 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 MongoDB 的指南
发布日期:2016-5-2 21:5:50
图1 现在系统引入 MongoDB 也有几年了,一开始是由于 MySQL 中有单表记录增长太快(每天有几千万条吧)容易拖慢 MySQL 的主从复制。 而且这类数据增长迅速的流水表,对数据一致性也没那么高要求,且业务上也不需要关联查询它,就考虑分出去。 那么为什么是 MongoDB?刚巧赶上公司 DBA 团队引入了这个数据库,有人帮助运维,对业务团队就成了一个自然的选择。 不过对于任何技术产品你若要把它用在生产环境上,最好确定对它的架构和运作机理有个全面的理解。 一、形态 MongoDB 是一种 NoSQL 数据库,在数据存储的形态上与 MySQL 这类关系数据库有本质区别。 它存储的基本对象是 Document,因此我们把它称为一种文档数据库,而文档的集合则组成了 Collection。 与 SQL 的概念类相比,Collection 对应于 Table 而 Document 对应于 Row。 Document 使用一种 BSON(Binary JSON)结构来表达,JSON 大家都熟悉,像下面这样。如图2所示:
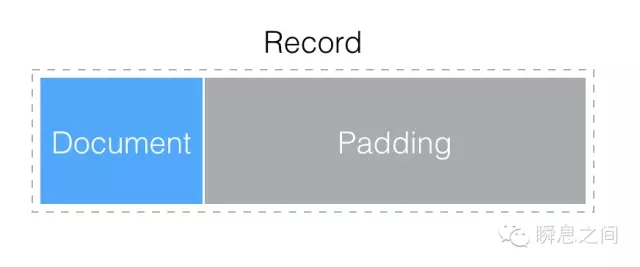
图2 Document 在内部是如何存储的?每个 Document 被保存在一个 Record 中。 Record 相当于 MongoDB 内部分配的一块空间,除了保存 Document 的内容外,可能还会预留一些填充的额外空间。 对于写入后的 Document 如果还会更新,这可能导致 Document 长度增加,就可利用上额外的填充空间来。 如果业务对于写入后的 Document 不会再更新或者删除(像监控日志、流水记录等),可以指定无填充的 Record 分配策略,更节省空间。如图3所示:
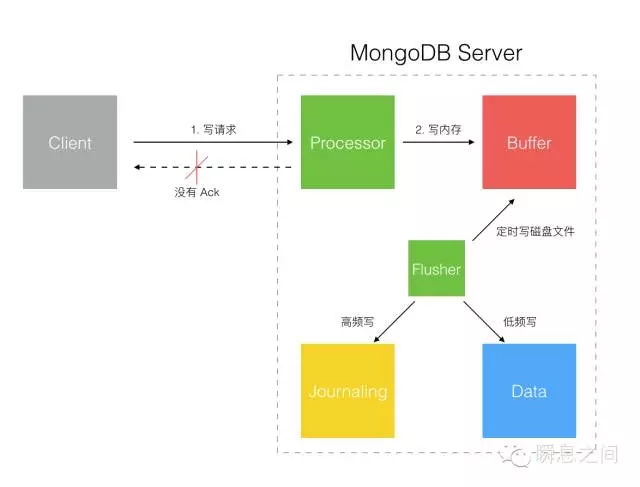
图3 在了解了 Document 形态的基础上,我们再来说点针对 Document 的访问操作。 新的 WiredTiger 存储引擎提供了 Document 级别的并发操作,所以并发性能有所改善。 另外 MongoDB 仅对单一 Document 提供事务的 ACID 保障,如果一个操作涉及多个 Document 则不能保证事务特性。 不同的业务数据对事务一致性的要求不同,因此应用开发者需要知道将数据放在不同的 Document 中写入时在一致性方面可能的影响。 详细的操作可以参考 API官方文档,在这里不赘述了。 二、安全 这里的安全指的数据安全,安全就是说数据被安全的保存好了,数据不会丢失。 关于 MongoDB 数据安全在早期的版本(1.x)引发了很多争论。(可以看参考[2]) 安全与效率其实是相互制约的,越安全则效率越低,越高效则越不安全。 MongoDB 的设计场景考虑的是应对大量的数据写入与查询,而数据的重要性相对没那么高。 因此 MongoDB 的默认设置在安全与率之间,更偏向效率。 我们先看下一个 Document 被写入到 MongoDB 后它内部的处理方式。 MongoDB 的 API 提供了不同安全级别的写入选项来让使用方根据其数据性质灵活的选择。 1.Write To Buffer Without ACK 如图4所示:
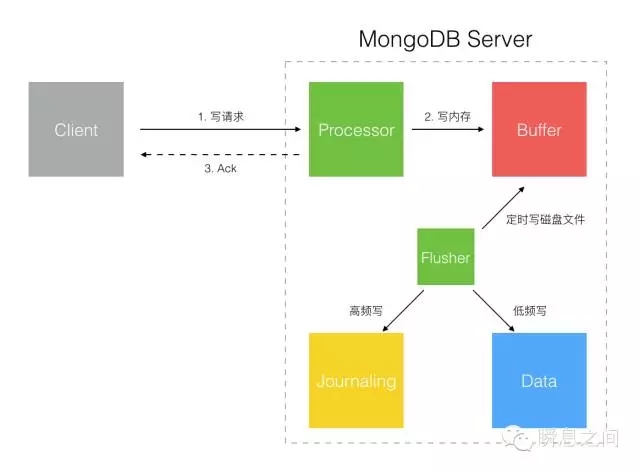
图4 图4的这个模式下 MongoDB 是不确认写请求的,Client 端调用驱动写入后若没有网络错误就认为成功,实际到底写入成功没有是不确定的。 即使网络没有问题,数据到达 MongoDB 后它先保存在内存 Buffer 中,再异步写入 Journaling 日志,这中间有 100ms(默认值) 的落盘(写入磁盘)时间窗口。 一般数据库的设计都是先写 Journaling 的流水日志,随后异步再写真正的数据文件到磁盘,这个随后可能就比较长了,MongoDB 是 60 秒或 Journaling 日志达到 2G。 2.Write To Buffer With ACK 如图5所示:
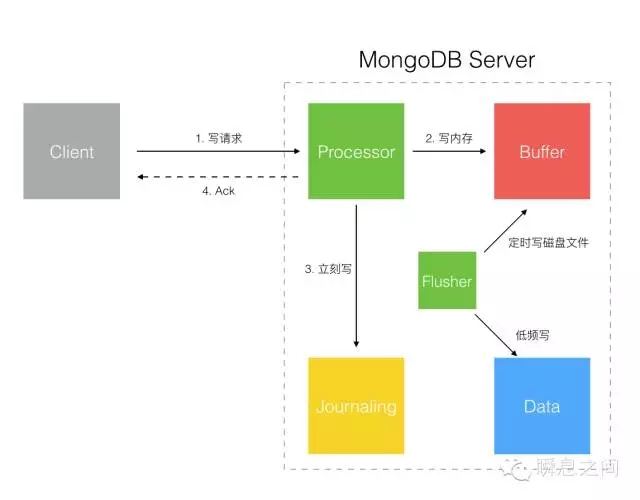
图5 图5的这个比上一种模式稍微好一点,MongoDB 收到写入请求,先写入内存 Buffer 后回发 Ack 确认。 Client 端能确保 MongoDB 收到了写入数据,但是依然有短暂的 Journaling 日志落盘时差导致潜在的数据丢失可能。 3.Write To Journaling With ACK 如图6所示:
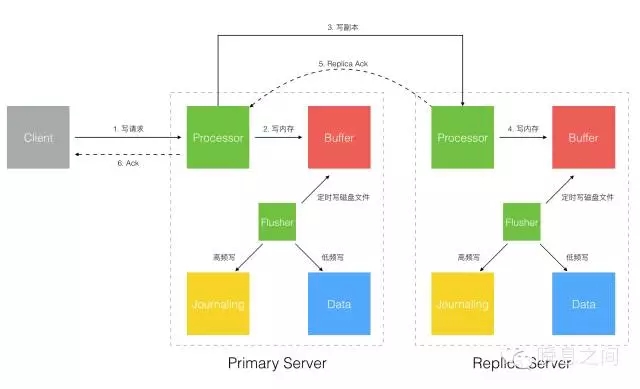
图6 图6的这个模式确保至少写入 Journaling 日志后才回发 Ack 确认,Client 端能确保数据至少写入磁盘了,安全性较高。 4.Write To Replica Buffer With ACK 如图7所示:
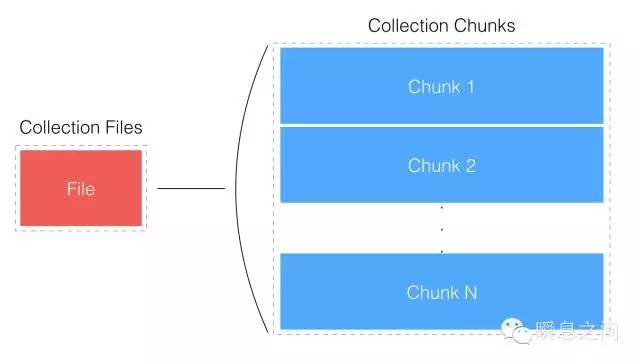
图7 图7的这个模式是针对多副本集的,为了提升数据安全性,除了及时写入磁盘也可以通过写多个副本来提升。 在这个模式下,数据至少写入 2 个副本的内存 Buffer 中才回发 Ack 确认。 虽然都在内存 Buffer 中,但两个实例在落盘短暂的 100ms 时差中同时故障的概率很低,所以安全性有所提升。 明白了不同的写入模式选项,我们才能更好的真对数据的性质选择合适的安全级别。 后面效率一节我们再分析不同写入模式下的效率差异。 三、容量 在考虑 MongoDB 整体的存储容量前,先考虑作为基本单元的 Document 的容量。Document 这种 JSON 形态天生会带来数据存储冗余,主要是 field 属性每个 Document 都会保存一遍。 目前 MongoDB 3.2 版本已经将新的 WiredTiger 作为默认存储引擎,它提供了压缩功能,有以下两种压缩形式: (1)Snappy 默认压缩算法,在压缩率和 CPU 开销之间取得平衡。 (2)Zlib 更高的压缩率,但也带来更高的 CPU 开销。 而每个 Document 依然有最大容量限制,不能无限增长下去,这个限制目前是 16MB。 那么我要存大于 16MB 的文件怎么办,MongoDB 提供了 GridFS 来存储超过 16MB 大小的文件。 如下图所示,一个大文件被拆分成小的 File Chunk,每个 Chunk 大小 255KB,并存放在一个 Document 中。 GridFS 使用了 2 个 Collection 来分别存放文件 Chunk 和文件元数据。如图8所示:
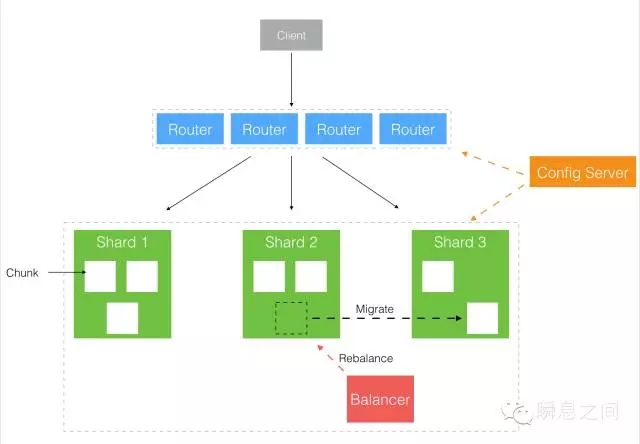
图8 单机的容量总是受限于磁盘大小,而 MongoDB 解决方案依然是分片化。 是用更多的机器来提供更大的容量,分片集群采用代理模式(《Redis 集群的合纵与连横》一文中写过这类模式),如图9所示。
图9 而每个分片上的数据又以 Chunk 的形式组织(类似于 Redis Cluster 的 Slot 概念),以便于集群内部的数据迁移和再平衡。 比较容易混淆的是这里的 Chunk 不是前面 GridFS 里提到的 Chunk,它们的关系大概如下图所示:
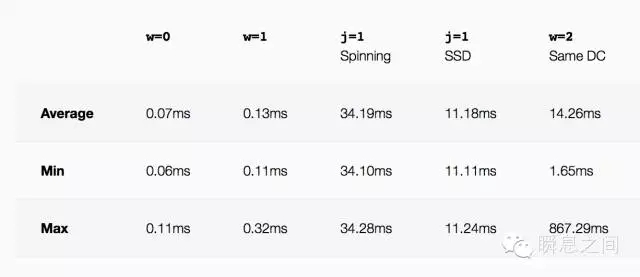
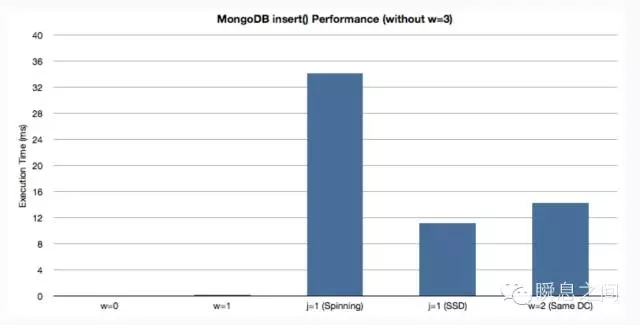
图10 支持水平扩展和数据再平衡功能的 MongoDB Cluster 基本上数据容量就不再是个问题了。 四、效率 前面「安全」一节列举了不同的写入模式,我们看下在这些不同模式下写入的效率如何。 因为官方没有提供基准性能测试数据,下面的数据来自参考文献[5]一个从 2009 年开始使用 MongoDB 的专业技术公司博客分享的写入基准测试数据。 我这里根据数据结果做一些分析总结,下图是测试结果数据的表格与图形展示。
图11
图12 w=0, Write To Buffer Without ACK w=1, Write To Buffer With ACK j=1, Write To Journaling With ACK w=2, Write To Replica Buffer With ACK 测试类型多了一项将 Journaling 日志放在 SSD 和机械硬盘上的差异,这让我们可以直观的感受 SSD 和机械硬盘在顺序写情况下的性能差异。 对于机械硬盘最大的性能制约是在磁头移动,所以 MongoDB 官方文档也建议将 Journaling 日志和数据文件放在不同的磁盘上。 保证顺序写 Journaling 日志的磁头不会被随机写数据文件影响,而数据文件的写入是通过内存 buffer 缓冲的一个异步过程,对交互性能延迟的影响不大。 我们从测试结果数据看,有无 Ack 之间响应延时相差一倍,基本就是多了一个网络传输的延时等待时间。 开启 Journaling 保证及时落盘,不论是 SSD 还是机械硬盘,这个延时都上升了 2 个数量级,翻了百倍,而 SSD 的顺序写比机械硬盘平均快 3 倍。 而写双副本的平均延时比我预期高了不少,应该说延时的波动很大,不像写磁盘延时最小、最大和平均的值非常接近。 理论上写双副本不落盘的情况延时只应该比单一情况多一倍的网络开销外加部份程序开销,而实际测试数据显示远远高于预期而且延时波动范围大了很多。 这种模式下 MongoDB 延时表现波动范围太大,不够稳定,具体到底是实现上的缺陷还是测试不够准确,就不得而知。 而且当时测试的版本是 2.4.1 不知道最新的 3.2 版本如何,若采用这类写模式,可模拟自己生产环境实测得出结论。 至于读取性能是没法做基准测试了,不同的文档模型,选择不同的查询条件,性能都可能不同。 虽然 MongoDB 是 Schemaless 的,但不意味着不需要对文档的 Schema 进行设计,不同的 Schema 设计对性能的影响还是很大的。 五、总结 面临一个新的技术产品或系统,「形态」是针对这个产品或系统最独特部分的描述,属于核心模型。 而「安全」、「容量」、「效率」三个核心维度全面反应了一个技术产品或系统的不同设计和实现考虑,可类于比机械设计中的「三视图」。 对于初次面对一个新的技术产品或系统,这是一个适合的切入点来帮助做初步的技术决策,然后跟着进一步的实践测试来验证思考和理解, 这样才能更好的理解与用好现有技术,做一个合格的技术拿来主义者。 六、参考 [1]. MongoDB Doc. [MongoDB Manual](https://docs.mongodb.org/manual/) [2]. MongoDB White Paper. [MongoDB Architecture Guide](http://s3.amazonaws.com/info-mongodb-com/MongoDB_Architecture_Guide.pdf) [3]. 陈皓. [千万别用MongoDB?真的吗?](http://coolshell.cn/articles/5826.html). 2011.11 [4]. David Mytton. [Does everyone hate MongoDB?](https://blog.serverdensity.com/does-everyone-hate-mongodb/). 2012.09 [5]. David Mytton. [MongoDB Benchmarks](https://blog.serverdensity.com/mongodb-benchmarks/). 2012.08 [6]. David Mytton. [MongoDB Schema Design Pitfalls](https://blog.serverdensity.com/mongodb-schema-design-pitfalls/). 2013.02 上一条: NoSQL系列文章之MongoDB 下一条: Mongodb与Mysql的优缺点
|






 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved