 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 魅族云同步的实践-协议与架构说明
发布日期:2016-1-28 22:1:51
魅族云同步的实践-协议与架构说明 背景说明: 这里所说的云同步,是指魅族的业务背景下,在移动应用场景中,经同步服务把数据保持多端一致的服务。它提供了如联系人、便笺、信息、通话记录、日历、文件等类型的数据同步功能,由移动设备上的客户端和云端组成。 魅族云同步于2008年开始使用,目前服务千万级用户。以下就同步协议,架构部署和数据处理等方面进行一些分享。 业务定义、同步协议 我们根据场景,把同步业务划分为如下3类型4协议,如下图所示: Semi-Sync协议 半同步协议,在快同步和慢同步中,同步失败时,实现不重复上传和拉取已同步成功的数据。请注意,它有别于MySQL同步复制的半同步方案(Semi-Synchronous)。 云同步是批量传输数据的,如果某批次出错,或单批次有若干数据出错,导致同步失败。下次同步时会有两个问题,一是客户端重复提交上次的所有数据(包括已成功的数据),二是拉取上次同步成功的数据。 MZ-SyncML设计了ClientAnchor和ServerAnchor两个同步点,在半同步协议里,我们增加了半同步点(SemiAnchor)。 以201慢同步为例说明。 第一次201同步: 客户端提交100个联系人,当前同步点Anchor 服务端成功写入40个,60个失败;则生成这40个Mapping数据,包括Luid、Guid、Anchor三个字段;更新SemiAnchor的值为Anchor;返回100个Result数据,40个成功,60个失败 客户端接收到100个Result数据,对40个成功的数据生成Mapping;并更新SemiAnchor为Anchor;同步结束,结果为失败 第二次继续发起201同步: 客户端检测有100个联系人,但SemiAnchor与Mapping标记了40个同步过的数据,过滤掉这40个联系人,只上传60个联系人 服务端接收到60个联系人,并成功写入;但服务端有40个联系人,需要返回给客户端;进一步检测到SemiAnchor和Mapping,发现这40个已同步成功,无需返回给客户端 客户端拉取数据为0,无需处理;同步结束,结果为成功;下次则会发起200快同步 如上,根据SemiAnchor和Mapping数据,可以解决同步失败下数据重复提交,二次拉取数据两个场景问题。 MZ-SyncML协议 MZ-SyncML,基于微软的SyncML协议(俗称4步同步),进行重新设计和开发实现的魅族同步协议。它交互精简、业务聚焦,解决了典型的结构化数据同步需求,如联系人、日历、便笺、通话记录、信息等业务。 它采用JSON进行数据交换,由接口层、同步点管理、数据解析、中间缓存数据管理、同步引擎、同步策略、冲突解决机制和Mapping关系管理等逻辑组成。 在同步策略上,实现了双向同步200(Two-way、快同步)、慢同步201(Slow sync)、客户端刷新同步203(Refresh from client)、服务端刷新同步205(Refresh from server)。 在同步点管理上,设计了客户端同步点(ClientAnchor),用于校验验证采用何种同步类型,管理选取客户端增量数据;还有服务端同步点(ServerAnchor),用于管理选取服务端增量数据。 一个完整的同步有4个阶段,分别为Request、Submitdata、Getdata、Result,简单示意图如下。 其中,sessionId为服务端的会话标识,isFinal为分批数据是否结束标识,clientData为客户端业务数据,serverData为服务端业务数据,resultList为处理data结果数据(标识成功或失败)。如下图所示: One-Sync协议 一次同步,即一次交互完成数据同步的协议,它解决联系人分组,便笺分组,短信快速回复、邮箱帐号和浏览器书签等小数据同步的场景。 数据模型设计为{key,value}的结构。key存储业务的唯一值,如分组名称;value以JSON格式存储多个附属值,如邮箱帐号的帐号类型,帐号名称等。 一般而言,数据变更有增删改(N、U、D)三个类型。对于key变更的操作,One-Sync里把U分解为N、D两个操作。而对于key不变,value变化的变更操作仍为U。 One-Sync只有一个同步点,由服务端同步点ServerAnchor。 在一次请求中,客户端会上传SyncType、ServerAnchor和变更数据;服务端则把ClientData和ServerData进行比对后存储,然后把比对后的SyncType、变更数据和New_ServerAnchor返回客户端。 One-Sync同样支持200、201、203、205同步类型。 以客户端发起205同步为例(服务端刷新同步),逻辑如下: 客户端请求205的同步,不提交本地数据 服务端丢弃客户端提交的数据,返回服务端的所有数据 客户端接收数据成功,数据处理成功;然后清除本地旧数据,保证本地数据与服务端一致;本次同步结束,结果为成功,下次会进行200快同步 客户端接收数据失败,或接收成功后数据处理失败;则不清除本地旧数据;本次同步结束,结果为失败;下次仍进行205同步 File-Sync协议 文件同步协议,是从MZ_SyncML分离出来的独立文件同步协议,它描述了文件类数据的同步方式。 采用和MZ-SyncML类似的方式,把变更文件信息列表进行同步,再按需进行上传与下拉文件。 业务上需要考虑一点,即文件对象需与父对象保持一致。 注意,文件同步需在父对像同步完成后进行;并且,文件同步的类型需与父对象同步类型一致。 如联系人本次同步类型是205,则联系人头像同步类型也必须是205。否则,会导致联系人头像同步时,解决冲突的合并规则与父对象不一致。 同步失败处理机制 同步涉及到客户端、服务端逻辑,实际逻辑中会有失败的场景,我们设计了失败处理的机制。 在Submitdata阶段,服务端处理完客户端数据,会返回每条的结果数据Result给客户端,标记成功或失败; 在Getdata阶段,客户端处理完服务端数据后,也会提交每条Result数据给服务端,标记成功或失败; 只要有一条数据标记为失败,当次同步即被认为失败; 下次同步会使用上次的同步点(如何不重复传输数据,请看Semi-Sync协议)。 服务架构 分析云同步的业务场景,具有下面的特性,如下图所示; 云同步的服务端服务能力,和用户数成正比关系。魅族云同步随着用户规模的增长,经过几次的重构、线上运行、探索与沉淀,逐步形成了当前平台的架构。 接口规范 我们规范了接口的固有参数,扩展参数,统一返回格式,可精确到代码行的错误码,匹配错误码的信息。 如userid、imei、sn为固有参数;像apk版本,系统固件为扩展参数,部分接口不需要。 返回格式例子如下: ?
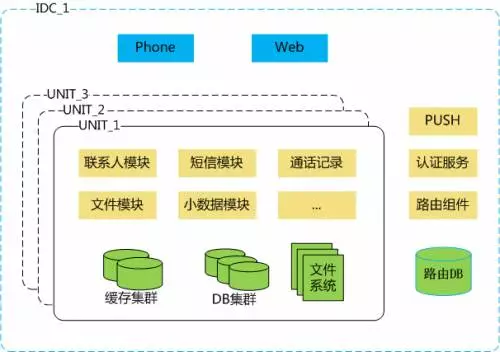
这里的code为错误码,200为成功,其他为错误。value是成功时返回的数据,建议使用JSON格式传递。 message是code对应的错误信息,它与code共同放在资源文件。在返回时由一个MessageHandler截停,自动填上code对应的message,不需要人工维护。 海量数据+路由组件 云同步的数据是海量的,DB记录数可能达到百亿级、千亿级,单个数据库解决不了云同步的业务场景。 我们按用户标识(Userid)进行水平拆分,设计出多个数据库;配备一个Userid到DB的路由规则。 单实例DB服务器上部署多个数据库,建议10-30个,既降低运维成本,又提高资源利用率。 横向扩容时,更新路由规则即可平滑完成。 该DB集群,由一个路由组件(SyncRouter)来管理。它包括Userid到DB、Userid到Unit、Userid到Redis、Userid到文件系统的多个路由功能。它具有透明访问、业务低耦合、DB连接池自管理等特点。 我们采用RDB存储对用户常用的热数据,而用NoSQL存储冷备数据。例如联系人有个时光机的备份功能,我们就采用HBase来实现存储。 模块化+单元化 通过业务规整,抽象出了联系人模块、短信模块 、通话记录模块、小业务模块、文件同步模块。 联系人、短信、通话记录是使用频次和数据量最大的3个项,故此独立成模块。 文件同步,与结构化数据分离,进行IO等有针对性的性能调优。 我们在一个IDC里划分了多个服务单元(建议不多于5个),每个单元包括服务模块和存储,一个单元服务只服务合理的用户数。这样易于控制规模,分拆风险,维护迁移和容灾。如下图所示: 流量优化 流量优化一方面是采用gzip或deflate进行压缩传输,一方面是让原始数据尽可能的小。 魅族云同步第一阶段采用XML为交换格式;第二阶段上线了MZSync项目,采用JSON为交换格式。 我们在考虑数据格式时,选出传统JSON、精简JSONProtobuf三种格式,进行对比。 精简JSON,是指变量名为少量字符,不输出空值变量的JSON格式。 Protobuf本质上是对变量进行排序,不需要传变量名。 精简JSON和Protobuf的设计原理,有点相似,前者简化变量名,后者不传变量名。 最后,我们选择了精简JSON格式,与传统JSON相比,能减少40%-60%的流量,接近Protobuf的值。 参考图如下所示(使用多维度抽样数据,进行实测计算得到): 多机房部署 我们做多机房部署的目的有三,一是用户就近访问,二是流量调度,三是异地容灾。 看如下云同步的架构图,以3个IDC为例。如下图所示: 部署了多IDC,设计好路由规则,由路由组件提供Userid到IDC的路由功能。 IDC间的用户数据分开,不共享,做好异地容灾,如把IDC_1的数据备份到IDC_2。而在IDC_1出现故障无法提供服务时,通过GSLB分流,把该用户群分发到IDC_2里进行服务。 路由DB采用单点写保证一致性。所有IDC通过专线访问主IDC,操作主路由DB;主IDC通过MQ通知其他IDC,进行数据更新,保持数据一致。 手机端根据Userid和域名,访问GSLB的分发服务,获取到用户相应的同步服务IP,实现流量调度目的。并且,手机端都通过IP访问同步服务,不使用域名,有效避免DNS劫持问题。 GSLB根据IP所在区域和所属线路,在最优的IDC落地,并返回业务的最优IP(GSLB详见魅族另一篇博文,不再赘述)。 理论上,上述的方案仅适应于有客户端的Http、Https请求,不适合浏览器访问。 为此,我们做了一个扩展,支持浏览器按GSLB的规则进行调度。 把业务分为总域名、多个子域名(匹配多个IDC); 业务层嵌入一个GSLB模块,根据设定规则进分发到目标子域名。 结语 以上,便是在业务的实践、发展中,总结的同步协议,架构部署和数据处理心得。欢迎大家讨论交流。
|








 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved