 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Netflix数据管道
发布日期:2016-4-6 18:4:13
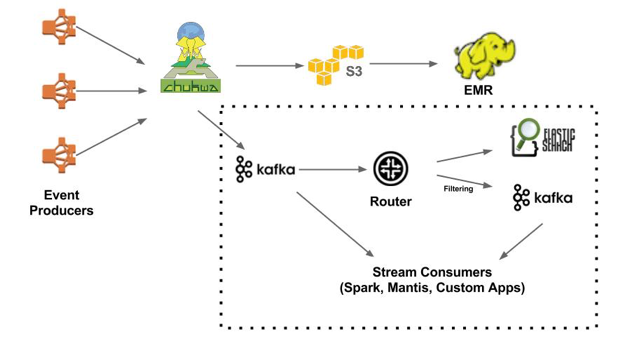
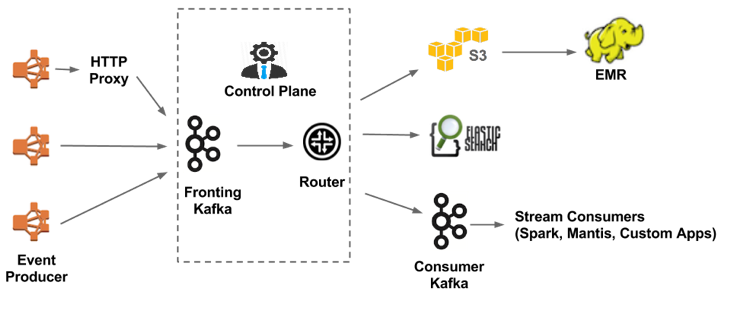
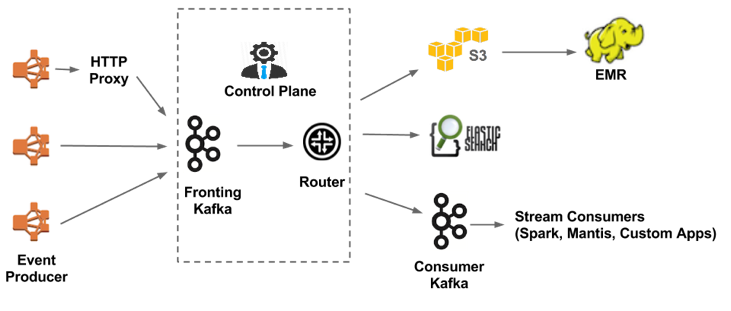
Netflix数据管道 去年12月Keystone数据管道正式投入使用,本文我们就来讲讲这些年Netflix数据管道的变化历程。 Netflix的中心是数据,很多的商业决策和产品设计做出的决定都是依据数据分析。在Netflix,数据管道的目的是对数据进行收集归纳和处理,我们所有的应用几乎都会用到数据管道。下面我们先来看看有关Netflix数据管道的一些统计数据: 1.每天约5000亿个事件,1.3PB的数据 2.高峰时段约每秒800万个事件,24GB数据 由于我们用另外的Atlas系统来管理运营相关的数据所以它没有出现在上面的列表中。 需求的变化和技术的进步,使得过去几年我们的数据管道发生了很大的改变。下面我们就来介绍一下。 一、Chukwa数据管道 数据管道最初唯一的目的就是把事件信息上传到Hadoop/Hive。如图1中所示,整个架构是比较简单的。Chukwa收集事件信息并将sequencefile写入亚马逊S3,后面大数据平台部门会进一步处理并写入Hive。从事件发生到以Parquet格式写入Hive这整个过程不超过十分钟,对于每小时甚至每天才运行一次的batch job来说,这已经足够了。 图1 二、能够进行实时处理的Chukwa数据管道 随着Kafka和Elasticsearch等技术的发展,公司内部对于实时分析的需求也越加强烈,我们必须保证处理所需时间在一分钟之内。 图2 除了将数据写入S3,Chukwa还可以将数据发送到Kafka,新的实时分支(虚线框住的部分)处理的事件大约占总事件的30%。处于实时处理分支中心位置的是事件路由模块,它负责将数据从Kafka传递到Elasticsearch和下一级Kafka(进行数据的筛选)。终端用户可以自由选择自己趁手的工具进行分析,比如Mantis、Spark或者其他定制工具。 Elasticsearch在Netflix的应用过去两年经历了爆炸式的发展,现在共有约150个集群和约3500个节点,总数据量约为1.3PB,这其中大部分数据都是通过我们的数据管道采集处理的。 数据路由的部分是由我所在的小组管理的,下面是一些我们碰到过的问题: Kafka high level consumer会丧失消息分区的所有权并停止读取一些分区,唯一的解决办法是重启。 有时部署代码之后high level consumer在rebalance时会出错。 我们有几十个集群用于事件路由,运营上的开销正持续增长,所以对于路由job的管理还要想个更好的办法。 三、Keystone数据管道 我们决心对一中的数据管道进行调整是基于下面三个方面的考量。 1.简化架构。 2.提升系统可靠性(Chukwa不支持冗余)。 3.Kafka社区较活跃后劲足。 图3 架构中一共有三部分主要的模块: 1.数据收集-有两种方式。 直接写入Kafka。 通过HTTP代理写入Kafka。 2.数据缓存-使用Kafka来实现持久化消息队列。 3.数据路由-与V1.5中作用相同。 Keystone数据管道已经在生产环境中平稳运行了几个月,我们还会在进行质量、扩展性、可用性和自动化方面的提升。 上一条: 大数据的几个极佳用例 下一条: 大屏数据可视化设计
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved