 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
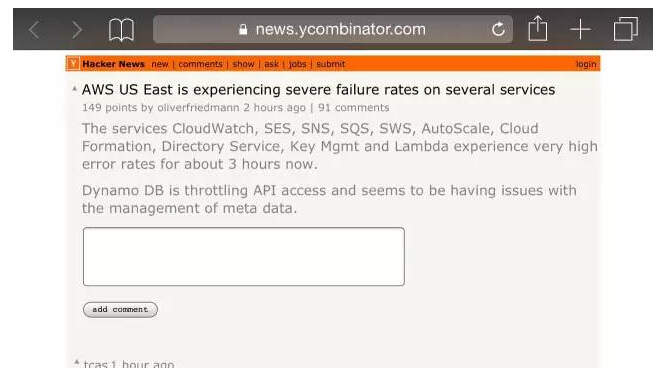
 AWS美国东部地区服务遭遇严重故障
发布日期:2016-2-6 17:2:12
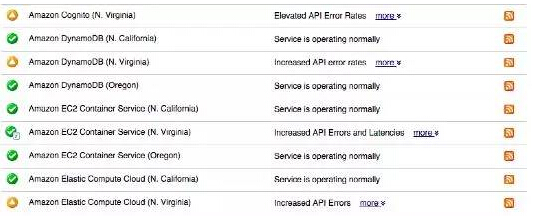
CloudWatch、SES、SNS、SQS、SWS、AutoScale、Cloud Formation、Directory Service、密钥管理和Lambda这些服务出现了很高的错误率。 最新消息:截至美国东部时间9月20日中午11:50,大多数服务似乎已经恢复如初,AWS服务仪表板显示上面全是绿色。 Dynamo DB在限制API的访问,似乎在管理元数据方面遇到了问题。 主要问题似乎出在DynamoDB上 来自状态页面的一份内容如下所示: 3:00 AM PDT 我们调查美国东部1区API请求错误率增加的现象。 3:26 AM PDT 我们继续看到在美国东部1区,DynamoDB中所有API调用的错误率增加。我们在积极主动地竭力解决问题。 4:05 AM PDT 我们发现了问题的根源。我们在竭力恢复正常。 4:41 AM PDT 我们继续竭力解决引起美国东部1区DynamoDB API错误率增加的问题,希望恢复正常。 4:52 AM PDT 我们想为你们提供出现的问题方面的更多信息。根源出在我们在DynamoDB里面的一部分元数据服务。这是一种内部子服务,负责管理表和分区信息。我们的恢复工作现在致力于恢复元数据操作。我们在竭力恢复正常的过程中,会限制API。 5:22 AM PDT 我们可以证实,我们在继续致力于恢复正常的过程中,现在限制了API。 5:42 AM PDT 我们看到元数据服务日益稳定,我们继续努力争取尽早可以开始消除限制。 亚马逊AWS DynamoDB出现停运,殃及Netflix、Reddit、Medium及更多服务 早上好!不知各位有没有注意到手机上的应用程序没法正常使用?也许没法使用Netflix? 那是因为在过去的几个小时,亚马逊网络服务(AWS)遇到了一次大范围的服务停运事件。 这起事件已影响了Netflix、Product Hunt、Nest、Reddit、Medium、IMDB、Social Flow以及亚马逊自家的Alexa和Instant Video服务,覆盖北美东部地区的用户。 罪魁祸首似乎是亚马逊位于弗吉尼亚州北部的DynamoDB系统。 屏幕截图如下所示: 我们VentureBeat网站使用SocialFlow自动发布社交媒体帖子。你也许已经注意到,我们社交媒体流中的链接点击后打开的却是503出错页面。希望亚马逊尽早解决这个问题。 这对亚马逊来说可能会是一次代价惨重的失误。早在2013年,一起类似的停运事件就让亚马逊损失惨重:每秒估计损失1100美元。 摊上了网络服务故障这档事,不妨走到外面,躺在草地上,想想脆弱的计算机系统对我们的整个现代生活带来的连锁效应。 上一条: 从云用户小豆的顾虑解读公有云安全策略 下一条: 云端数据可视化管理的五项最佳实践介绍
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved