 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 自动化我们的基础设施来武装工程师
发布日期:2016-7-9 10:7:29
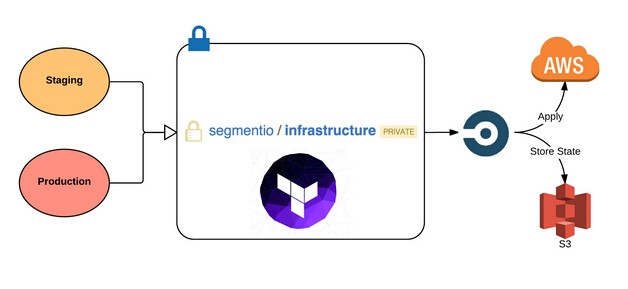
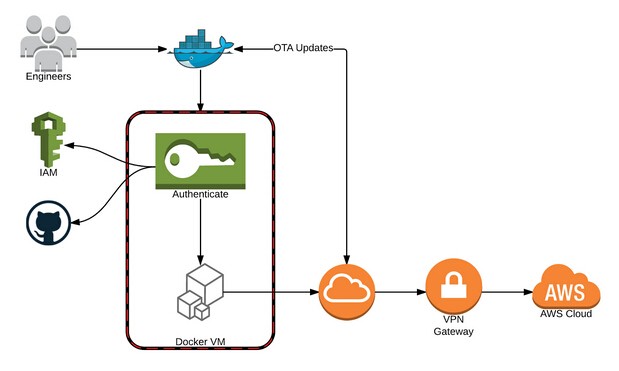
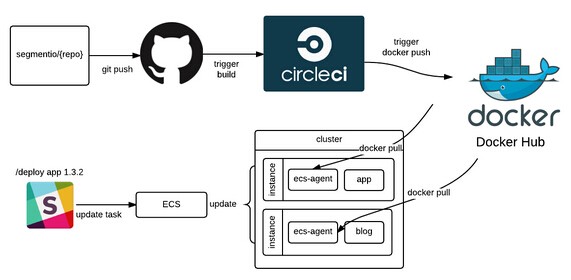
segment是一家客户数据中心,致力于帮助数千家公司收集、处理数据,本文主要讲了segment在自动化基础设施方面的实践,主要包括同步开发环境、映射开发环境和生产环境、本地开发和部署到生产环境。发展企业是艰难的,发展一个支撑企业前行的工程团队可说是更加困难的。但没一套稳定的基础设施,做这两件事基本是不可能的。特别是对于高速发展的企业,必须授权每一个工程师在编码、测试和交付代码方面具有高度的自主权。 过去的一年中,我们增加了达60个新的集成环境(总数超过160个),为合作伙伴建立了一个平台,用以编写他们自己的集成,发布了Redshift(红移)集成,同时发表了几个重大的产品公告。那段时间,围绕多环境管理、部署代码和通常的开发工作流程,我们经历了许多成长的烦恼。之后,我们的工程师是最幸福、最具生产力的,由于他们的时间都花在发布商品,打造工具和扩展服务上。开发流程和它所支持的基础设施简单易用、扩展灵活是非常重要的。这就是为何我们自动化了自己的基础设施的众多方面。下面我将分享关于我们当下的一些更加详细的设置,主要包括这几个领域: 同步开发环境 本地开发 部署到生产环境 映射开发环境和生产环境 一起来深入的探讨一下吧! 映射开发环境和生产环境 理想的情况是在开发环境和生产环境中运行相同的代码,然而这样分离,开发环境中的代码也许永远不会对生产环境中的代码产生影响。之前我们将AWS状态(由Terraform生成)存储在Terraform的文件中,但是它并非一个完美的系统。例如,若两个人异步操作并应用了不同的改变,状态将会改变,最后推送代码的人将很难搞定合并冲突。 我们尽可能以最简单的方式实现了staging和production环境的映射: 从一个文件夹复制文件到另一个文件夹。Terraform使我们在修订基础设施、部署新服务和做出改进方面节省了大把时间。在应用之前,我们通过编写定制的构建过程及确保恰当的安全因素已经考虑在内来集成Terraform和CircleC。 目前,我们在Github上有一个名为基础设施的单一库,其中包含了Terraform的脚本集合,用以为每一个容器配置环境变量和设置容器。当我们想要改变基础设施中的某些东西的时候,将必要的修改写进Terraform脚本,并在新的pull请求之前运行它们以便基础设施团队中的其他成员来review它。一旦pull请求合并到主分支,CircleCI就会启动部署进程:状态变为pulled,本地被修改,并再次存入到S3。 同步开发环境 因为代码的复杂性的增长和工程团队的扩大,在所有的工程师中保持开发环境的一致会变得更加困难。在我们现有解决方案出现前,我们的工程师所面临的一个大问题是同步开发环境。我们有一个Github库,里面有一组shell脚本,所有新来的工程师执行这些脚本,将必要的工具和身份验证令牌装到他们本地的机器上,这些脚本也会建立Vagrant和一个虚拟机。 但此虚拟机是在每台电脑上进行本地构建,若你修改了虚拟机的状态,那么为了使得让它恢复到与其他工程师的虚拟机同样的状态,你必须从头构建一切。而当有工程师更新了虚拟机,你必须在Slack上告诉每个人,让他们从Github VM库中拉取代码并重新构建。这是一个痛苦的过程,因为 Vagrant很慢。对于一个竭尽全力快速前行的发展中团队来说,上面的方法并不是一个好的解决方案。 当我们初次尝试使用Docker的时候,我们非常喜欢其在一个可复用和隔离的环境中运行代码的能力。我们想要复用Docker的这些原则和经验,从而在不断扩大的工程团队中保持开发环境的一致。我们写了一堆工具为新来的工程师配置虚拟机,从基础镜像状态升级或者是重置。当我们的工程师初次配置虚拟机时,需Github凭证和AWS令牌,然后从Docker Hub中拉取最新的镜像并构建。 每次运行的时候,我们会通过查询Docker Hub API来确保虚拟机是最新的。这个过程会更新工程师每天所需的包、工具等。这将耗费5秒钟,为了确保一切运行正常,这也是必要的。此外,因为我们的工程师使用Mac电脑,我们从boot2dockerVirtualBox虚拟机切换到了托管于boot2docker实例的Vagrant,以便我们可以充分利用NFS的优势来共享主机和客户机的volumn。在本地部署时,使用NFS,性能得到大大提升。最后一点,NFS允许工程师在虚拟机外部所做的改变可即时地在虚拟机内部反映出来。 通过这个解决方案,我们大大减少了需要在宿主机上安装依赖的数目。现在唯一需要的是Docker、Docker Compose、Go和GOPATH配置。 本地部署 种子库 本地开发时,使用虚拟数据填充本地数据库是非常重要的,这样会让我们的应用看起来更真实。所以,种子库是配置开发环境的共同组成部分。我们依赖CircleCI、Docker和volumn容器来提供获取虚拟数据的便捷途径。volume容器是静态数据的便携镜像。我们决定使用volume容器,由于数据模型和逻辑越来越松耦合而且容易维护。这样做也是以防万一,在我们的基础设施的其他地方可用到这些数据(比如测试等,谁知道呢)。 当我们在开发过程中启动app服务器的时候,就会自动加载种子数据到我们的本地开发环境中。例如,当app(我们的主应用)容器在开发环境中启动,app的docker-compose.yml脚本就会从Docker Hub中拉取最新的种子镜像,并在虚拟机中挂载原生数据。Docker Hub中的种子镜像产生自Github仓库中的种子,作为我们导入到数据库中的原生对象,它就是一组JSON文件。为了更新种子数据,我们将 CircleCI配置到仓库上,以便任何到主分支的推送都会构建(从Docker Hun中赚钱我们的mongodb容器和redis容器)并向Docker Hub中推送新的种子镜像,这样我们就能在app中使用这个容器了。 生成微服务 因为Segment数据密集型的特性,我们的app已经依赖几个微服务(db,redis,nsq等)。为了使我们的工程师可开发app,我们需一个简单的方法在本地构建这些服务。Docker再一次使得这种工作流变的十分容易。类似于我们使用种子volume容器挂载数据到本地虚拟机那样,我们以同样方式来使用微服务。我们使用doker compose文件从Docker Hub抓取镜像来进行本地构建、设置地址并最终将复杂性降低到一条终端命令即可让一切启动并运行。 部署到生产环境 你编写代码,但是从不将代码部署都生产环境,这种情况真的发生过吗?部署代码到生产环境是开发工作流程中的一个组成部分。在Segment,围绕部署代码到生产环境,我们优先考虑难易程度和灵活性,因为这使得工程师可快速的行动而富有成效。我们还创造了足够多的工具来为处理错误,回滚和监视构建的状态保驾护航。我们使用Docker、ECS、CircleCI和Terraform来尽可能地自动化持续部署。 无论何时代码被推送或者被合并到主分支,CircleCI脚本就会构建容器并将容器推送到Docker Hub上。然后,我们有一个单独的构建服务来更新ECS中的任务定义,这是对于由request请求所触发服务的预设(这样可以让我们通过Slack slash命令进行部署)。使用这种设置,我们可为任何服务定义配置,使得我们的工程师创建和部署新的微服务变得十分容易。正如Calvin在以前的文章中所提到的,“使用Docker、ESC和Terraform重构基础设施”: 部署的自动化和易用不仅对我们的工程师产生了积极影响,我们的成功及市场团队可以在一些仓库中更新markdown文件,当要合并到主分支的时候,踢出自动部署进程以便可在几分钟内看到这些改变。 快速响应和成长 因为我们选择花费精力重新思考和自动化我们的开发流程及其配套的基础设施,使得我们的工程团队反应更加迅速和自信。我们花费更多时间研究我们所热爱的高杠杆工作--发布产品、打造内部工具,并减少花费在yak shaving的时间。也就是说,这绝不是我们的基础设施自动化的最后一次迭代。我们不断地尝试新的工具并测试新的想法,来看看我们可探索出什么可进一步提高效率的东西。对于我们来说,这是一个漫长的学习过程,我们很乐意倾听社区中其他人有关他们开发工作流相关的实践。若你最终要实现这样的事情(或已实现),让我们知道!我们很想听听你做了什么,对于遇到相似问题的人,你所做的哪些对他们有所帮助,哪些是不奏效的。
|




 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved