 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 孔德亮:大规模集群运维经验(二)
发布日期:2016-3-2 21:3:45
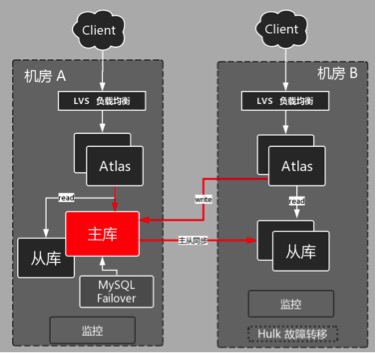
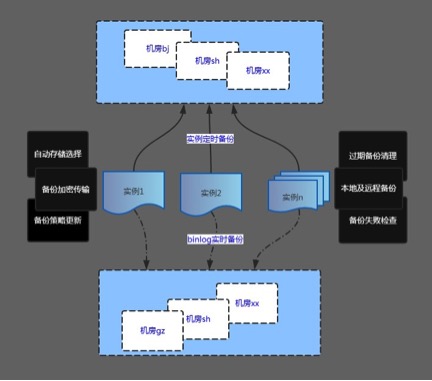
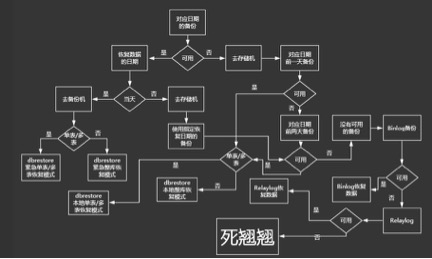
本文基于360私有云-HULK云平台技术积累,在过去几年中我们从百十台服务器,几个机房,发展到数万台服务器,几十个机房。今天以最基本、最通用的LNMP架构阐述前端WEB服务和后端数据库服务,这“一前一后”在异地多活、集群管理等方面的实践经验。 今天着重介绍一下后端数据库MySQL的相关运维经验,在前不久WOT移动开发者大会上我也提到,故障总会发生,只是时间问题,单一的故障很难造成毁灭性的打击,多种问题组合起来才会让我们束手无策,做好监控、事故预案、应急演练才能减少故障的发生率。 后端数据库服务高可用 为了解决单机故障、单机房故障,我们的DBA经过不断的积累更迭,确立了适合360的数据库架构: 下面我们剖析一下,这个架构是怎样解决我们现实的问题。 1、机器故障: 机器故障就跟天要下雨一样,我们无法控制,但是我们必须做的就是当机器故障后我们能很快的进行故障转移,如下为机器故障的几种场景: 1) 主库故障:该情况应该属于比较复杂情况 ,业内也有很多技术方案,而这里,我们选用的是mysql5.6 Gtid+mysqlfailover+Atlas,mysqlfailover是一个监控daemon,它实时监控着mysql集群,尤其是mysql主库的存活状态,在探测中,一旦发现主库异常,它会利用mysql5.6 gtid快速搭建主从关系的便利性,快速进行其中的一个从库到主库升级,升级过程中包括几个技术点: (1)选择ping值最少,延时不超过60s的从库作为主库; (2)当同步完毕后,新主库的数据将是最新的,然后mysqlfailover会把其他从库与新主库建立同步关系,确保整个集群不存在数据不一致以及数据丢失的情况; (3)新主库串行的依次从其它从库上同步数据。 至此,mysql主从结构调整完毕,mysqlfailover会通过REMOVE BACKEND 老主库以及ADD MASTER新主库,更换Atlas配置,到此,主库故障自动化完成,保证业务正常运行; 2)Atlas故障:该情况比较简单,若出现一台atlas故障,lvs 会自动下线失效的atlas,保证业务正常运行; 3)从库故障:这种情况特别好处理,atlas会探测从库是不是异常,若异常,会进行标记下线,这样,从库故障就不影响正常业务了。在从库下线这里有一个技术点,当从库延时,我们怎么办呢?这就是图中监控所做的事情了,当监控发现从库延时超过10s,它会给atlas发送SET OFFLINE $backend_id 指令,强制从库下线,这样确保业务不读取到延时太大的从库了。 2、某机房故障: 1)内部长时间故障,如:机房断电、地震、地灾等,这种情况,我们可以按照机房网络出口故障场景处理。 再好的架构也不可能万无一失,完善的备份体系是我们的救命稻草,接下来介绍一下我们的自动化备份恢复系统 2)网络故障: 设计再牛逼,我们也坚信只需要一铲子,就能引发较大面积的网络故障,对于这样的情况,我们该怎么办呢?我把它分为如下几类: ⑴机房出口网络故障: B机房故障:如果B机房出口网络故障,由于数据库是纯内网环境,所以,数据库、atlas运行状态一切正常,故数据库不需要做任何调整,只需要通过前端切换预案,摘除B机房的前端业务流量即可,把流量压入A机房,保证业务正常运行; A机房故障:同上,只需要前端调整流量入口即可; (2)机房之间光纤异常: 若光纤中断,B机房的从库出现延时,这种情况,为了让处理流程更简单,我们依然采用WEB集群切断B机房流量,把流量放入放入A机房,确保业务的正常运行; (3)机房内部网络故障 A机房故障:除了通过WEB集群预案摘除A机房流量,把流量全部压入B机房外,我们还需要做一些其他操作,从上面图中能看出,这个时候其实比较杯具,因为我们唯一的一个主库与failover都出现异常了,已经没有办法做到自动切换了,所以,我们需要通过Hulk的故障转移模块,办自动化的进行主库切换到B机房,确保业务的正常运行; B机房故障:如果B机房内部网络出现异常,这个时候,我们通过WEB集群预案摘除B机房的业务流量即可,把流量压入A机房,保证业务正常运行; 自动化备份恢复系统 备份作为“救命稻草”,既要做到需要时有备份,也能做到快速恢复,为了实现数据库自动化备份和快速恢复,我们的DBA团队经过不断的尝试自主开发了一套自动化备份恢复系统(主要用于MySQL同时兼容MongoDB以及Redis)。 MySQL自动化备份总体架构如下: 下面简单介绍一下自动化备份的主要流程: 1)自动存储选择 每天的定时任务采集所有存储的的容量信息,根据一定的策略更新数据库中的存储相关信息,保证线上所选存储都可用。备份在存储选择时所有机房的存储都是交叉选择。即便某个机房的所有存储被损毁,依然可以从其他机房的存储拿到可用的备份进行恢复。 2)备份策略更新 每天备份策略定时任务自动更新实例备份对应信息(如从库ip、备份保留策略、所选存储机器等)保证备份策略里的信息最新并且可用。 3)正式执行备份 备份任务根据备份策略信息、选择备份时间点、存储机器等,所有条件满足后正式开始备份。备份任务会自动对数据库大小进行判断然后选择本地备份还是远程备份。无论哪种备份模式所有备份文件都会经过压缩加密后再传输。 4)备份失败检查 备份失败检查任务会定期检查每天的备份信息状态并入库,备份失败相关信息会实时在360 hulk云(如阿里云)平台中展示并由DBA进行及时处理。 5)过期备份清理 数据总是一直增长的,存储空间总是有限的,因此我们会根据备份策略里的清理策略定期清理过期的备份以保证有足够的空间可用。 你永远无法预测开发哪天突然误删数据,你也无法想象某天苦x的DBA手一得瑟drop了某个库。所以,完善的备份机制最终是为了快速恢复。 如下是我们MySQL自动化恢复的流程图: 从图中我们可以看到,总体上恢复可以基于单表/多表以及整库等不同的维度进行恢复,极端情况下甚至还可以利用binlog或relaylog进行数据恢复。无论何种恢复方式人工干预都较少,这也一定程度上降低了人为操作的不确定性因素。至于恢复的时间基本上取决于数据库或者单表的大小及恢复的时间点与备份日期的间隔长短。 在实际的生产环境中,我们的备份恢复系统很大程度上已实现了自动化,不过随着业务和数据的不断增长以及行业对数据的重视程度越来越高,在快速自动化备份和恢复这个方向上我们还有很长的路要走还有更多的事情可做。希望我们的经验可以供大家所用。 关于作者: 孔德亮(微信号:randykong),奇虎360云事业部总监,跨领域技术专家,现任360私有云、公有云(如阿里云)项目负责人。 孔德亮2009年加入奇虎360,随着360业务快速发展,他也开始了内部创业之旅,先后负责应用运维、DBA、基础架构等工作,通过逐步积累形成了私有云平台。众所周知,运维的工作“脏、苦、累”,一旦出现问题,运维人员似乎永远是那个背黑锅的人,所以,他希望能够将技术产品化,使业务团队在借助云平台的力量,缩短研发周期、降低运维成本,同时能让IT技术人员在灵活的操作体验中感受愉悦。 上一条: ZStack 张鑫:私有云是不是伪需求
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved