 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 微软发布Azure数据工厂说明
发布日期:2016-3-21 22:3:19
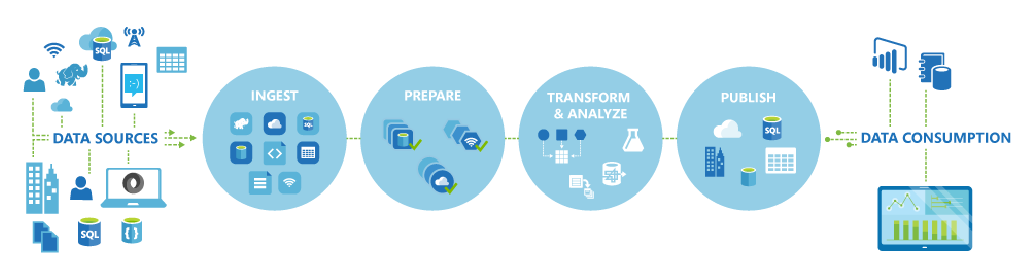
微软发布Azure数据工厂说明 那些以数据为重心的云提供商正在试图使其设施中的数据收集和存储变得更加容易。为了使云端和本地设备间的数据移动更加方便,微软近期发布了ADF,就是Azure数据工厂(Azure Data Factory)的通用版本。但是,这项按次付费的业务并没有作为专业的ETL(Extract Transform Load)工具出现,而是定位成微软分析套件的一个组成部分。 在2015年8月的早些时候微软的一篇机器学习的博客中,微软的副总裁Joseph Sirosh描述了ADF并且阐述了这项业务所带来的益处。 通过使用ADF,现有的数据处理服务可以被编排成数据管道(data pipeline),然后就可以在云端获得高的可用性并被管理。这些数据管道就可以被调度以用于数据注入、准备、变换、分析和发布的场景了,并且ADF还会对所有的复杂数据和处理中的依赖项进行管理和编排,从而不需要人工干预。ADF实现方案可以迅速创建并且部署到云端,它就可以连接越来越多的本地和云端数据源。 通过使用ADF,你的业务可以充分的享用完全可管理的云服务的好处,并不需要购买任何硬件;利用自动化的云资源管理可以减少成本;如果使用全球化部署的数据传输设施,你还可以高效地移动数据。可以方便的监控和管理复杂的调度计划和数据依赖,所有这些都通过一个提供监控管理功能的直观的人机界面来实现,通过Azure门户你就可以访问它了。最后开发者还可以通过熟悉的Visual Studio插件快速地完成方案创建和部署了。 ADF通过由活动编排而成的管道来处理数据集。数据集(dataset)描述了给定数据存储中的数据结构,ADF提供了很多数据存储的连接器,其中包括Azure DocumentDB、Azure SQL、本地SQL Server、本地Oracle数据库、本地Teradata数据库、本地MySQL数据库等等。ADF中的活动(activities)在给定的数据集上执行操作,操作可能是进行数据移动的,也可能是完成数据转换。数据移动活动负责在数据端点间传送数据,比如从数据存储中拷贝数据。数据转换活动获取原始数据并对其执行查询,ADF中有七个可用的转换活动,它们中的大部分依赖基于Hadoop的Azure HDInsight 服务,包括: Hive:在HDInsight 集群上执行类SQL的Hive查询。 Pig:在HDInsight 集群上执行Pig查询。 Stored Procedure:执行SQL Azure数据库中的存储过程。 .NET:使用C#语言定义的定制的活动。 Hadoop Streaming:执行流作业。 MapReduce:运行MapReduce程序。 Maching Learning Batch Scoring:使用Azure机器学习web服务。 为了访问本地端点,ADF使用了被称为数据管理网关的工具。网关运行在本地的windows服务器上,然后使用加密的证书作为凭证来访问本地的数据存储。外发的请求都在标准的HTTP端口上完成。网关实例是和特定的数据工厂绑定的,并且网关实例也只能运行在给定的服务器上。所以,如果用户需要使用多个数据工厂服务,那么他们就需要使用一组服务器并在上面运行相应的网关。为了创建数据工厂,开发者可以使用Azure Portal(beta版本)、PowerShell、Visual Studio或者REST API。 ADF是微软在7月发布的Cortana分析套件的一部分。套件中的其它产品包括Azure Data Catalog、HDInsight、Power BI、Azure Machine Learning和Azure Stream Analytics。微软是如何计划将这些独立的服务集成到单独的套件中呢?在ZDNet关于ADF的文章中,Andrew Brust解释了这个封装和集成是如何工作的。 ADF通用版本定于“2015年秋季的晚些时候”发布,并且承诺为所有Azure Big Data和分析服务使用者提供单独的认购,相关价格也会在秋天发布。 微软还承诺为使用Cortana Analytics的客户带来更多的、集成的业界垂直解决方案。它们是些基本的用例模板和加速器,为包括制造、医疗保健和金融服务业在内的那些领域提供帮助。就其本身来说可能它们还不是非常成熟的产品,当然也肯定无法组成真正的一体化服务,但它们仍然可以作为经典的案例,为如何一起使用这些服务提供帮助。 一些特定的服务已经完成了点到点的集成。比如说,Azure Data Factory已经可以连接到Azure Stream Analytics,而后者也已经可以连接到Event Hubs。Power BI也知道如何同运行在HDInsight上的Apache Spark进行交互。而Azure Data Lake则仿真了HDFS(Hadoop的分布式文件系统),它支持与Power BI中Power Query组件的原生连接。Azure SQL Data Warehouse使用了微软PolyBase的技术作为其特性,这种技术也集成到HDInsight和其它Hadoop发行版本中。 微软看起来并不想将ADF服务作为传统的(云使能)ETL产品,就像Informatica和SnapLogic那样。虽然ADF也可以执行一些类似的注入和转换功能,但它看起来主要定位在分析场景和从不相干的数据集中获取洞察。ADF的定价 基于其管道中的活动,而且根据活动发生频率是否频繁,活动是在云端还是在本地端点运行,收费也会有很大的不同。用户为数据移动支付的费用是以小时为基础的,而没有激活的管道只会有名义上的计费并没有实际的支出。
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved