 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 思源基于Docker与OpenStack的私有云平台实践
发布日期:2016-7-7 19:7:55
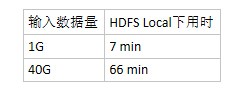
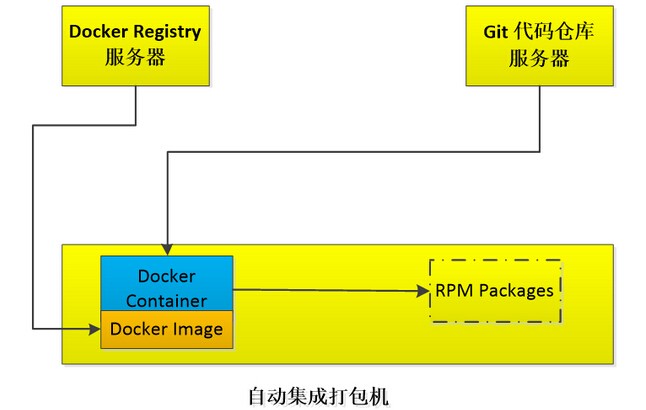
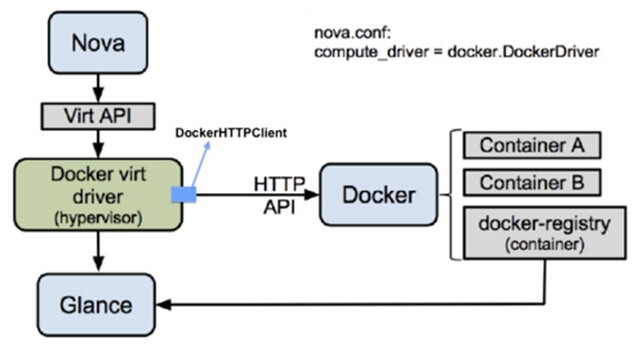
本次分享从以下三方面进行:使用Docker对OpenStack平台压力测试实践、使用Docker加速Sahara-Hadoop、Docker在 Nova项目的使用和实践。无Docker不OpenStack,当前讨论OpenStack总是离不开Docker。下面是OpenStack上Docker技术分布的老图。 我们包括生产化/测试/调研阶段的Docker化项目包括了:Heat、Magnum、Nova、Sahara、及OpenStack平台本身的自动打包和平台稳定性测试方面。 1. Docker OpenStack平台稳定性测试 OpenStack平台本身是一个SOA的项目,具体服务的参数设置需依据集群规模,服务搭建架构等进行相关测试和调优。Fake是OpenStack Nova Compute下的一个Driver,绝大多数Compute API走到这里简单处理后返回成功。我们使用Docker来封装Nova Compute,并在Nova 配置中使用Fake。这样每个Docker Container便成为一个虚拟的Nova Hypervisor Node, 便可模拟Controller集群管理超大量Compute节点的状况;同时Fake Driver 收到请求直接返回成功的特性,让我们可测试超大量的VM同时创建和同时销毁的时候给控制节点和MQ带来的压力状况。 这里Docker模拟了物理服务器,解决了测试服务器不足的状况。这只是一个测试例子,因为测试的不同需求,也许 Nova Fake需要频繁的变更配置,Docker 的快速启动和快速销毁也提供了变更测试环境的便利,Dockerfile的定制化需求不仅为镜像频繁变更带来方便也让测试环境本身更易追溯。 2. Docker 加速 Sahara Sahara是OpenStack中 "大数据即服务"的项目,支持Hadoop、Spark、CDH 5.x等。通过Heat编排可以使用KVM或者Docker作为计算资源。我们测试使用了Hadoop的服务,通过运行KVM和Docker的测试,Docker在启动速度、资源利用率、以及性能开销上具有优势,我这里简单罗列一下测试对比。 基本测试环境: 服务器:2台 24Core 128G memory hadoop: 1.2 job:*streaming MapperReduce 集群规模10 KVM测试数据 Docker测试数据 说明: 不同的配置参数,不同的MapReduce程序,Hadoop计算的时间都不相同,这里只是给出在相同环境下Docker和KVM建的差别。 Docker的测试数据是在Container内部的。 3. OpenStack 自动打包 个人认为私有云平台压力通常没有公有云(如阿里云)高,但个性化定制更强。我们内部的定制化需求也很高(例如集群中计算资源的主机级别和机架级别的反亲和等等)。OpenStack的平台的组件需要频繁更新。我们内部使用的是Puppet推送RPM更新的方式进行,且维护了两个OpenStack的版本,大量编译的依赖和依赖的冲突及编译后的脏数据成为我们的痛点。于是我们将OpenStack所涉及的包括Cinder、Glance、Nova、Neutron、Trove、Sahara等等项目的编译依赖环境统统放进一个Docker Image中。 我们维护了一个脚本,通过参数来指定要编译的OpenStack的版本和组件。该脚本会自动从Docker Registry服务器中pull一个指定版本的的编译环境镜像。并将GIT服务器其中指定版本的分支代码clone到容器中,通过挂卷的方式将编译后的RPM包输出到外部打包服务器上。编译结束后输出编译的状态结果。这样我们便不需再维护一个编译环境了,只需维护编译镜像和GIT库内部源码。可在任意笔记本环境来生成打包环境。 4. Docker Nova项目 这个是大家争议最大的项目,不过对于我们平台来说,服务云化这是第一步。需要其他开发团队逐步熟悉面向容器的开发以及我们对Docker本身逐步的摸索,才敢真正把环境切换到Kubernetes/Mesos上来,进而推进Magnum。借用京东鲍永成的那句话:”让能够接受新世界的团队慢慢先适应“。 通过Nova API调度Nova Compute生产 Nova instance,而Nova instance的类型由具体配置的hypervisor Driver来决定,这里我们设置Docker作为Driver就可以让Nova Compute节点生产Docker。Nova Docker项目来自于社区,我们结合社区代码进行了一定量的修改,并且在镜像定制,具体使用上有一些自己不同的方式。 承载业务方面: Nova Docker这块目前最主要的是Tomcat的服务,Docker用于搭建java tomcat运行环境 dockerfile中将jdk和tomcat安装好,之后Docker启动后通过ansible-playbook 个性化修改Tomcat配置,推送war包至远程容器. 计算方面: 支持Compute节点配置的超分,Docker节点能够超分相对KVM更多的CPU/MEM等资源。 Nova配置文件设置cpushare、cpuset、cpumix三种cpu的管理模式,可以针对不同模式的Container环境来设置CPU模式。 nova 配置为主机预留CPU,保证Container不会侵占预留资源。 上层镜像开机随机生成用户UID,避免映射到宿主机相同的UID。 NOVA 配置不同的Docker API版本。 快照、快照恢复、迁移等基本实现。 支持通过flavor配置元数据,生成一组类似于Kubernetes 的pod。 镜像方面: 引入Supervisor作为进程管理器。 设计了3层的镜像管理格式,最底层为最小化系统,中间层引入了公司yun源,入侵检测设置、ssh/pam等安全设置。 上层可以最小化的实现APP的环境版本管理。支持了Tomcat/Cloudinit/Hadoop的完全或者初步测试使用。 设计了Docker的hostname、dns、网卡名称每次都重置的问题,提供固化机制。 Container实现了支持类似于物理机的FirstBoot和init机制。 Glance管理Docker镜像和Docker快照镜像。 网络: Docker使用OpenStack的网络组建Neutron网络提供Vlan服务。 Docker配置ovs直连和混在模式。 Docker支持安全组的添加、删除、查询、更新等操作。 Switch APR Proxy 老化时间过问题,开机发送free arp。 虚拟网卡TSO的自动关闭。 解决Docker的hostname、dns、网卡名称每次都重置的问题,提供固化机制。 网络限流。 存储: 使用Direct LVM代替 Docker默认loop模式,增强稳定性。 初步支持了Container挂卷的Feature。 依据不同的OpenStack Aggregate 设置不同的Contianer存储空间。 5. 遇到的问题 5.1 幽灵容器问题 我们环境中早期的Docker是1.5版本的,在升级1.7的时候,部分container的进程从容器逃逸,容器处于Destroyed状态,容器进行任何stop、remove都会出现如下报错: Container does not exist:container destroyed。这是个社区已知的问题,目前社区没有完整的解决方案。升级过程中先关闭老的容器后再升级Docker可以避免该问题。出现问题之后要恢复相对麻烦。 5.2 NFS Server无法启动 这个问题是两个小问题: kernel模块的reload设置。 kthreadd创建进程。 第一个问题代表了一系列问题,这个是由于因为文件系统没有kernel的目录,模块依赖关系无从查起。通常此类服务都可以在配置文件中关闭模块的 reload过程,例如NFS就可以配置。第二个问题是rpc.nfsd 通知kernel去建立nfsd服务,kernel通过kthreadd来创建nfsd服务。所以nfsd进程不会出现在Container内部,而是暴露在宿主机上。 5.3 用户隔离不足 我们测试环境中,容器密度较大。Container新建用户对外全部映射为 UID 500或者501,出现了Resource Temporarily unavailable。 CentOS默认用户UID从500开始,虽然ulimit设置上限是相对独立的,但是统计已经使用资源时却是一起统计的。所以在密度较大的测试和预生产环境可能会出现这样的问题。我们的解法是在我们添加的FirstBoot中创建一个随机UID的用户。这样相同的镜像创建出的用户UID也不同。大家各自统计,尽可能避免问题。 5.4 .device mapper discard导致的宕机 这个问题反复出现在某些服务器上,宕机重启后通过IPMI consule进入时系统已经重新挂载了CoreDump的Kernel,看到CoreDump生成dump之前进行Recover操作和Data Copying操作,导致恢复时间很慢。通过Coredump分析属于Kernel在DM discard方面的一个BUG,方法为禁用docker devicemapper的discard。具体为设置Docker启动参数"--storage-opt dm.mountopt=nodiscard --storage-opt dm.blkdiscard=false”。该问题已经在多个公司分享中看到,解决思路也基本一致。 5.5 线程数量上限" fork: Cannot allocate memory" 我们的环境中出现过1次,表现为宿主机无法ssh登录,通过IPMI Console进行登录闪断。这个问题原因是由于某个应用的问题导致生成大量的线程,达到了系统线程的上线。 我们认为: pid_max 和 threads-max 值如何设置不影响单个进程的线程数量,上限目前为32768。 pid_max 和 threads-max 影响所有线程的总量,二者较小者为系统上限。超过系统上限后部分系统命令都无法使用。 调整系统上限后虽然可以有更多的线程,但是太多的线程将会对系统稳定性造成影响。 解决思路 环境中所有宿主机将/proc/sys/kernel/pid-max设置为65535,并通过nagios监控告警宿主机上的线程数量。 从应用层(tomcat)限制线程上限。 6. 未来 Cobbler puppet in Docker 快速部署OpenStack 。 Magnum + Kubernetes的微服务架构管理。 Neutron 插件服务用Docker替换 Netns。 Q&A Q :能否详细叙述一下幽灵容器问题? A:从低于1.5(包括1.5)向高于1.6及其以上进行docker daemon过程中,如果没有关闭所有的Containe。那么当高版本Docker Daemon启动后再次start新的Container时,这些Container将无法关闭。大量操作都会报错。 执行stop或者remove命令将会有如下报错:Server Error: Internal Server Error ("Cannot stop container XXX: [2] Container does not exist: container destroyed") Remote API 针对该Contianer的报错如下:json, stats, changes, top, logs returned valid responses;stop, pause, wait, kill reported 404 (!) 复现方法: 在1.5版本的Docker中run一个Container。 将docker daemon升级为1.7。 重新start该Container。 尝试执行stop 该 Container。 高版本Docker的升级过程: 当docker Daemon非正常关闭的情况下,所有Container首进程都会失去父进程,从而被 init 收养。此时Contaienr内部进程逃逸。 当docker Daemon重新启动时,将会针将已经处于关闭状态的Container原有已经逃逸的进程 Kill 掉。 1.5版本之前向高版本升级过程: 当docker Daemon非正常关闭的情况下,所有Container首进程都会失去父进程,从而被 init 收养。此时Contaienr内部进程逃逸。 当docker Daemon重新启动时,Docker Daemon 无法杀死老版本Docker创建的现在已经逃逸的进程。 当逃逸进程对应的Container启动时,逃逸进程将会和新进程同时存在。 当该Contaienr关闭时,新进程被杀死,逃逸进程依旧存活。Container标记Destroyed。 解决方案: 目前来看方案如下只能重启物理服务器来解决。由于我们内部Contianer首进程一定是Supervisor,可以先关闭Docker Daemon后杀死全部的幽灵Supervisor后再重启Docker Daemon后就没问题了。 预防方案还是要在升级过程中,保证关闭所有的Container,首先保证不会有逃逸进程,从而避免形成Ghost Container。 Q:在使用Docker去封装nova compute模拟大规模集群测试时,运行一段时间后总出现部分使用Docker封装的nova compute服务出现down的状态,不知道你们是否遇到过这样的问题? A:我们这边没有遇到,有没有可能是模拟的nova compute进程数量过多消息有所积压。NOVA方面考虑增加NOVA时间戳超时设置。Docker方面建议Docker的网络使用host模式,并在 NOVA配置文件中设置不同的host,以便成为不同的hypervisor node。 Q:Sahara在使用Docker替代KVM创建Hadoop集群时,是直接使用heat创建Docker,还是使用nova-docker?Sahara相关的代码是否需要改动,遇到过哪些坑? A:我们是使用nova docker的driver创建docker container的,Sahara本身相关的代码有部分改动,但是不大,主要改动在使用container和虚机的差别,比如hostname、cloudinit的部分配置等等。 Q:Docker 的网络模式中,中间添加一层linux bridge的原因是什么,这么做是否会有性能问题? A:这个还是为了安全组,实际上我们支持配置两种模式,linux bridge并不是默认配置的。OpenvSwitch 2.4以后可以根据流表设置安全组。 Q:Container限速是如何实现的,是否有必要针对Container进行限速? A:我们的环境中使用的OpenvSwitch,通过veth pair的方式建立虚拟网络设备的关系。限速主要是使用tc,毕竟OpenvSwitch的限速也是使用tc做的。 Q:NOVA组件中Docker的高级特性无法使用你怎么看,是否使用docker api来控制容器? A:上面已经说过这个问题了,其实通过flavor metadata的设置,nova docker driver 可以实现生成一组容器。nova docker这块过去确实是直接调用Docker API的,但是为了应对不断变化的API,我们使用了docker-py作为Client,并在nova 配置文件中增加了API版本的设置。从而尽可能拿到Docker本身升级带来的福利。 Q:OPS已经有超分设置,你设置超分的意义是什么? A:我们Docker和KVM都在一个openstack平台中,而nova的超分实在NOVA Conductor中生效的。Nova compute Libvirt Driver是直接上报的服务器核数。而我们认为Docker在密度上存在比KVM密度更高的需求,所以在Compute上支持超分是有必要的。 Q:使用CPU share是否会出现单个容器负载很高的场景,出现这种情况如何处理? A:还是会出现的,记得有个容器CPU占用1600%的场景(32核心)。通常这种情况还是应用出现了问题,最简单的方法是通过 cgroup本身的命令进行限制。容器重启之后该限制就会丢失。限制方法例如: cgset -r cpuset.cpus=20-23 cpuset:/docker/91d943c55687630dd20775128e2ba70ad1a0c9145799025e403be6c2a7480cb2 Q:能否详细介绍下ARP问题? A:由于建立的vm的ip之前分配给了已经删除的vm,导致mac被记录在交换机上。数据交换经过3层,3层交换机会将mac直接返回给ping的一方,导致无法ping通、 启动container后通过arping -c 3 -f -U -I eth0 172.28.19.243 -c 3开机发送免费arp来处理。 Q:Docker 的监控和scale-auto是如何实现的? A:监控方面目前主要是通docker stats api 和 部分脚本来实现,集成到Zabbix中,后面会考虑使用CAdvisor。 后者目前不支持,计划上会在Kubernetes平台中支持,而非heat或NOVA中。毕竟这是Kubernetes、Mesos它们的专长。 Q:OpenStack 如何对novadocker环境的container进行监控?在监控指标上是否与其他hypervisor driver有区别? A:监控方面目前主要是通docker stats api 和 部分脚本来实现,集成到Zabbix中,后面会考虑使用CAdvisor。监控上有一些区别。主要是pid_max、docker daemon存活,和Docker自身存储pool等Docker特有的,其他方面没有太大区别。 Q:你的三层镜像中,第一层和第二层都是系统层,为什么不合并成为一层? A:首先我们的第一层镜像并不是通过dockerfile创建的,而是依据官方文档从0建立的最小的镜像,这一层是很少变动的。而第二层的设置是为上层设计的通用层,涉及到进程管理器、SSH设置、pam设置、入侵检测设置、开机初始化设置、还是有很大可能变动的,我们希望有关配置都应该放入dockerfile以便管理。 Q:Nova Docker快照是如何实现的? A:将操作的Container commit成为一个镜像,并上传到glance中。 Q:nova-docker如何支持cloudinit? A:因为在novadocker中就是完全模拟KVM的网络模式,所以cloudinit除了一些小幅配置变更之外没有什么特殊的。 sed -e 's/disable_root./disable_root: 0/' -e 's/ssh_pwauth./ssh_pwauth: 1/' -e '/ssh_pwauth:/a\ndatasource:\n OpenStack:\n max_wait: 120\n timeout:30' cloud.cfg Q:NOVA Docker实现了热迁移吗?如何做快照? A:热迁移目前还没有支持,nova docker快照就是将容器commit成一个镜像,然后使用glance的接口上传glance中。通过快照可以重新建立新的container。 Q:nova-docker不是早在H版本就废弃了吗?你们自己维护的? A:确实废弃了,我们自己维护。不过GitHub上有了更新,我们刚刚merge机那里一些特性。可以再关注一下。 Q:您好,贵公司只维护Git代码和镜像容器。请问假如同一个编译环境,能编译不同操作系统版本的库吗?或者镜像。因为同一套代码会部署到不同的系统上? A:我们这条编译环境只是用来编译OPS本身的,如果需要增加新的编译环境,我们会向Registry推送一个新的编译镜像。 Q:glance管理镜像和快照时有没有能用到Docker的分层?如果有,如何利用的? A:没有,tar包形式,compute节点下载之后load到compute节点上。 Q:Hostname DNS 贵方 用什么方案固定? A:首先Container创建之初,hostname和DNS都是通过Docker API来设置的。Hostname是nova instance的name,DNS是公司内部设置。如果想修改Container默认设置也是可以的,我们在内部镜像预留了一个目录,该目录下的 hosts、hostname、DNS如果存在都会在Container启动后主动覆盖Container外部挂载的内容。 Q:生产环境相比测试环境有什么不同吗? A:Docker在CPU超分系数不同,系统pid_max等调优参数略有不同。 下一条: 大型网站技术基石之 OpenStack
|




 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved