 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 关于mapreduce top n实现方式实例的简介
发布日期:2016-3-5 17:3:23
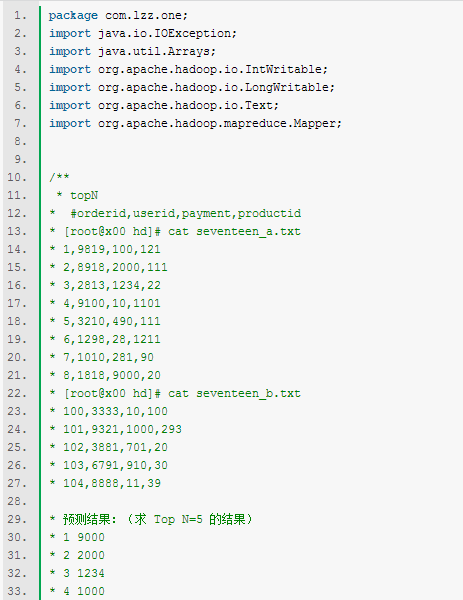
关于mapreduce top n实现方式实例的简介 在最初接触mapreduce时,top n 问题的解决办法是将mapreduce输出(排序后)放入一个集合中,取前n个,但是由于这种写法过于简单,内存能够加载的集合的大小也是有上限的,一旦数据量太大,很容易出现内存溢出。 今天在这里介绍另一种实现方式,当然这也不是最好的方式,不过正所谓一步一个脚印,迈好每一步,以后的步伐才能够更加的坚定,哈哈说了点题外话。以后还会有更好的方式需求,得到top 最大的前n条记录。 这里只给出一些核心的代码,其他job等配置的代码略。如下图所示:
初始化job之前需要 conf.setInt("N",5); 意在在mapreduce阶段读取N,N就代表着top N。 map如下图所示:
接下来是reduce,如下图所示:
说一下逻辑,虽然画图比较清晰,但是由于时间有限以及画图水平有限,我们就只用语言来描述吧,希望能说的明白。 如果要取top 5,则应该定义一个长度为为6的数组,map所要做的事情就是将每条日志的那个需要排序的字段放入数组第一个元素中,调用Arrays.sort(Array[])方法可以将数组按照正序,从数字角度说是从小到大排序,比如第一条记录是9000,那么排序结果是[0,0,0,0,0,9000],第二条日志记录是8000,排序结果是[0,0,0,0,8000,9000],第三条日志记录是8500,排序结果是[0,0,0,8000,8500,9000],以此类推,每次放进去一个数字如果大于数组里面最小的元素,相当于将最小的覆盖掉了,也就是说数组中元素永远是拿到日志中最大的那些个记录。 ok,map将数组原封不动按照顺序输出,reduce接收到从每个map拿到的五个排好序的元素,在进行跟map一样的排序,排序后数组里面就是按照从小到大排好序的元素,将这些元素倒序输出就是最终我们要的结果了。 和之前的方式做个比较,之前的map做的事情很少,在reduce中排序后哪前5条,reduce的压力还是比较大的,要把所有的数据都处理一遍,而一般设置reduce的个数较少,一旦数据较多,reduce就会承受不了,悲剧了。而现在的方式巧妙的将reduce的压力转移到了map,而map是有集群效应的,很多台服务器来做这件事情,减少了一台机器上的负担,每个map其实只是输出了5个元素而已,如果有5个map,其实reduce才对5*5个数据进行了操作,也就不会出现内存溢出等问题了。 原文出自:http://my.oschina.net/u/1378204/blog/343666
|








 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved