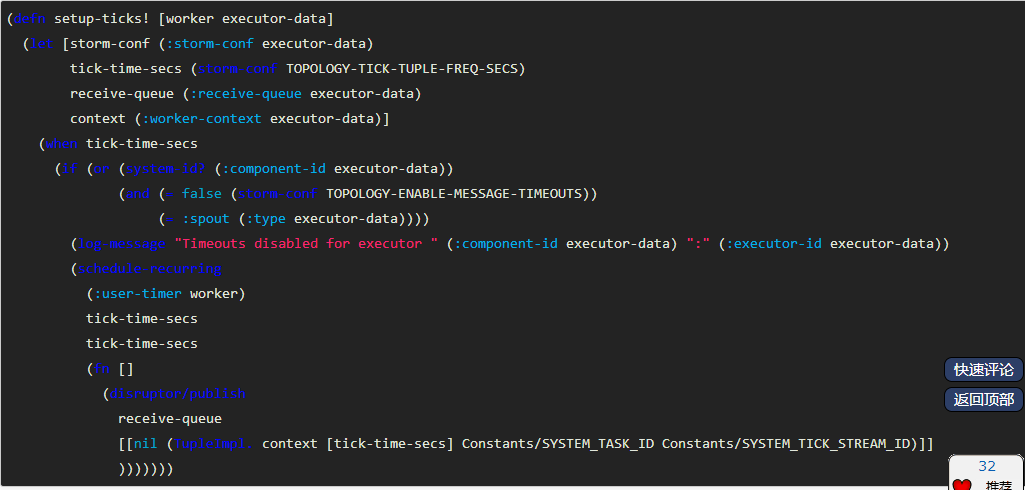
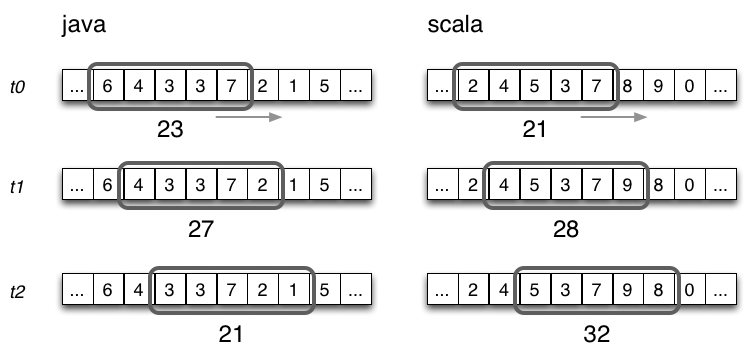
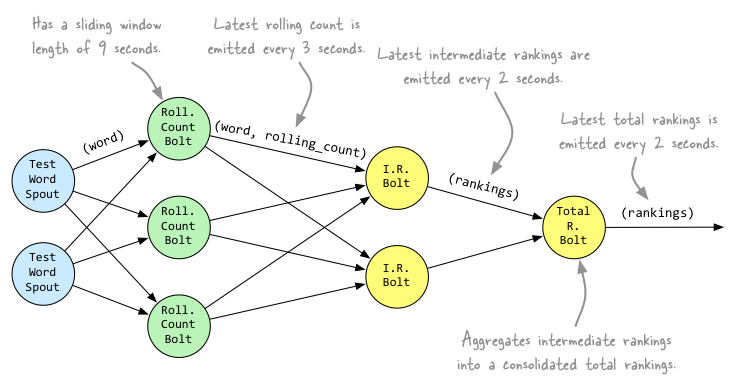
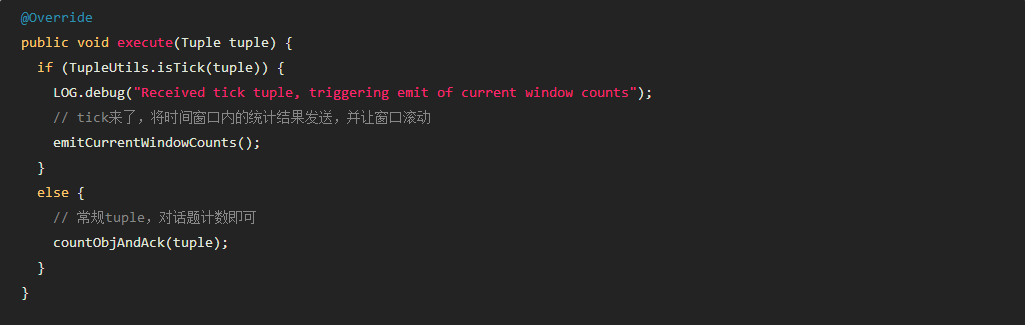
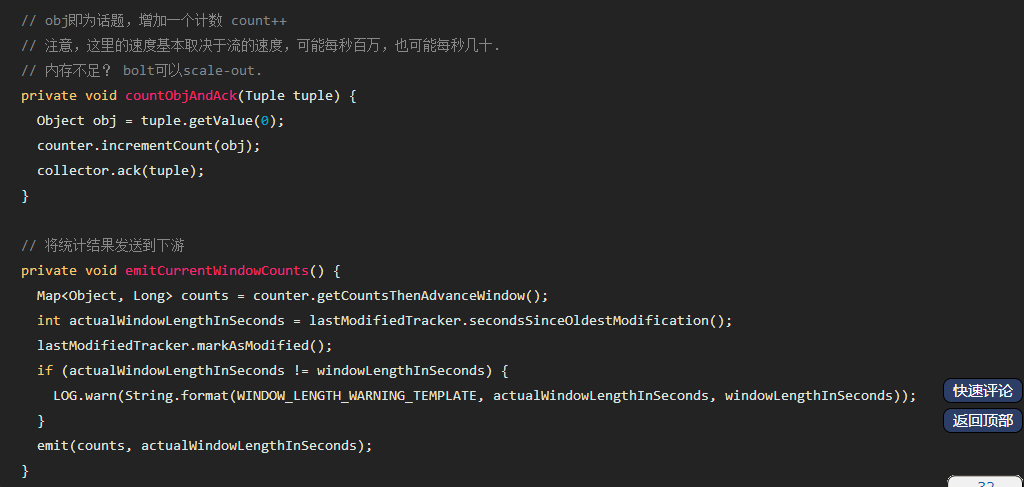
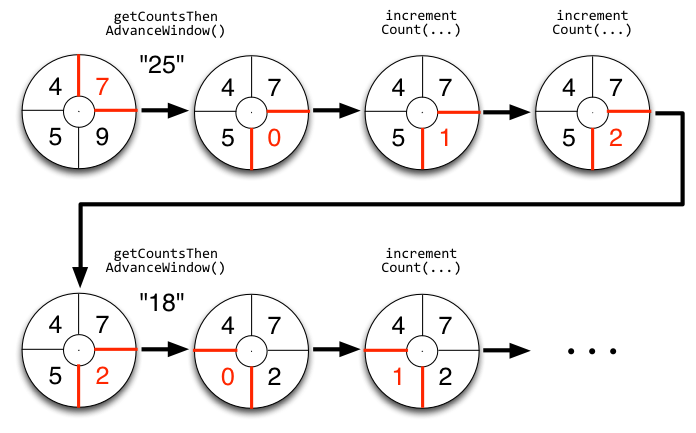
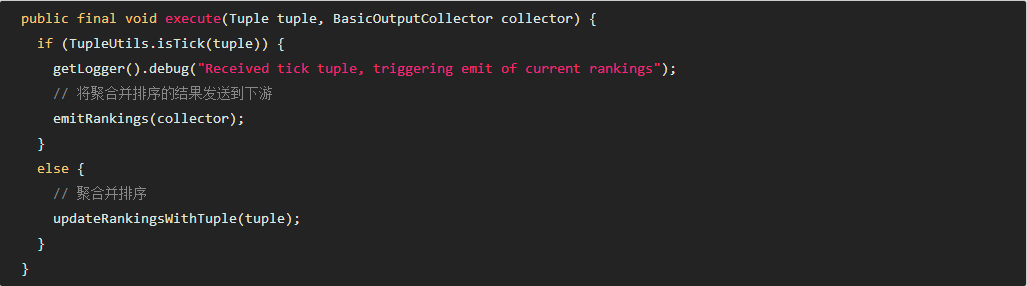
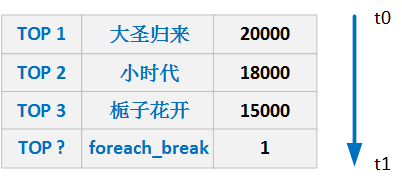
你对实时计算了解多少? 实时计算是什么? 请看下面的图: 我们以热卖产品的统计为例,看下传统的计算手段: 将用户行为、log等信息清洗后保存在数据库中. 将订单信息保存在数据库中. 利用触发器或者协程等方式建立本地索引,或者远程的独立索引. join订单信息、订单明细、用户信息、商品信息等等表,聚合统计20分钟内热卖产品,并返回top-10. web或app展示. 这是一个假想的场景,但假设你具有处理类似场景的经验,应该会体会到这样一些问题和难处: 水平扩展问题(scale-out) 显然,如果是一个具有一定规模的电子商务网站,数据量都是很大的。而交易信息因为涉及事务,所以很难直接舍弃关系型数据库的事务能力,迁移到具有更好的scale-out能力的NoSQL数据库中。 那么,一般都会做sharding。历史数据还好说,我们可以按日期来归档,并可以通过批处理式的离线计算,将结果缓存起来。 但是,这里的要求是20分钟内,这很难。 性能问题 这个问题,和scale-out是一致的,假设我们做了sharding,因为表分散在各个节点中,所以我们需要多次入库,并在业务层做聚合计算。 问题是,20分钟的时间要求,我们需要入库多少次呢? 10分钟呢? 5分钟呢? 实时呢? 而且,业务层也同样面临着单点计算能力的局限,需要水平扩展,那么还需要考虑一致性的问题。 所以,到这里一切都显得很复杂。 业务扩展问题 假设我们不仅仅要处理热卖商品的统计,还要统计广告点击、或者迅速根据用户的访问行为判断用户特征以调整其所见的信息,更加符合用户的潜在需求等,那么业务层将会更加复杂。 也许你有更好的办法,但实际上,我们需要的是一种新的认知: 这个世界发生的事,是实时的。 所以我们需要一种实时计算的模型,而不是批处理模型。 我们需要的这种模型,必须能够处理很大的数据,所以要有很好的scale-out能力,最好是,我们都不需要考虑太多一致性、复制的问题。 那么,这种计算模型就是实时计算模型,也可以认为是流式计算模型。 现在假设我们有了这样的模型,我们就可以愉快地设计新的业务场景: 转发最多的微博是什么? 最热卖的商品有哪些? 大家都在搜索的热点是什么? 我们哪个广告,在哪个位置,被点击最多? 或者说,我们可以问: 这个世界,在发生什么? 最热的微博话题是什么? 我们以一个简单的滑动窗口计数的问题,来揭开所谓实时计算的神秘面纱。 假设,我们的业务要求是: 统计20分钟内最热的10个微博话题。 解决这个问题,我们需要考虑: 数据源: 这里,假设我们的数据,来自微博长连接推送的话题。 问题建模: 我们认为的话题是#号扩起来的话题,最热的话题是此话题出现的次数比其它话题都要多。 比如:@foreach_break : 你好,#世界#,我爱你,#微博#。 “世界”和“微博”就是话题。 计算引擎: 我们采用storm。 定义时间 时间如何定义? 时间的定义是一件很难的事情,取决于所需的精度是多少。 根据实际,我们一般采用tick来表示时刻这一概念。 在storm的基础设施中,executor启动阶段,采用了定时器来触发“过了一段时间”这个事件。 如下所示: 在之前的博文中,已经详细分析了这些基础设施的关系,不理解的同学可以翻看前面的文章。 每隔一段时间,就会触发这样一个事件,当流的下游的bolt收到一个这样的事件时,就可以选择是增量计数还是将结果聚合并发送到流中。 bolt如何判断收到的tuple表示的是“tick”呢? 负责管理bolt的executor线程,从其订阅的消息队列消费消息时,会调用到bolt的execute方法,那么,可以在execute中这样判断: 结合上面的setup-tick!的clojure代码,我们可以知道SYSTEM_TICK_STREAM_ID在定时事件的回调中就以构造函数的参数传递给了tuple,那么SYSTEM_COMPONENT_ID是如何来的呢?可以看到,下面的代码中,SYSTEM_TASK_ID同样传给了tuple: 然后利用下面的代码,就可以得到SYSTEM_COMPONENT_ID: 滑动窗口 有了上面的基础设施,我们还需要一些手段来完成“工程化”,将设想变为现实。 这里,我们看看Michael G. Noll的滑动窗口设计。如下图所示: 注:图片来自http://www.michael-noll.com/blog/2013/01/18/implementing-real-time-trending-topics-in-storm/ Topology 上面的topology设计如下所示: 注:图片来自http://www.michael-noll.com/blog/2013/01/18/implementing-real-time-trending-topics-in-storm/ 将聚合计算与时间结合起来 前文,我们叙述了tick事件,回调中会触发bolt的execute方法,那可以这么做: RollingCountBolt: 上面的代码可能有点抽象,然后看下这个图就明白了,tick一到,窗口就滚动: 注:图片来自http://www.michael-noll.com/blog/2013/01/18/implementing-real-time-trending-topics-in-storm/ IntermediateRankingsBolt & TotalRankingsBolt: 其中,IntermediateRankingsBolt和TotalRankingsBolt的聚合排序方法略有不同: IntermediateRankingsBolt的聚合排序方法: TotalRankingsBolt的聚合排序方法: 而重排序方法比较简单粗暴,因为只求前N个,N不会很大: 结语 下图可能就是我们想要的结果,我们完成了t0 - t1时刻之间的热点话题统计,其中的foreach_break仅仅是为了防盗版。 上一条: 虚拟化技术的昨天、今天与明天
|









 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved