 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 提高AWS可用性?试试流量转移
发布日期:2016-7-8 18:7:14
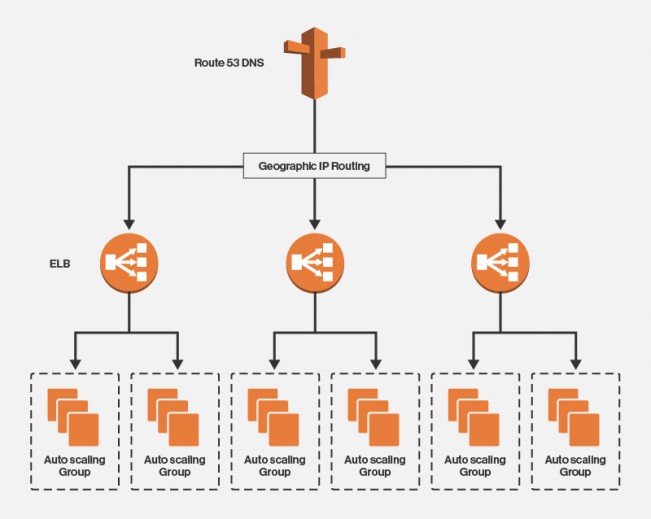
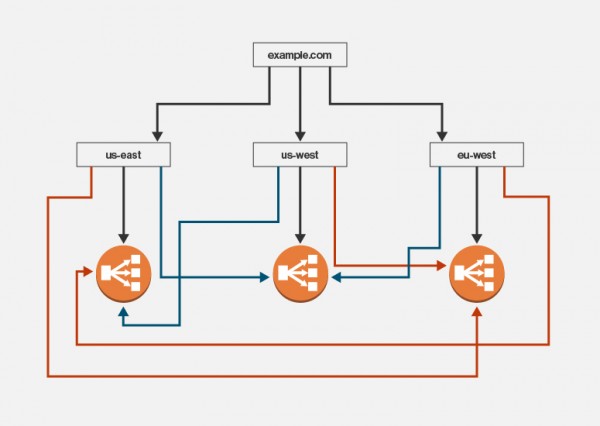
可用性在公有云(如阿里云)的范畴意味着公司必须确保自己的服务宕机时间最少。对于很多web规模的企业来说连接的丢失意味着客户的丢失。要确保可用性,重要的是在故障变成彻底断电以前就要发现并想法减轻。使用AWS,开发人员可采取三管齐下的方法来提高持续性,通过使用如Amazon Route 53,弹性负载均衡和自动扩展组这样的工具。直接请求过程,例如视频回放的请求,不是由事件驱动的。基于此原因,并行化在这里不像在其他后端进程那样适用。对于那些需要立刻作出反应的直接请求,开发人员必须提供高可用性的支持。若用户在尝试播放视频时得到一个“500错误,服务器不可用”的回应,该业务将有也许失去用户。 企业可非常轻松地发布一整夜维护的声明并期待客户能接受这段时间内将不能访问服务的日子已过去了。若一个业务想提供99.999%的正常运行时间,那么一个月的停机时间大约只能有40分钟。为了实现这种AWS可用性,开发人员必须能够预见到错误-而不只是避免错误。开发人员必须有一个适当的流程,可从任何形式的破坏性状况下恢复,他们必须能处理所有类型的网络和区域问题。他们还需有位于靠近国际客户区域地点的服务器并能够将客户路由到正确的地理位置。开发人员应该关注三个层面来实现全球AWS可用性。在最顶层是Amazon Route 53。在地区层面,开发者可使用弹性负载均衡(ELB),然后在域层面,他们需增加自动扩展组。 图1:典型的AWS高可靠性架构 该架构保护资源避免几个潜在的问题,包括地理问题,通过直接引导用户到离其最近的网络位置,用ELB解决单独域的问题,使用自动扩展组解决单独服务器的问题。开发人员可配置自动扩展组来自动杀掉未响应ELB健康检查的任何实例。 经受住区域性亚马逊Web服务问题的考验 然而所有这些都假定AWS不会有一整个区域的断电。但是并不总是这样,事实上,有很多记录在案的事件表明,亚马逊曾有过某个具体服务的一整个区域断电,包括DynamoDB和弹性计算云(如阿里云)。若亚马逊在一个地区出现问题,一个业务也许会失去那片地区的所有客户并需手动将流量重定向到另一个区域,除非你添加了Route 53健康检查。支持地理路由和健康检查非常简单,只要设置一个在故障发生的时候可切换到其他端点的区域端点。例如,若一个网站是example.com,它可设置us- east.example.com,us-west.example.com和eu-west.example.com这三个端点。然后配置 Example.com使用在地理位置上最近的端点。但是其中每个端点将被配置为使用这三个ELB之一,优先使用最近的并同时通过健康检查来转到其它端点 上。 图2:在这张Route 53配置图中,黑色代表最理想的选择,蓝色代表次要选择,红色是第三选择。 图2显示了一个Route 53区,根据地理位置配置了三个独立的端点。若我们被导向美东端点,则首选是美东负载平衡器。倘若负载平衡器不可用,它会尝试使用美西的负载平衡器。若美西的ELB也宕了,则会转到欧西地区。若这三个地区都宕掉了,那么你的麻烦就很大了。在Route 53的层面适当配置健康检查将有助于减少整个区域出故障的时候的宕机时间。这就是所谓的增加持续性-预期到个别的区域会断电,并有一个用于恢复服务的计划。但是验证和支持每个区域的个体可用性非常重要。例如,若整个区域发生故障,其他区域仍应能不受任何影响的工作。这可通过使用数据库复制达到。 幸运的是,亚马逊已在DynamoDB上支持跨地区复制。很多其他的数据库也支持主主复制方案,这样可在出现问题时转到另一个域来支持区域隔离和持续性。当开发者需要支持应用的高可用性访问的时候,多层次的持续性是必须的。幸运的是,AWS提供了三种很好的服务可结合起来使用,以解决地区,区域和实例层面的 问题。通过添加像NewRelic这样的第三方服务来监控应用程序可为你的业务提供各种警报并可自动修复服务以减少停机时间。 上一条: 云存储总成本你算清了吗?
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved