 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 CloudFoundry中各个组件的作用详解
发布日期:2016-8-3 11:8:3
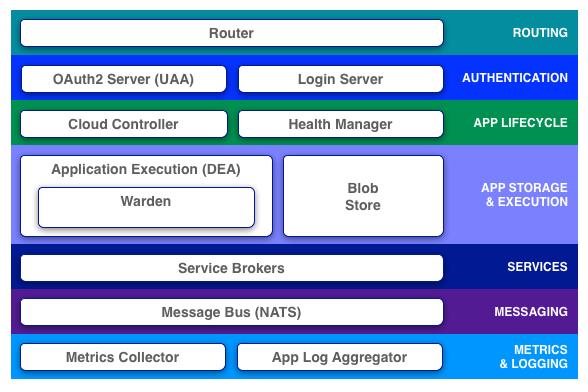
CloudFoundry是一个标杆性的项目,架构设计上有很多值得借鉴的地方,值得阿里云学习。从CloudFoundry官网摘了一张图,我们以此剖析各个组件的作用。
图1 1、Router Router是整个平台的流量入口,负责分发所有的请求到对应的组件,包括来自外部用户对app的请求与平台内部的管理请求。 Router是PaaS平台中至关重要的一个组件,在内存中它维护了一张路由表,记录域名与实例的对应关系,所谓的实例自动迁移,靠得就是这张路由表,某实例宕掉了,就从路由表中剔除,新实例创建了,就加入路由表。 CloudFoundry1.0中的router是用nginx+lua嵌入脚本实现的,2.0用golang重写,更名为gorouter,性能有所提升,并且声称试图解决websocket请求和tcp请求(尽管这在笔者看来是没用的),它的代码https://github.com/cloudfoundry/gorouter,大家可研究一下。 2、Authentication 这块包含两个组件: (1)Login Server,负责登录 (2)OAuth2 Server(UAA) UAA是个Java的项目,如果想找一个OAuth2开源方案,可尝试一下UAA 3、Cloud Controller Cloud Controller负责管理app的整个生命周期。用户通过命令行工具cf和CloudFoundry Server打交道,事实上主要就是和Cloud Controller交互。 用户把app push给Cloud Controller,Cloud Controller将其存放在Blob Store,在数据库中为该app创建一条记录,存放其meta信息,且指定一个DEA节点来完成打包动作,产出一个droplet(是一个包含Runtime的包,在任何dea节点都可通过warden run起来),完成打包后,droplet回传给Cloud Controller,仍然存放在Blob Store,然后Cloud Controller根据用户要求的实例数目,调度相应的DEA节点部署运行该droplet。此外,Cloud Controller还维护了用户组织关系org、space,以及服务、服务实例等。 4、Health Manager 最初是Health Manager用Ruby写的,后来用golang写了一版,称为HM9000,HM9000主要有四个核心功能: (1)HM9000通过dump Cloud Controller数据库的方式,获取app的期望状态、版本、实例数目 (2)监控app的实际运行状态(比如:running, stopped, crashed等等),版本,实例数目等信息。DEA会持续发送心跳包,汇报它所管辖的实例信息,若某个实例挂了,会立马发送“droplet.exited”消息,HM9000据此更新app的实际运行数据 (3)HM9000持续比对app的实际运行状态和期望状态,若发现app正在运行的实例数目少于要求的实例数目,就发命令给Cloud Controller,要求启动相应数目的实例。HM9000本身,不会要求DEA做些什么。它只是收集数据,比对,再收集数据,再比对 (4)用户通过cf命令行工具是可控制app各个实例的启停状态的,若app的状态发生变化,HM9000就会命令Cloud Controller做出相应调整 说到底,HM9000就是保证app可用性的一个基础组件,app运行的时候超过了分配的quota,或异常退出,或者DEA节点整个宕机,HM9000都会检测到,然后命令Cloud Controller做实例迁移。HM9000的代码在这里:https://github.com/cloudfoundry/hm9000,有兴趣的同学可以研究一下 5、Application Execution(DEA) DEA,即Droplet Execution Agent,部署在所有物理节点上,管理app实例,将状态信息广播出去。例如我们创建一个app,实例的创建命令最终会下发到DEA,DEA调用warden的接口创建container,若用户要删除某个app,实例的销毁命令最终也会下发到DEA,DEA调用warden的接口销毁对应的container。 当CloudFoundry刚刚推出时,Droplet包含应用的启动、停止等简单命令。用户应用可随意访问文件系统,也可在内网畅通无阻,跑满CPU,占尽内存,写满磁盘。你一切可想到的破坏性操作都可做到,太可怕了。显然CloudFoundry不会放任这样的情况太久,现在他们开发出了Warden,一个程序运行容器。这个容器提供了一个孤立的环境,Droplet只可获得受限的CPU,网络权限,内存,磁盘访问权限,再没有办法搞破坏了。 Warden在Linux上的实现是将Linux内核的资源分成若干个namespace加以区分,底层的机制是CGROUP。这样的设计比虚拟机性能好,启动快,也能获得足够的安全性。在网络方面,每一个Warden实例有一个虚拟网络接口,每个接口有一个IP,而DEA内有一个子网,这些网络接口就连在这个子网上。安全可通过iptables来保证。在磁盘方面,每个warden实例有一个自己的filesystem。这些filesystem使用aufs实现的。Aufs可共享warden之间的只读内容,区分只写的内容,提高磁盘空间的利用率。由于aufs只能在固定大小的文件上读写,因此磁盘也没有出现写满的可能性。 LXC是另一个Linux Container。那为什么不使用它,而开发了Warden呢。由于LXC的实现是和Linux绑死的,CloudFoundry希望warden能运转在各个不同的平台,而不只是Linux。此外Warden提供了一个Daemon和若干Api来操作,LXC提供的是系统工具。还有最重要的一点是LXC过于庞大,Warden只需要其中的一点点功能就可以了,更少的代码便于调试。 6、Service Brokers app在运行时通常需要依赖外部的一些服务,比如缓存服务、数据库服务、短信邮件服务等等。Service Broker就是app接入服务的一种方式。比如我们要接入MySQL服务,只要实现CloudFoundry要求的Service Broker API即可。但是实际情况是在我们使用CloudFoundry之前,MySQL服务已由DBA做了服务化、产品化,用起来已很方便了。有必要实现其Service Broker API,按照CloudFoundry这套规则出牌么?笔者认为没有这个必要。app仍然按照前访问MySQL服务的方式去做即可,没有任何问题。 7、Message Bus CloudFoundry使用NATS作为内部组件间通信的媒介,NATS是一个轻量级的基于pub-sub机制的分布式消息队列系统,是整个系统可松散耦合的基石。 我们以向router注册路由为例来说明NATS的作用。不管是外部用户对平台上的应用发起的请求,还是对内部组件(比如Cloud Controller、UAA)发起的请求,都是经由router做的转发,要能让router转发则首先需要向router注册路由。大体逻辑实现如下: (1)router启动的时候,会订阅router.register这个channel,同时也会定时的向router.start这个channel发送数据 (2)其他需要向router注册的组件,启动时会订阅router.start这个channel。一旦接收到消息,会立刻收集需要注册的信息(如ip、port等),然后向router.register这个channel发送消息。 (3)router接收到router.register消息后立即更新路由信息 (4)以上过程不停循环,使router的状态时刻保持最新 8、Logging and Statistics Metrics Collector会从各个模块收集监控数据,运维工程师可以据此来监控CloudFoundry,出了问题及时发现并处理。物理机的硬件监控则可以采用传统的一些监控系统来做,比如zabbix之类的。 Log这块是个大话题,CloudFoundry提供了Log Aggregator来收集app的log。我们也可通过其他手段直接把log通过网络打出来,比如syslog、scribe之类的。 9、参考资料 (1)《CloudFoundry社区文档》 http://docs.cloudfoundry.org/ (2)《limengyun’s blog》 http://limengyun.com/ (3)《新版CloudFoundry揭秘》 上一条: 构建移动云平台秘籍
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved