 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Apache Spark源码走读:怎样进行代码跟读
发布日期:2016-3-13 21:3:45
Apache Spark源码走读:怎样进行代码跟读 概要 今天不谈Spark中那些复杂的技术实现,只稍为聊聊怎样进行代码跟读。我们都知道,Spark使用scala进行开发,由于scala有众多的语法糖,很多时候代码跟着跟着就觉着线索跟丢掉了,另外Spark基于Akka来进行消息交互,那怎样知道谁是接收方呢? 一、new Throwable().printStackTrace 代码跟读的时候,经常会借助于日志,针对日志中输出的每一句,我们都很想知道它们的调用者是谁。但有时苦于对spark系统的了解程度不深,或者对scala认识不够,一时半会之内不能找到答案,那么有没有什么简便的办法呢? 我的办法就是在日志出现的地方加入下面一句话,如下图所示:
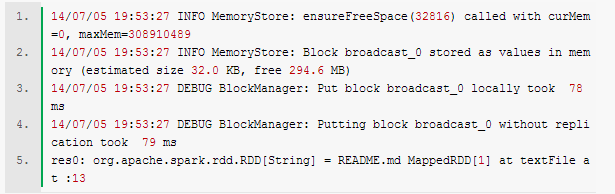
现在举一个实际的例子来说明问题。 比如我们在启动spark-shell之后,输入一句非常简单的sc.textFile("README.md"),会输出下述的log,如下图所示:
那我很想知道是第二句日志所在的tryToPut函数是被谁调用的该怎样办? 办法就是打开MemoryStore.scala,找到下述语句,如下图所示:
在这句话之上,添加如下图所示语句:
然后,重新进行源码编译,如下图所示:
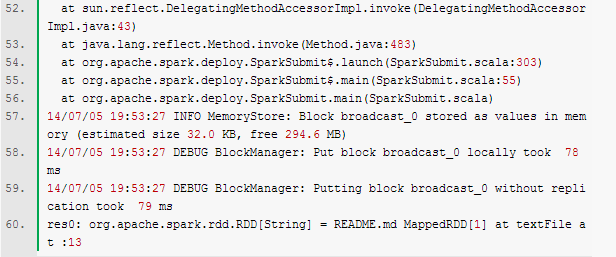
再次打开spark-shell,执行sc.textFile("README.md"),就可以得到如下输出,从中能够清楚知道tryToPut的调用者是谁,如下图所示:
二、git同步 对代码作了修改之后,如果并不想提交代码,那该怎样将最新的内容同步到本地呢?如下图所示:
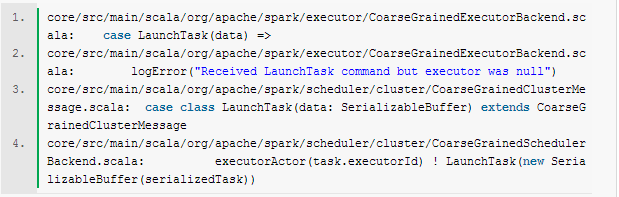
三、Akka消息跟踪 追踪消息的接收者是谁,相对来说比较容易,只要使用好grep就可以了,当然前提是要对actor model有一点点了解。 还是举个实例吧,我们知道CoarseGrainedSchedulerBackend会发送LaunchTask消息出来,那么谁是接收方呢?只需要执行如下图所示脚本就可以了。
从如下的输出中,能够清楚看出CoarseGrainedExecutorBackend是LaunchTask的接收方,接收到该函数之后的业务处理,只需要去看看接收方的receive函数就可以了。如下图所示:
小结 今天的内容相对简单,没有技术含量,自己做个记述,免得时间久了,不记得。 上一条: 浅析分布式系统是怎样的
|











 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved