 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 可视化:图像的主题色提取算法的简介
发布日期:2016-3-15 10:3:50
可视化:图像的主题色提取算法的简介 浙江大学CAD&CG国家重点实验室可视化与可视分析小组特别将论文进行了整理,下面是文章的摘要。 斯坦福可视化组非常有必要介绍一下,领头的两个大牛一个是Jeffrey Heer是信息可视化和人机交互领域近几年的当红炸子鸡,论文兼顾创新性和实用性,惊才绝艳。另一个是Pat Hanrahan教授,横跨科学可视化和信息可视化两个领域,即便不知道这个名字那今年红得发紫的数据可视化上市公司Tableau应该都是知道的,他就是联合创始人,Tableau原生于他的Polaris系统。 回到正题,这篇文章解决了图像的主题色提取的问题,属于颜色建模这个topic。论文的一作同一年在Eurovis、CHI和SIGGRAPH上都发表了颜色建模的文章(SIGGRAPH的论文现在处于conditionally accepted状态),Eurovis和CHI都是最佳论文之一,真的可以说是厚积厚发。 这次真的是回到正题,回到这篇论文。一般的主题色提取方法有k-means和fuzzy c-means的按像素颜色值聚类的方法和颜色直方图取峰值的方法。其实论文的思路并不复杂,对图像定义一系列的特征,套用多元线性回归模型LASSO,在众包平台亚马逊土耳其机器人上建立任务收集训练集,LASSO通过训练集的学习增加关键特征的权重减小冗余特征的影响,从而生成一个比较好的主题色提取模型。下面分别说明特征定义、回归模型和user study三个部分。 其实主题色这个概念真的是公说公有理,婆说婆有理,评判一张图像的主题色是哪些,一千个看官可能得到同一千个不同的答案,但是他们的答案大多很相近。因此本文以用户定义的主题色作为标准答案也算合理。对于每张图像,文章以k=40用k-means方法计算图像的40个颜色作为基准色。用户只能从这40个颜色中挑选5个颜色作为图像的主题色。 文章定义了以下6个方面的特征,提取计算出79个特征变量,这里作简单说明一些概念: 覆盖误差 coverage error:覆盖误差定义为用主题色去覆盖整张图像所得到的图像和原图像的颜色误差,分硬误差和软误差两种,区别在于一个像素点是由单一主题色覆盖还是由多个主题色的线性叠加覆盖。相似地,还定义了像素在亮度、饱和度、红绿、蓝黄等颜色通道的覆盖误差,以及对图像进行分割后按区域计算的覆盖误差。 视觉显著性 saliency:文章以用户对图像的眼动跟踪数据取定义图像中每个像素的视觉显著性,定义某一套主题色在图像中的视觉显著性为所有主题色所在像素的视觉显著性的叠加,同时定义某颜色视觉显著性密度为叠加值对像素个数的比值。 颜色集中性 color impurity:颜色集中性考虑与主题色相近的前5%的像素之间的距离。 颜色多样性 color diversity:颜色多样性考虑颜色之间的平均、最大、最小距离。 颜色可命名性 color nameability与颜色统计 color statistics:这两个听起来比较直观,实际上非常模糊,文中也没有详细介绍。 定义好这79个特征之后,就要轮到LASSO上场了。LASSO(least absolute shrinkage selection operator)是一种多元线性回归方法,在传统的多元线性回归式子之余,通过一个约束条件达到特征选择的目的(下图公式摘自于LASSO原文)。其中x是特征,β是特征的权重,如果约束t是一个无穷大的值,那么就跟一般多元线性回归没有差别,但是t逐渐减小的时候特征权重就收到挤压(shrinkage),从而达到去除冗余特征的选择(selection)作用。通过LASSO方法对训练集的学习,所定义的79个特征就被减少到非常有限个。如下图所示:
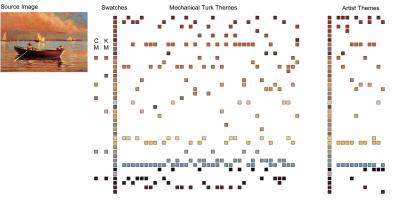
移步这里有对这个方法的思想和发展比较详细的介绍。 User study就是作者在这个众包平台上设置了40张图像,每个用户接受10张图像的任务,在基准色中找到图像的5个主题色。另外作为对比,作者又找了11个艺术系的学生执行相同的任务。 下图是一张图像的user study结果统计,能够看出用户所选的主题色和艺术系同学的还是差不多的,但是和自动方法选出来的颜色相差较大。如下图所示:
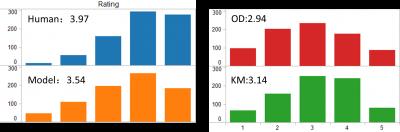
对于建模得到的主题色,作者又以user study去鉴定是不是和图像真实主题相近,由用户以评分的方式判断,对给出主题给出1到5分,5分是非常接近而1分是非常不接近。从下图能够看出建模得到颜色和用户组的打分都广受好评(左上角标出平均分),而其它两种方法则稍显劣势。如下图所示:
最后来看下对新图像的建模情况对比:能够看出文章方法能够提取出一些像素覆盖度不是很高,但是在视觉上比较显著的区域,如蝴蝶的白色以及海上的红色太阳等等。如下图所示:
最后文章给出了这79个特征的权重,似乎就能够用于类似于基于主题色的图像检索一类的应用。但实际上,由于视觉显著性是通过用户的眼动跟踪数据得到的,所以不能对没有视觉显著性的图像进行建模,就大大降低了可用性。如果对这个特征进行改进的话,就能让这个方法得到更广泛的应用。 关于本文的几点补充: 1.Eurovis的文章针对数据实体本身的颜色语义和设计图元所对应颜色的一致性的问题,比如是水果的数据,那蓝莓就用蓝色,香蕉就用黄色等,感兴趣的看官可以看原论文。 2.之前视物致知已经报道过这篇文章,这篇博文则是从学术角度重新审视这篇文章。
|

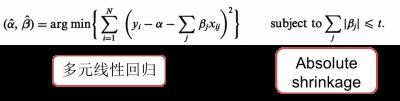



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved