 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 浅析 docker libcontainer 代码实例的阅读
发布日期:2016-3-13 9:3:42
浅析 docker libcontainer 代码实例的阅读 读代码前的准备工作 首先,自然要下到代码才能够阅读,个人建议去下完整的 docker 源码,而不要只下载 libcontainer 的源码。不然就会像我读的时候一样掉到一个坑里面爬了半天。 接下来就要有一个代码阅读器了,因为go 语言还是个比较新的语言,配套的工具还不是很完善,不过我们能够用 liteide (自备梯子)这个轻量级的 golang ide 来兼职一下。 打开之后能够看到 docker 的目录结构大致是这样的,如下图所示:
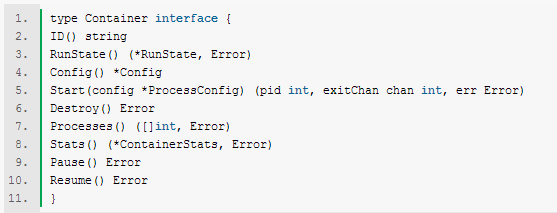
那么我们所关注的 libcontainer 在什么地方呢呢?藏得还挺深的在\verdor\src\github.com\libcontainer\。进去之后就会发现有个显眼的 container.go 在向你招手,嗯第一个坑马上就要来了。 container 初看起来这段代码还是很浅显的。代码缩水后如下图所示:
能够看出这段代码只是定义了一个接口,所有实现这些方法的对象就会变成一个 docker 认可的 container。其中比较关键的一个函数就是 Start 了,他是在 container 里启动进程的方法,能够看到接口的要求是传进一个所要启动进程相关的配置,返回一个接受退出信息的 channel和一个进程 pid 。 下一步自然就是去找这个接口的实现去看看究竟是如何做的,然后一个坑就来了。由于 go 语言不要求对象向 java 那样显示的声明自己实现哪个接口,只要自己默默实现了对应的方法就默认变成了哪个接口类型的对象。因此没有任何直观的方法来找到哪些对象实现了这个接口,翻了一下 libcontainer 文件夹下的文件感觉所有的都不像。感觉有些不详的预兆,装了个 Cygwin 去 grep Start 这个函数,结果意外的发现没有,于是又在整个 docker 目录下去 grep 发现还是没有。 我就奇怪了,不是说 docker 1.2 之后就支持 native 的 container 了么,他连 libcontainer 里的 container 接口都没实现他是如何调用 native 的 container 的。既然自底向上的找不到,那就只能自顶向下的从上层往下跟去找找怎么回事了。 driver docker 支持 lxc 和 native 两套容器实现,是通过 driver 这个接口的两个实现来完成的。在 \daemon\execdriver 中能够看到有 lxc 和 native 两个文件夹,里面就是相关的代码。不过在 \daemon\ 目录下能够看到还有一个 container.go 里面是有个 container 对象,可是并没有实现 libcontainer 里对应的接口,难道 libcontainer 里的那个 interface 只是一个幌子? 先看一下 driver 这个接口,如下所示:
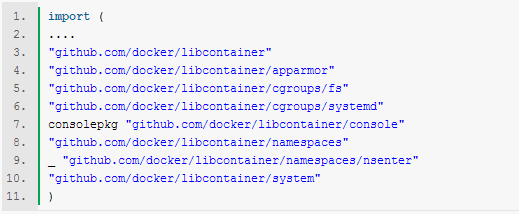
有没有感觉名字虽说和上面的 container interface 不太一样,不过意思是差不多的。resume 变成了 unpause, destory 变成了 teminate,processes 变成了 getpidsforcontainer,start 也变成了 run 和 exec 两个函数。看到这不得不说 docker 的代码的一致性和可读性还是惨了点,codereview 需要更严格一些呀。 再进到 native 的 driver.go 就能够看到具体的实现了。在文件头部发现了一长串 import,其中有几个比较抓眼球,如下图所示:
从这里似乎能够看出一点端倪了。libcontainer 的目的是提供一个平台无关的原生容器,这需要包括资源隔离,权限控制等一系列通用组件,因此libcontainer 就来提供这些通用组件,所以他叫 "lib"。而每个平台想实现自己的容器的话就能够借用这些组件,当然也能够只用一部分而不全用, docker 就相当于用了包括 apparmor、cgroups、namespaces 等等组件,然后没用 libcontainer 的 container 接口和其他一些组件,自己写了其他部分完成的所谓 native 的容器。 还是看 run 函数,如下图所示:
其中 execdriver.Pipes 是一个定义标准输入输出和错误指向的结构,startCallback 是在进程结束或者退出时调用的一个回调函数,最重要的结构是 execdriver.Command 他定义了容器内运行程序的各种环境和约束条件。能够在 daemon 下的 driver.go 中找到对应的定义。 Command 如下图所示:
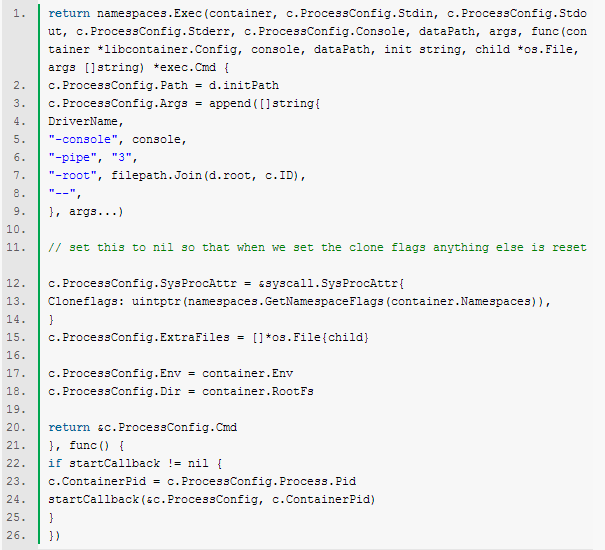
其中和进程隔离相关的有 Resources 规定了 cpu 和 memory 的资源分配,能够提供 cgroups 将来调用。 CapAdd 和 CapDrop 这个和 linux Capability 相关来控制 root 的某些系统调用权限不会被容器内的程序使用。ProcessLabel 为容器内的进程打上一个 Lable 这样的话 seLinux 将来就能够通过这个 lable 来做权限控制。Apparomoprofile 指向 docker 默认的 apparmor profile 路径,一般为/etc/apparmor.d/docker,用来控制程序对文件系统的访问权限。 能够看到,docker 对容器的隔离策略并不是自己开发一套隔离机制而是把现有的能用的已有隔离机制全用上。甚至 seLinux和AppArmor 和, 这两个类似并且人家两家还在相互竞争的机制也都一股脑不管三七二十一全加上,颇有拿来主义的风采。这样的话万一恶意程序突破了一层防护还有另外一层挡着,而且这几个隔离机制还相互保护要同时突破所有的防护才行。 而我们真正要在容器中执行的程序在 ProcessConfig 这个结构体中的 Entrypoint。由此我们可以知道,所谓的容器就是一个穿着各种隔离外套的程序,用这些隔离外套保护这个程序能够活在自己的小天地里,不知有汉无论魏晋。 Exec 还是回到 run 里面看看究竟是怎么 run 的吧,看完了一系列的初始化和异常判断后终于到了真正运行的代码,只有一行,长得是这个样子的,如下图所示:
看到这里整个人都不好了,我觉得 docker 这个项目要是这样下去会出问题的,就算你喜欢匿名函数也不要这么偏执好么。我甚至怀疑 docker 在用什么黑科技来隐藏他的真实代码了。于是我决定放弃这行代码直接看 namespaces.Exec 去了。在\verdor\src\github.com\libcontainer\namespaces\exec.go里,如下图所示:
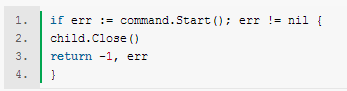
不太确定一个函数8个参数真的好么,但是我更纳闷的是在主项目里既然都有 pipe 这个结构把 stdin,stdout,stderr 放在一起为什么到这里就要分开写了,6个虽然也不少,但是比8个要好点。回过头来说一下 namespace ,这又是另一种隔离机制。顾名思义,隔离的是名字空间,这要的话本来属于全局可见的名字资源,如 pid,network,mountpoint 之类的资源虚拟出多份,每个 namespace 一份,每组进程占用一个 namespace。这样的话容器内程序都看不到外部其他进程,攻击的难度自然也就加大了。 然后这里面最关键的执行的一句倒是很简单了。如下图所示:
其中的 command 是系统调用类 exec.Cmd 的一个对象,而之前的关于程序的配置信息已经在那个一行的执行代码里都整合进 command 里了,在这里只要 start 一下程序就跑起来了。然后我就疑惑了,这个函数不是 namespaces 包下的么,为什么没有 namespaces 设置的相关代码呢。其实你仔细看那一行的执行代码能够发现 namespaces 的设置也在里面了,换句话说这个 namespaces 包下的 exec 其实没有做什么和 namespaces 相关的事情,只是 start 了一下。这种代码逻辑结构可是给读代码的人带来了不小的困惑啊。 总结 这次读代码的起点是想搞懂容器是怎样做隔离和保证安全的。从代码来看 docker 并没有另起炉灶新开发机制,而是将现有经过考验的隔离安全机制能用的全都用上,包括 cgroups,capability,namespaces,apparmor 和 seLinux。这样一套组合拳打出来的效果理论上看还是很好的,就算其中一个机制出了漏洞,但是要利用这个漏洞的方法很可能会被其他机制限制住,要找到一种同时绕过所有隔离机制的方法难度就要大多了。 至于 libcontainer 尽管从 docker 中独立出去发展,但是能够看出和主项目还有一些没有切分干净的地方,而且 docker 主项目目前也没有采用 libcontainer 中的 container 方式,只是在调用里面的一些机制方法,看样子目前还处于一个逐步替换的过程中。libcontainer 和一个独立完整的产品还有一段距离,诸位有兴趣的也能够参与进去,万一这就是下一个伟大的项目呢? 但是从读代码的角度来看,docker 的代码的质量就让人很难恭维了,就算 libcontainer 是一个独立的部分,但本是同根生的名字都不一致,不知道之后会不会更混乱。而一些代码风格和逻辑上也实在让人读起来很费劲,代码质量要提高的地方还有很多。毕竟是开源的项目,即使功能很强大,但是大家如果发现代码质量有问题,恐怕也不大敢用在生产吧。 原文出自:https://docker.cn/p/docker-libcontainer-reading
|







 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved