 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 怎样基于公有云打造TB级文件备份保护系统(1)
发布日期:2016-2-5 15:2:35
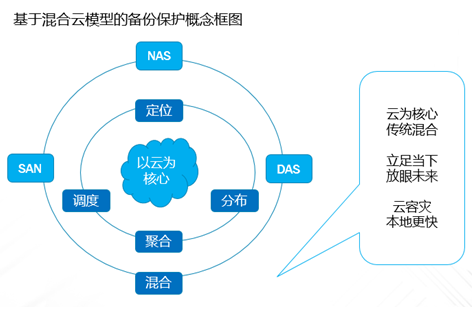
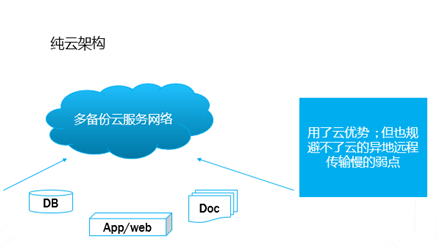
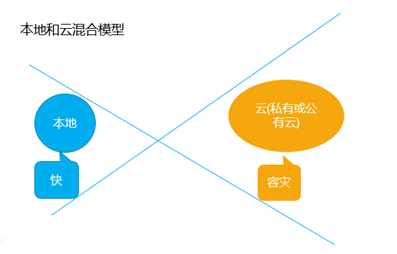
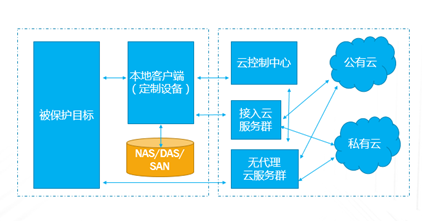
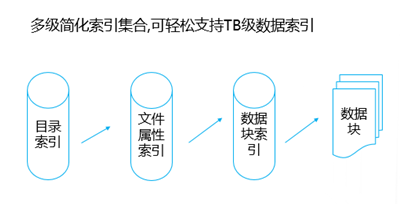
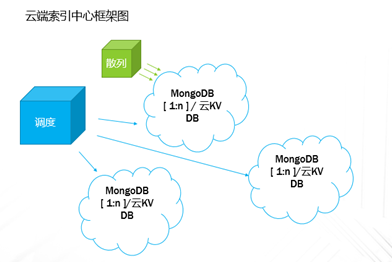
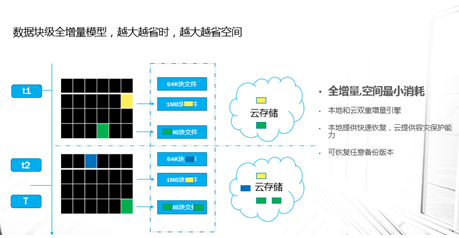
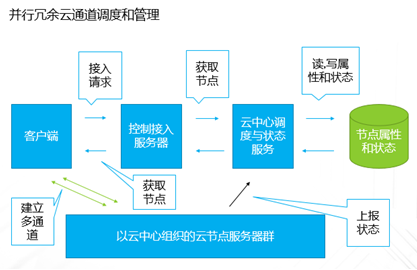
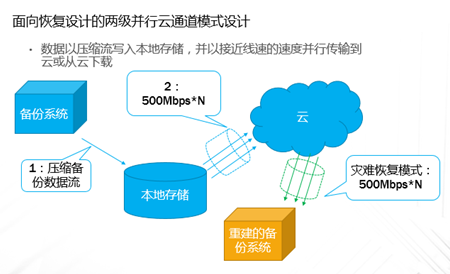
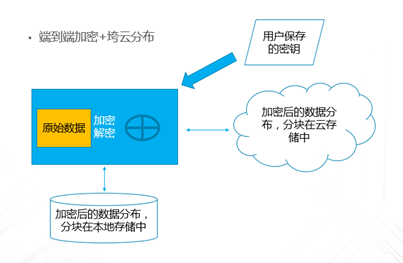
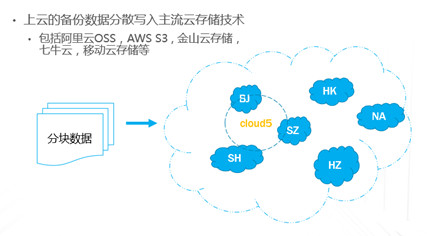
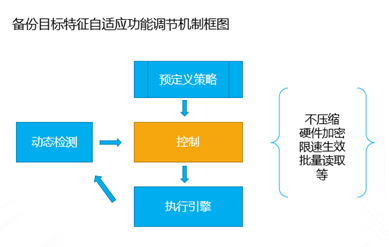
企业业务稍微上点规模的,IT系统产生的数据很容易就超过TB级,并且资料文档等很容易超过亿级别的规模,如果用手动复制的方案来备份,基本是非常困难的;这种情况下,即使购买一些专业系统,随着数据量日益增大,跑起来也非常吃力。本文重点讨论怎样基于云平台,来实现对应的解决方案。 TB级海量文件场景特点 文件规模大,动作上千万级规模 文件目录结构多,层次多 文件大小从KB 到MB,GB,甚至百GB级别分布 文件变化快,或者有批量增加的场景 无用的,有用的,混在一起 时间分布久,跨度大 文件类型文本,视频,图片,压缩等都有 单个节点的数据量上TB级 总量上TB级,但分布在多个节点 面对如此特点,如果按照目前的设备+软件方案,在以下几点有非常大的缺陷: 1、 一次投入特别的贵,如果对原始TB级数据做专业备份保护,投入得数十万,具体到不同的行业,性能和保护窗口参数稍微提升,投入立即上升到百万级。 2、升级扩展复杂,预先估计容量,后续扩展起来相当麻烦,必须的改变存储策略,或重新离线做数据迁移分布。如果初始购买的存储扩展有限,后期还不能很好的升级扩展。 3、3-5年左右的生命周期,也就是说,数据经过几年后,改造升级,购买新的方案是必须的,这样当数据上到百TB级别,整个工程实施也是相当复杂了。 随着数据量的增长,超过一个量级,比如10TB级别,其实这类方案已难于胜任了。 破解思路 基本上来说,要破解海量数量,以及TB级增长的难题,基于云(如阿里云)的方案是目前最有前途的思路,云有4个核心好处: 1.存储和计算能力按需扩展 2.可靠,云(如阿里云)的计算和存储分布特点,使得系统在计算和存储都具备传统结构不具备的数倍的可靠性 3.安全,基础云服务商自身在安全方面不计成本,比起自己构建IT设施,来得更加专业 4.扩展,开放性更好,使得构建的服务,更容易外部系统对接 目前在国内以及全球其他地区,都有成熟的云平台可以作为构建基础。当然,除了明显的优点外,也有1个缺点是,云毕竟在异地,速度方面没有本地来得快,所以在设计系统的时候,要充分考虑到此处特点。以此为基础,考虑构思如下备份系统的设计目标: 最高性价比的TB级海量小文件备份服务 支持分布式,多节点集中管理监控 备份容易且快速恢复 结合云平台的优缺点,基本的设计思路大体如下: 规模上量:单点TB突破,分布式上量 最小空间占用:最大化变小数据 平衡性能开销:IO扫描和效益平衡 不做无用功:特征类型自适应处理 最近最快,最远最可靠:多级模式结合,平衡速度和可靠性 以下将围绕以上5个点展开,看一个专业级别的备份保护系统如何打造。 TB级突破 实现TB级突破,重点思路在于怎样解决备份和恢复的速度,以及海量规模的数据块存储。而解决数据备份和恢复速度的关键在于组织好数据索引;我们日常看到的网盘备份是简单的同步模型,很难胜任连续的数据块版本影射关系。而一个专业的备份系统,此处是必须要解决好。 架构上要突破纯云的方案,本地和云结合 纯云的方案,用了云(如阿里云)的几个优势点,但也同时受云天生异地的特点影响,在传输效率方面是必定落后本地的方案,在强调速度的备份和恢复场景下,只有压缩数据,加大带宽。因此,更好的专业级方案是兼顾云和本地的优势进行设计。 以下黄色部分,就是加的一层本地存储;本地客户端将以分块的形式把数据写入本地客户端,同时启动同步逻辑,把数据从本地同步到云存储。 TB级数据重点在索引管理上要下功夫,索引分为本地和云端两级 本地索引采用分段分布设计,突破传统RDB单库数量过大,查询过慢的瓶颈。本地索引模型读写相对简单,可以采用自己研发或开源的本地数据存储方案,Sparkey, levelDB,BDB,甚至MongoDB等都可以,实现索引库理论支持TB级以上的的索引大小,具体到文件为每条索引可做到100字节以内 索引容量: TB/0.1KB > 100亿条索引 按照简单的顺序存取模型,海量的目录,文件索引,这种分级模型的索引框架,可以轻松解决TB级数据与海量小文件场景的管理。 当然,如果离开了异地配合,这种方案还是不完整的。因此在云上,要支持更大规模的索引容器。幸运的是,在云上,我们可以选择的方案还比较多。可以基于MongoDB,LevelDB等优秀的列模型数据库,也可以基于云平台本身的分布式KV数据库来保存索引。 设备通过调度中心定位到云索引中心 ; 单个云索引中心采用NO-SQL DB分布式设计,具体按照任务ID进行分布。关于具体的索引容器,可以选择云平台提供的KV数据库,如果要更多灵活的控制,也可以自己选用专业的KV 数据库来构建。理论上云端可以管理索引的数量无限。 数据按系列段分块存储,提升混合云模型的速度参数 普通的量级数据读写,无所谓要不要分块了,但一旦规模上到TB级别,特别在文件量变化快的场景,要尽可能缩短备份窗口,必要的数据存储组织就显得非常的关键。其数据存储分为两部分,本地和云。 本地数据存储设计,可采用N *KB – N *MB 相对固定系列段的分块设计,兼顾读写效率与空间平衡分块采用期望分块方案,尽可能让分块分布在1个区间,保证去重效果的同时,减低分块对索引记录数占用的数量。本文按照64KB 到 4MB的经验值方案来计算. 总可索引数据量区间:理论最小管理数据 100亿* 64KB = 600+TB , 理论最大管理数据 100亿* 4MB = 40+ PB 这么大的规模,理论上已经远远满足数据存储管理需要。 对于数据上云,初始化系统这里可以把设备定位到不同的云数据中心,与索引位于同1个中心内;上传的数据异步化存储到云存储,或可同时异步到特定的块存储设备;对于块存储,提供合并机制,将小块进行合并存储,提高存储读写效率。所以,理论上云端冗余管理的数据量受限于云存储空间提供商的。 本地和云的数据存储组织方案,在本地通过相对分块序列的方案,在云采用云存储的方案,从KB-MB级的小数据块文件都可以轻松管理起来。 上图是基于索引和块存储结合的增量应用。任何一个数据块的变化都会第一时间,通过本地的索引块签名快速判断是否需要上传备份 ; 如果本地的索引无法启动,将从云端获取签名进行比对。任何一个需要备份的数据块,可以快速通过分块序列存储方案,保存在对应的数据块文件中。 通过并行冗余通道,提升上下云的速度、稳定和可靠性 互联网络本身是一个质量无法端到端保证的的一个网络,传输的稳定性会又多个环节影响。包括运营商网络,平台的网络,以及用户接入的网络等。对于一个专业级的备份系统,必须要考虑网络通道的连续、稳定运行。 以上,在任何一次客户端注册期间,一旦认证通过后,可以根据系统资源情况,分配合适的数据节点给客户端。 客户端可以根据情况,正常情况下,多通道并行传送 ; 一旦检测到通道出现问题,自动摘除 ;各个节点会上报数据到调度中心; 同时当链路恢复的时候,自动接入到系统中。下图就是示意多通道在同步到云,以及从云恢复或下载数据。 采用端到端加密数据块设计,结合数据块垮云分布机制,可靠保存备份到本地和云的数据 在备份体系中,数据保密性设计不依赖于人,从机制上保证数据备份到云是机密的。最常用的一种方案就是采用对称加密,具体可以采用AES,3DES 等算法。目前比较常用AES256位,而key的产生可以在客户端产生。Key一旦丢失,数据将无法恢复和使用。因此key的妥善保护,也是非常重要。 在基于块的加密设计中,结合云分布特征,数据被打散在不同的存储位置,因此在数据安全方面进一步增加了强度。基于目前的公有云平台的情况,在国内和国外都有几大主流的云存储平台,分布在全球。理论上,数据可以分步在任何一个地方。唯一考虑的是数据如何跨地区进行同步和分布; 当然这里可以先写入本地云中心,冗余块通过高速通道,再同步其他云中心,这里可以是同构的云,也可以是异构的云。 引入自动适应方案,提升海量文件和应用场景的适应能力 在海量文件情况下,由几种系统因素影响备份的效率和资源开销。备份系统如果全速开进,会消耗过多的计算和IO资源,如果是生产系统,势必也会带来冲突。以下是几种典型的需要规避的: 压缩比例和CPU消耗的冲突 磁盘IO和小文件随机分布的冲突 强加密和CPU需求的冲突 实时检测和系统资源的冲突 文件类型和压缩效果的冲突 备份带宽消耗 通过对带宽,压缩算法,文件类型定义等预定义策略,可以快速平衡好系统资源。这种适合在确定判断系统场景的情况启用。 对于无法预知的情况,启动自动监测机制,包括压缩比,是否硬件加密加速,是否需要启动实时或批量扫描等。 总结与展望: 随着云平台的成熟和发展,网络基础设施日益完善,用云构建的数据备份系统,可以充分利用天然的地区分布,运维简单,灵活扩展特点,以及弹性按需投入的优势,企业数据走向云端简单更加简单可行。 上一条: 保护Docker容器须知 下一条: OpenStack安全问题:缺乏自卫武器
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved