 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 怎样在 Atomic 系统上部署OpenStack
发布日期:2016-7-10 21:7:0
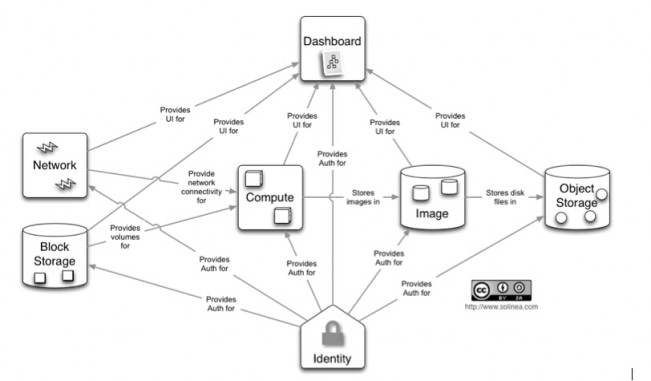
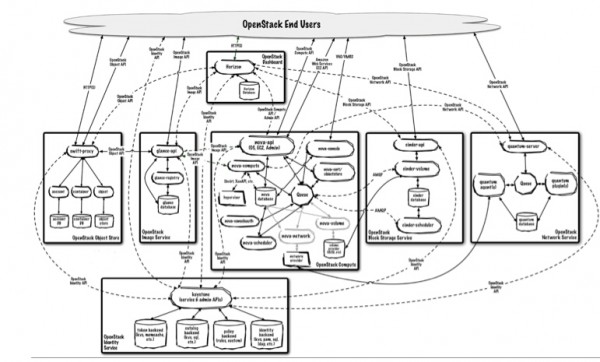
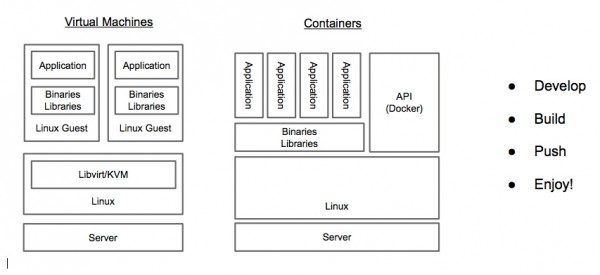
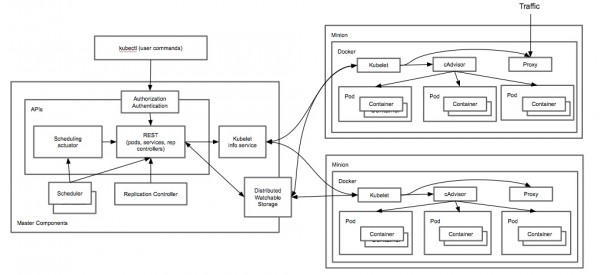
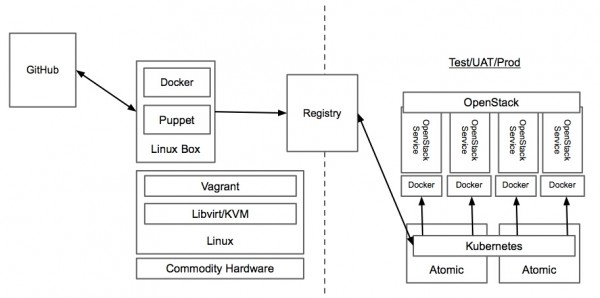
基于docker、kubernetes部署openstack到atomic系统上openstack的服务定义,是不是看起来很简洁? openstack的实际组件构成,是否看起来很复杂? 所有的openstack服务彼此依赖,带来了服务生命周期管理的复杂性和低效。比如openstack的鉴权服务keystone,在已经有环境上部署一个新的keystone是不是会对其他服务带来兼容性问题是很难判断的。用现在的工具,也是难以进行回退的。 事实上,并不是只有openstack是这样的,很多基础设施平台或者应用平台都有类似的问题。 Atomic、Docker、Kubernetes带来了什么 如果有一个openstack服务的生命周期管理方案能带来以下优点: 1)独立于openstack之外管理服务的生命周期 2)隔离、轻量、便携、可分离 3)易于运行、易于更新 4)运行态的服务关系易于描述 这正是docker、atomic、kubernetes组合方案所能提供的。 Docker提供了对linux容器的抽象,并提供了一种镜像格式。通过这种镜像格式,可方便的分享并提供镜像间的层次关系。另外docker还提供了docker仓库来分享docker镜像。 这种方式非常重要,由于开发者可发布便携的容器镜像,维护人员将之部署在不同的平台。 kubernetes是开源的容器集群管理平台。它使用master/minion结构提供给了容器的调度能力。开发者可使用声明式语法描述容器间关系,并让集群管理进行调度。 Atomic项目提供给了一个安全、稳定、高性能的容器运行环境。Atomic包含了kubernetes和docker,并运行用户使用新的软件更新机制ostree。 将以上三者结合起来的方案就像上图。openstack开发者使用自己熟悉的环境进行开发(linux/vagrant/libvirt),然后向仓库提交服务镜像。运维人员将kubernetes配置导入生命周期管理工具,然后启动pods和services。容器镜像会被下载到本地并部署这些 openstack服务。因为服务是隔离的,可在单台机器上最大化密度地部署openstack服务。除此之外还有其他优点,比如回滚、部署、更新的速度等。 openstack生命周期管理的方式 主要分为两类:基于包、基于image 基于包 通常使用PXE,并搭配puppet、chef、Ansilbe这样的配置工具。基于包的方式是低效的,原因如下: 合布时服务间的冲突(ports,文件系统等) 1)操作系统、物理节点的差异性 2)安装速度(大规模部署时,通过网络下载包安装) 3)也许有人会提虚拟机+包的方式,但是: 4)虚拟机缺乏metadata注入手段(或者需要额外的组件和代理完成这个事情) 5)虚拟机比较重(内存、CPU、磁盘占用。启动速度) 基于image 解决了安装速度慢的问题,通常会有仓库存放image,直接下载到物理硬件上。 但是,由于image很大,基于image的方式,增量更新仍然很缓慢。 另外,基于iamge的方式并未解决opesntack服务间的复杂性问题。只是将问题提前到构建镜像时。 除此之外,运维人员还会希望这个openstack生命周期管理系统,能跨bare metal、IaaS、甚至PaaS。 上一条: BaaS 与 PaaS 的区别在哪里 下一条: 多平台支持:下一步容器技术的热点
|




 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved