 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 PostgreSQL sharding for Oracle,DB2, SQL Server, Sybase
发布日期:2016-4-24 12:4:50
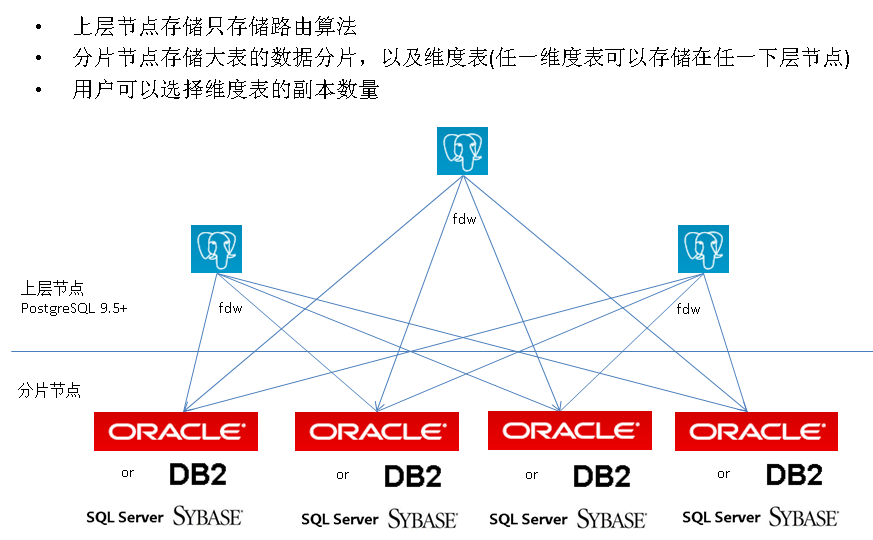
PostgreSQL sharding for Oracle,DB2, SQL Server, Sybase Oracle 12c支持sharding,但是对于低版本,要怎样做才能实现水平分库呢? 在写PostgreSQL 水平分库方案时,突然想到为什么不利用PostgreSQL的分片技术来实现对Oracle的分片呢? 分库技术架构和实践可以参考参考: http://blog.163.com/digoal@126/blog/static/16387704020161239252998/ 如果要做到对Oracle用户完全透明,那么需要满足一下几个条件: 1. PostgreSQL必须支持Oracle的存储过程和函数,以及包。这一点 EnterpriseDB 可以满足需求。 2. PostgreSQL必须支持Oracle的SQL语法,这一点 EnterpriseDB 可以满足需求。 如果用户愿意修改不兼容的SQL和函数,使用社区版本的 PostgreSQL 就能满足分片需求了。 分片架构如下所示: 可以支持几乎任何数据库的分片。 分为两层: 1. 上层为PostgreSQL 或者EnterpriseDB(如果需要兼容Oracle特殊语法),在上层节点中,需要存储表的定义,路由算法,函数,视图,存储过程,序列等全局数据。 上层的PostgreSQL数据库可以有1个或多个,至少1个。 2. 下层为数据分片节点,可以是任何数据库品种,比如下图中所述的Oracle, Sybase,DB2, SQL Server。在分片节点中,存储数据分片,维度表(用户可以自定义维度表的副本数)。 注意,如果要支持函数,必须将原数据库的函数转换为PostgreSQL的函数,在PostgreSQL中可以使用plpgsql语言来实现,包括自治事务也能实现 (参考 http://blog.163.com/digoal@126/blog/static/163877040201613982063/ )。 如果使用EnterpriseDB,那么大多数的Oracle函数语法都兼容,用户可以不修改,直接使用就可以了。 这里以Oracle为例,介绍实施步骤: .1. 首先安装Oracle数据节点,这里假设有4台Oracle数据库,分别为db0,db1,db2,db3。 .2. 安装一台PostgreSQL 9.5+ 以及 oracle_fdw插件。 插件位置:http://pgxn.org/dist/oracle_fdw/ 里面含详细说明,推荐阅读。 http://blog.163.com/digoal@126/blog/static/163877040201181505331588/ 安装好之后,设置正确的 NLS_LANG 环境变量(_. (for example AMERICAN_AMERICA.AL32UTF8)),然后重启数据库。 .3. 配置oracle数据库监听,以及主机防火墙,允许PostgreSQL数据库访问Oracle数据库。 .4. 在PostgreSQL数据库中创建所有数据节点的foreign server, 本例需要4个foreign server, user mapping。 例如 (请使用正确的 IP,端口和sid, username, password替换) : master=# create extension oracle_fdw; master=# create server db0 foreign data wrapper oracle_fdw OPTIONS (dbserver '//ip:port/sid'); master=# create server db0 foreign data wrapper oracle_fdw OPTIONS (dbserver '//ip:port/sid'); master=# create server db0 foreign data wrapper oracle_fdw OPTIONS (dbserver '//ip:port/sid'); master=# create server db0 foreign data wrapper oracle_fdw OPTIONS (dbserver '//ip:port/sid'); master=# create user mapping for postgres server db0 options (user 'username', password 'pwd'); master=# create user mapping for postgres server db1 options (user 'username', password 'pwd'); master=# create user mapping for postgres server db2 options (user 'username', password 'pwd'); master=# create user mapping for postgres server db3 options (user 'username', password 'pwd'); .5. 规划表分区的分布列,如果分布列不是INT类型,可以使用hash函数转换为INT。按abs(mod(column,4))的值计算分布规则。 .6. 在所有的数据节点db[0-3],创建需要分片的表,以及分布列的 check 约束。 例如: on db0: create table tbl ( id int primary key , info varchar2(32), crt_time date, check (abs(mod(id,4))=0)); on db1: create table tbl ( id int primary key , info varchar2(32), crt_time date, check (abs(mod(id,4))=1)); on db2: create table tbl ( id int primary key , info varchar2(32), crt_time date, check (abs(mod(id,4))=2)); on db3: create table tbl ( id int primary key , info varchar2(32), crt_time date, check (abs(mod(id,4))=3)); .7. 规划维度表的副本数,本文例子假设维度表有2个副本,分别放在db0, db1。 .8. 在数据节点db0, db1创建维度表。 例如: on db0: create table test ( id int primary key, info varchar2(32), crt_time date); on db1: create table test ( id int primary key, info varchar2(32), crt_time date); .9. 在PostgreSQL节点,创建分片表的外部表,必须包含CHECN约束。必须制定KEY,否则就不能写。 create FOREIGN table tbl0 (id int OPTIONS (key 'true') , info varchar(32), crt_time timestamp without time zone) server db0 options (table 'tbl', schema 'username'); create FOREIGN table tbl1 (id int OPTIONS (key 'true') , info varchar(32), crt_time timestamp without time zone) server db1 options (table 'tbl', schema 'username'); create FOREIGN table tbl2 (id int OPTIONS (key 'true') , info varchar(32), crt_time timestamp without time zone) server db2 options (table 'tbl', schema 'username'); create FOREIGN table tbl3 (id int OPTIONS (key 'true') , info varchar(32), crt_time timestamp without time zone) server db3 options (table 'tbl', schema 'username'); alter foreign table tbl0 add constraint ck_tbl0 check (abs(mod(id,4))=0); alter foreign table tbl1 add constraint ck_tbl1 check (abs(mod(id,4))=1); alter foreign table tbl2 add constraint ck_tbl2 check (abs(mod(id,4))=2); alter foreign table tbl3 add constraint ck_tbl3 check (abs(mod(id,4))=3); .10. 在PostgreSQL节点,创建维度表的外部表 create FOREIGN table test0 (id int OPTIONS (key 'true'), info varchar(32), crt_time timestamp without time zone) server db0 options (table 'test', schema 'username'); create FOREIGN table test1 (id int OPTIONS (key 'true'), info varchar(32), crt_time timestamp without time zone) server db1 options (table 'test', schema 'username'); .11. 在PostgreSQL节点,创建分片表的父表,设置继承关系,触发器函数,触发器。 create table tbl (id int primary key, info varchar(32), crt_time timestamp without time zone); alter foreign table tbl0 inherit tbl; alter foreign table tbl1 inherit tbl; alter foreign table tbl2 inherit tbl; alter foreign table tbl3 inherit tbl; create or replace function f_tbl_ins() returns trigger as $$ declare begin case abs(mod(NEW.id, 4)) when 0 then insert into tbl0 (id, info, crt_time) values (NEW.*); when 1 then insert into tbl1 (id, info, crt_time) values (NEW.*); when 2 then insert into tbl2 (id, info, crt_time) values (NEW.*); when 3 then insert into tbl3 (id, info, crt_time) values (NEW.*); else return null; end case; return null; end; $$ language plpgsql; create trigger tg1 before insert on tbl for each row execute procedure f_tbl_ins(); .12. 然后在PostgreSQL节点,创建维度表的父表,设置继承关系,触发器函数,触发器。 create table test (id int primary key, info varchar(32), crt_time timestamp without time zone); alter foreign table test0 inherit test; -- 在不同的master节点,设置不同的继承,从而实现均衡查询的目的,目前PG内核还不支持维度表的负载均衡。 create or replace function f_test_iud() returns trigger as $$ declare begin case TG_OP when 'INSERT' then insert into test0 (id, info, crt_time) values (NEW.*); insert into test1 (id, info, crt_time) values (NEW.*); when 'UPDATE' then update test0 set id=NEW.id,info=NEW.info,crt_time=NEW.crt_time where id=OLD.id and info=OLD.info and crt_time=OLD.crt_time; update test1 set id=NEW.id,info=NEW.info,crt_time=NEW.crt_time where id=OLD.id and info=OLD.info and crt_time=OLD.crt_time; when 'DELETE' then delete from test0 where id=OLD.id and info=OLD.info and crt_time=OLD.crt_time; delete from test1 where id=OLD.id and info=OLD.info and crt_time=OLD.crt_time; end case; return null; end; $$ language plpgsql; create trigger tg1 before insert or update or delete on test for each row execute procedure f_test_iud(); 现在,你就可以测试这些表的插入,查询,更新,删除,JOIN。以及分布式事务。 插入tbl这个分片表时,会根据ID计算一个模值,插入到对应的分片节点。 更新,删除,查询时,如果提供了ID的模值,则会选择对应的子节点查询。 对于维度表test,查询时会自动查询test0, 更新,删除,插入则会在test0,test1同时操作 (非并行)。 使用这种方法给其他数据库做sharding, 除了EDB对Oracle兼容性比较好,其他的兼容性都需要用户去验证。 但是无论怎样,用户可以获得如下好处: ACID 跨库JOIN 分布式事务 主节点和数据节点都支持水平扩展 prepared statement 支持存储过程和函数
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved