 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 小米HBase服务化实践
发布日期:2016-3-10 0:3:39
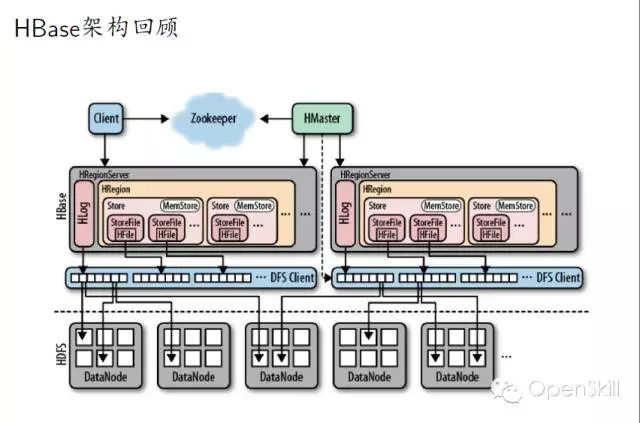
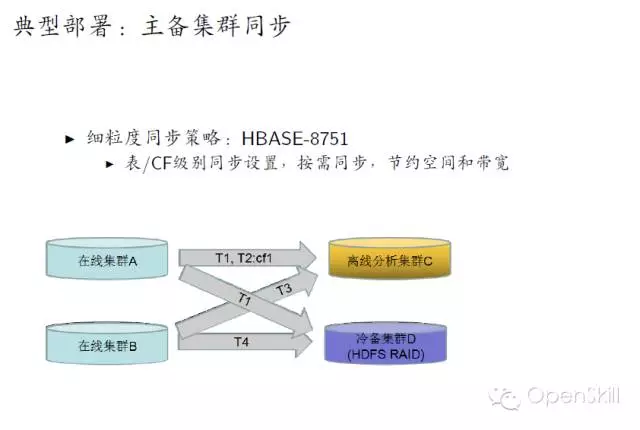
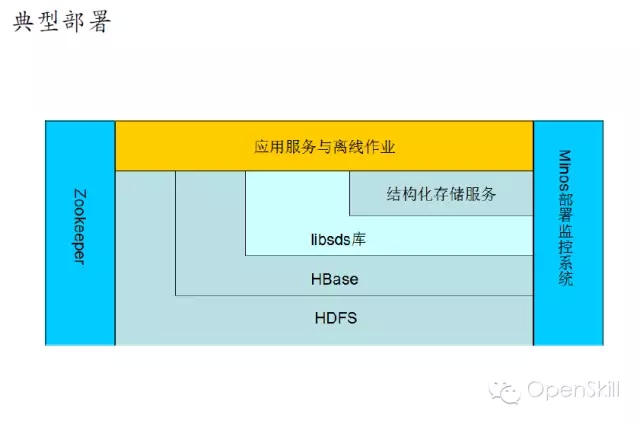
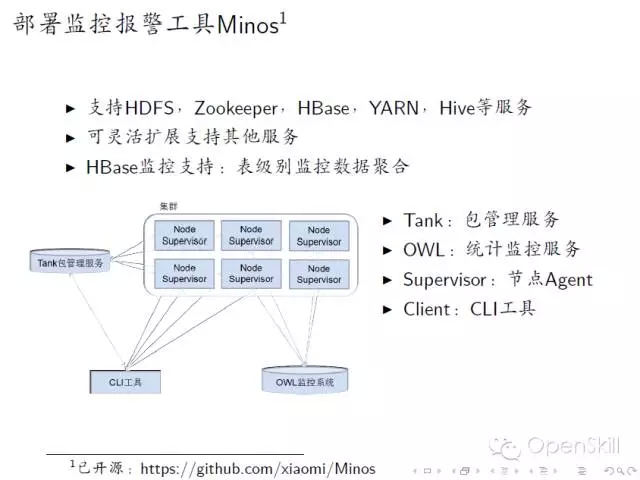
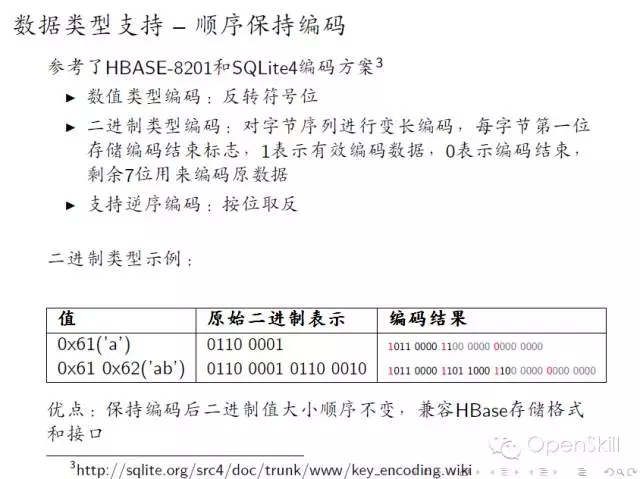
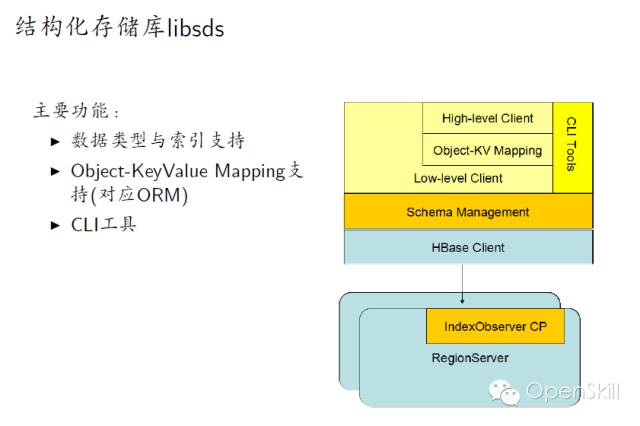
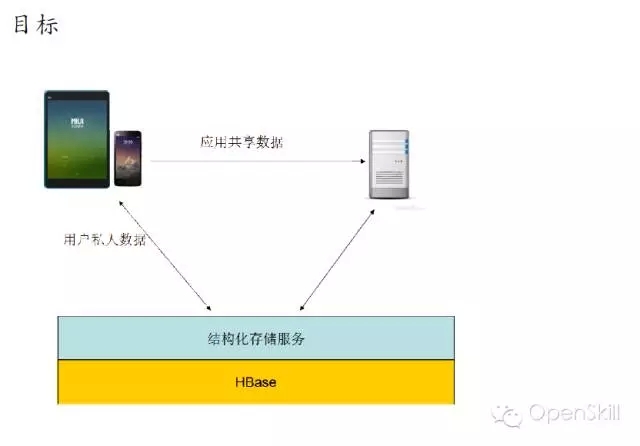
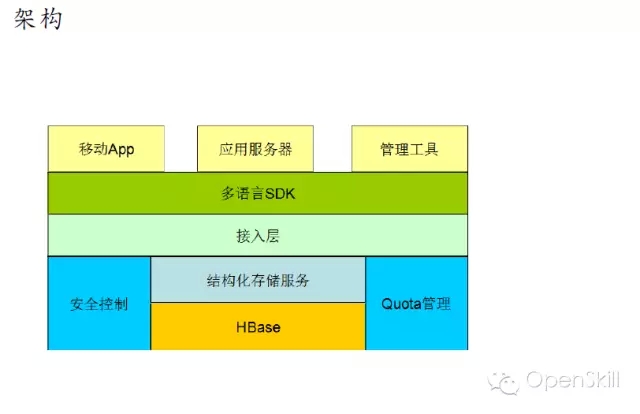
小米HBase服务化实践 我们今天主要分享一下我们在使用HBase过程中遇到的一些问题,以及我们的一些实战经验。 首先我们回顾一下HBase的架构,HBase是基于谷歌的Bigtable论文,它主要是由HMaster和Regionserver这两个组件组成。它底层的数据存储在HDFS上边,Zookeeper负责各个组建之间的协调工作。 然后讲一下HBase在小米的应用现状,HBase在小米主要是用在OLTP的场合,以及相关的一些离线分析,典型的应用包括小米云服务,包括大家常用的通话记录、短信、云相册等。这些服务的结构化数据存储在HBase上面。第二个应用就是小米消息推送服务,主要是面向移动应用开发者。其他还有多看阅读以及小米各种设备的数据。 这是现在的一个应用规模,我们现在大概有10多个在线集群5个离线集群还有若干个测试集群,分布在5个数据中心,目前有几百台机器,典型的数据结点是12*2T配制,目前服务了公司内外的数十个业务,最大集群QPS大概在的百万级别。 这是我们一个典型的部署情况,在线集群主要服务线上业务,然后它的数据通过日志的方式,同步到离线集群和冷备集群,其中离线集群是用来做一些离线的分析。冷被集群主要考虑到数据安全,所以我们做了一个数据的备份。考虑到存储成本我们是采用了HDFS RAID,这样可以大大减少存储上面的成本,目前RAID的配制是6+3。同时我们增加了细粒度的同步设置支持,这样可以支持表级别和CF级别同步设置,这样只需要同步必要的一些数据,节省空间和带宽成本。 这是我们一个典型的部署,除了Zookeeper、HBase、HDFS这三个必备的模块之外,我们还在HBase原生接口基础上,开发了结构化存储库libsds,以及结构化存储服务。除此之外,我们还开发的自己的部署运营系统Minos,接下来我会分别介绍一下这三方面的工作。 在前面百度马老师也吐槽了Hadoop,Hadoop的默认部署是非常难用的,不太适合大规模的生产环境。我们就开发了我们自己的Hadoop集群管理系统,可以实现Hadoop系列软件的部署与管理。Minos内建监控的支持,对于HBase我们增加了一些表级别的监控数据的聚合。这是Minos的一个整体架构,主要包含了四个组件,包管理服务,统计监控服务、结点上面的Agent负责进程的生命周期管理,配制管理等,以及运维工具,目前这个项目已经开源,如果大家有兴趣,可以在Github上面下载试用。 这是我们的一个上线的流程,我们发布新版本的时候,大概经过单元测试、压力测试和Staging集群的测试。除了3个测试之外,我们还有Longhaul测试和Failover测试,这样可以帮助我们尽快发现问题。 除此以外我们还做了一些其他的辅助工作,包括HBase的Nameservice支持,Snapshot管理,HBase错误日志统计分析,Kerberos帐号管理等工具。 这是我们遇到一些典型故障,首先最常见的是坏盘,这是个问题是在HDFS层面解决。 第二个问题是相对影响比较大的,就是慢盘的问题,我们在HDFS层面开发了一个叫Hedged Read的特性,就是在第一次读取超时的时候,同时向第二个Datanode发请求,从而降低整个请求的延时。 第三个就是用JVM问题,HBase、HDFS这些都是里Java实现的,所以说GC问题是难以避免的,我们主要是做两方面个工作,一个是调节JVM参数,另外一个就是我们在采用单机多实例的部署方式,这样就是减少JVM堆的大小,这样可以缓解GC的影响。 第四个问题是程序Bug,在我们使用的过程中,也遇到过一些包括(Zookeeper、HBase、HDFS)的Bug,这个是比较难避免的。所以我们做了两方面工作,一个是可用性监控,另外一个就是刚才提到的错误日志的统计分析,这样我们可以尽早的发现一些异常的情况,然后去排查。最后一类问题节是网络故障,网络故障发生的比较少,但是影响比较严重,会导致集群整体宕机,需要重视。 接下来我讲一下我们在开发工具方面所做的一些工作。 首先小米这边的数据模型相对来说是比较统一的,因为它有两个特点,一个是它的数据是由底大量的独立用户产生,另外一个就是业务一般就是需要在用户实体范围内支持跨行原子性和二级索引。同时一般没有全局事务和全局索引的需求。对上面的特点我们对HBase做了两个改进,一个就是基于正则表达式的前缀分割策略,这样就能保证相同前缀向记录能够分在同一个Region上。第二个改进就是实现Region内部的跨行原子性的支持,对于batch操作,保证修改在同一条WALEdit落地,并按照Rowkey顺序加锁的方式保证原子性。顺序加锁能够避免死锁的问题。 最开始我们的应用都是通过HBase原生Client来开发的,在这当中也遇到了一些问题,就比如说学习成本,还有就是用户需要自己实现数据类型,实现的时候,会有一些额外的开销。另外是从客户端实现索引,通过checkndPut这种方式,开销比较大,另外实现起来也比较复杂,功能也不是完备。最后最重要的一点,业务层的代码大量冗余,这样一方面开发效率低,另一方面很难保证代码质量。我们解决的方案就是,在HBase Client基础上开发了一个结构化存储库,提供了内建的数据类型支持和局部二级索引支持(Region内部)。 我们提供了三种索引,第一种是Eager索引,这种索引在更新和删除数据的时候,就清除失效索引,读取时无需额外操作,索引一定是有效的。第二种是Lazy索引,这种索引在读取的时候判断是不是有效的,在数据更新时不做额外操作。第三种Immutable索引是结合了上面两种索引特点,适合只读性数据一次性写入的情景,这样读取和写入都没有额外的开销。 接下来就简单介绍一下数据类型的支持。我们参考了HBase的实现和SQLite的编码方案,对于数值类型,采取符号位反转方案,对于二进制类型,采取的方案是,由8比特编码转换成7比特变长编码,最高位为标志位。1表示是否是有效的编码数据,0表述编码结束。同时编码方案还支持逆序编码,采用的方案是按位取反,可用于逆序索引等场合。这种编码方案的优点就是保持编码后的二进制数据,跟原来的值大小关系是不变的,这样可以兼容HBase的存储格式和访问接口。 这是libsds的整体结构。其中索引通过HBase的Coprocessor来实现。除基本的访问接口之外,还提供了 Object-KeyValue Mapping,可实现业务层Java对象到HBase KeyValue的自动映射。下面的例子演示了通过libsds Annotation方式定义Schema和访问数据的方式。 我们通过这个例子可以看到,业务层做开发的时候,需要写的代码是非常少的,所以无论是开发效率,还是开发质量上来讲,都可以得到很好的保证。 最后一个我简单介绍一下小米开放平台,我们前面讲了,就是我们前面讲了两种使用方式,一种是使用HBase原生Client,另一种是使用libsds。存在一些问题,第一Zookeeper,Kerberos等环境配置比较复杂,第二是只支持Java语言(HBase的Thrift跨语言方案不是特别完备)。第三点,小米的应用大多数都是移动的应用,目前的一个趋势是手机端App直接访问后端通用数据服务,免去后端业务层服务器的开发。基于这些考虑,我们就在HBase的基础上,提供的结构化存储存储服务。 这是整体的一个架构,架构也是非常简单的,在HBase以上,提供了安全控制和Quota管理模块,在这之上是接入层以及多语言SDK。目前已经接入了一些业务,包括MIUI的部分应用,小米智能家居设备的数据,小米手环等生态链公司的数据,目前可以在小米开放平台试用。我今天就讲这些,看大家有什么问题。 主持人:感谢何亮亮精彩的发言,我们看一下大家提到了哪些问题。首先看第一个问题,第一个问题,HBase的libsds是开源了吗? 何亮亮:这个没有开源,但是如果有人有兴趣可以考虑,但是目前来看就是因为有一些内部的依赖可能我们需要一些工作。 主持人:第二问题是讲一讲小米通过HBase实现二级索引的方案以及遇到的问题。 何亮亮:其实这个本身没有什么特别困难的地方,因为我们实现的是Region内部的二级索引,不涉及CAP问题。 下一条: 377秒是如何炼成的,阿里云破纪录的背后
|















 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved