 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 大数据谬误 —— 为什么我们需要收集更多的数据
发布日期:2016-3-7 21:3:9
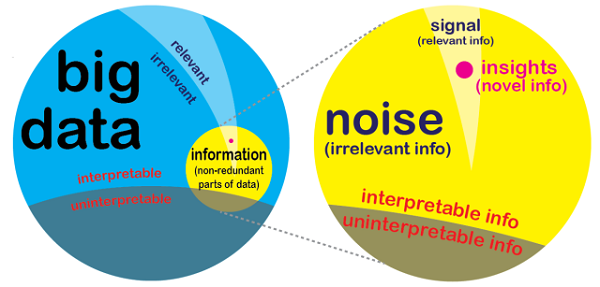
Michael Wu(博士) —— Lithium首席科学分析师,为Lithium提供社交网络数据复杂性探索和理解的方法。 数据的价值等同于从中挖掘到的信息和见解;并根据它们做出正确的决策,从而获得一定的竞争优势。而我们对于大数据的期望也是收集足够多的信息并获得有价值的见解。然而人们还没有意识到数据和信息的不同 —— 你从海量数据中提取到的信息并不一定都有意义和价值。 数据不等于信息 许多人口中的数据和信息都是等价的,然而两者之间却有着很微妙的区别。数据只是事情发生的简单记录,它只是记录了事情发生的时间、地点及涉及人物的原始数据。是的,数据中确实包含着大量的信息。这也正是对大数据理解的谬误所在:大数据虽然给你带来了大量的信息,但数据的增长却没有带来成比例的信息增长。实际的情况就是:收集的数据越多,从中提取到的信息比例越低。这就意味着随着数据体积激增,你从中提取到信息比例会逐渐的缩减。虽然听起来很不可思议,但事实就是这样的。下面来看一些例子: 例1:机场视频监视记录。首先,视频文件已经是相当之大了;其次,机场使用的是24/7闭路式监测系统,而HD设备会进一步增加数据的体积;最终,机场可能拥有成千上万的摄像头。如你所见,这些检测摄像头记创建的视频记录可轻松的获得“大数据”的资格。 不妨设想一下若我们把摄像头的数量提升两倍会发生什么 —— 双倍体积的数据。然而很显然你可能还是得不到双倍的信息。有许多的监视设备拍到的东西都是重复的,可能会有一些微小的区别 —— 不同的地区在些许不同的时间内会拍到完全不同的画面。在信息量这个方面,我们可能永远都得不到2倍。而且随着监视设备的增加,信息重叠的可能性也会随之增高。这就是为什么随着数据的增加,信息的收益却在减少 —— 其中的冗余越来越多。 例2:数据的备份和复制。若你认真查看你的电脑,你会发现:这些年的使用,你创建了成千上万的文件。不论它们是怎样产生的(拍的照片、写的博客或是发送的电子邮件),其中必然包含着一定数量的信息。这些文件储存在你的硬盘中,并占用一定的空间。 事情发生了:不出意外,你一定会定期的给数据做备份。这里我们可想象一下在第一次给硬盘做备份中花掉的时间。单纯针对数据的本身而言,你已经拥有双倍量的数据了。若你备份之前拥有50GB数据,那么备份以后你则拥有了100GB。然而经过了备份,你即可获得双倍的信息量了?结果是否定的。事实上完成这个操作以后你没有额外的获得任何信息,因为备份中的文件和初始磁盘上的文件包含的信息是完全相同的。尽管我们的私人数据和大数据不搭边,但这个例子却阐明了数据和信息之间微妙的差别。下面我们来看一下涉及到更大体积数据的例子。 用不等式表达就是:信息 ≤ 数据。所以信息不应该是数据,而是没有冗余的数据。这也是为什么给数据备份却无法增加信息量的原因,因为拷贝是冗余的。 例3:社交渠道的更新。那么社交中的大数据又是什么情况呢,比如:Twitter。对比平时我们不妨多推特一倍的内容,那么Twitter肯定会获得两倍的数据。但Twitter有获得两倍的信息吗?很显然没有,决定信息量的是你推特的内容而不是次数。当然若我们推特的内容是完全无冗余的,那么Twitter毫无疑问的将获得双倍的信息。但这永远都不可能发生!我们来看一下其中的原因: 首先,我们会相互转发。因此在互相的转发中,会产生很多冗余;即使我们拒绝转发,而在同一时间发布同样内容的几率也是很高的,因为使用Twitter的人太多了。虽然每个推特使用的措辞可能会完全不同,但包含相同网络内容的不同推特所(可能是条博客、很酷的电影或者爆炸性新闻)所造成的冗余是很高的。此外,一段时间内我们很可能对同类的新闻感兴趣。因为我们推特的内容更趋向于我们的品味和兴趣,所以同一个人推特不同的内容都会存在一些冗余。 所以很清楚的看到:即使对比平时我们多推特了一倍的内容,却因为中间存在着相当多的冗余导致Twitter不会获得双倍的信息。此外我们还会通过不同的渠道获得相同的内容,但因为仅仅是拷贝我们不会多获得任何信息。所以尽管数据会带来信息,但是数据不等于信息。信息只是数据中不重复的部分。这样的话,我们从数据中提取到信息只占数据总量的一小部分。所以虽然理论上信息是小于等于数据的,但现实中往往是信心远小于数据。因此大数据可捕捉大量信息的想无疑是天真和不切实际的,大数据的价值完全被夸大了。 信息不等于见解 尽管我们从大数据中提取的信息量也许被高估了,但从大数据中获得的见解仍然是极其宝贵的。那么信息和见解两者又有着是什么样的关系呢?所有的见解都源于信息,但是不代表所有的信息都可以提供见解。对于能给出有价值见解的信息,我们有3个标准: 1、关联性。必须是和用途与价值紧密相关的信息。相关的信息通常被看作是信号,而不相关的则被作为噪音。然而关联性有着相当的主观成分,对一个人很重要的信息可能完全和另一个人无关。这也是Edward Ng(一个著名的数学家)说过的:“一个人的的信号恰好是另一个人的噪音。” 此外,关联还不仅是主观的;同样是前后联系的。关联还可能是人从一个环境中换到了另一个。打个比方:如果我下星期将要去NYC的话,那么NYC的交通将会关联到我。但当我回到SF,那么同样的信息将会和我有关联。因此见解又是关联信息中一个很小的子集,这里别忘记相关信息已经是可解释信息中很小的一个子集。 2、可解释的。因为大数据包含如此多的非结构化数据和不同的媒体类型数据,导致其中大量的数据和信息都不可解释。 举个例子:123,243,187,89,157这组数据,它们能代表什么?它可能是你在TechCruncn上读过前五篇文章的like数目,也可能是一个黑白图像上5个像素点的亮度。没有更多的信息和元数据,是无法解释这样的数据的。因此不能解释的数据和信息是不会给你提供任何见解的 —— 见解只存在于提取出信息中的可解释部分。 3、“新出炉”的。必须是有远见的信息。这就意味着它必须提供一些你以前不曾拥有的新知识。 显然这个标准也是主观的。因为一个人知道的东西另一个人不一定也知道,而新鲜也是因人而异的。这种主观性中有一部分继承于关联的主观性。若有些信息和你是关联的,而且之前又并不知道;那么当你去学习时,它将是新的。假如这个信息和你没有关系的话,那么再新奇你也不可能想去了解它。这样的话这些信息对你来说就是毫无价值的。然而这个见解一旦被你获知,那么当下次你获得的时候就不会再觉得那么新奇和深刻。因此随着我们不断的从大数据中捕获知识,新的见解就越来越难以发现。那么见解这个关联信息中的子集又将继续缩减。 在见解这个子集层层的缩减后,就会发现大数据的价值被彻底的夸大了。当然这里不是说大数据是没有价值的,只是说它的价值被夸大了,因为发现有价值见解的可能性非常小。这样来看大数据可能会让人失望,但是这同样是我们需要大数据的理由!因为从数据中获得的见解越来越少,所以我们必须收集越来越多的数据让我们拥有更多的机会获得见解。虽然更多的数据也不能保证一定会揭露许多有价值的见解,但是增加数据量无疑会增加我们获得见解的机会。 上一条: 大数据和云计算是天作之合
|




 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved