 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Flynn初探:基于Docker的PaaS平台
发布日期:2016-2-29 11:2:7
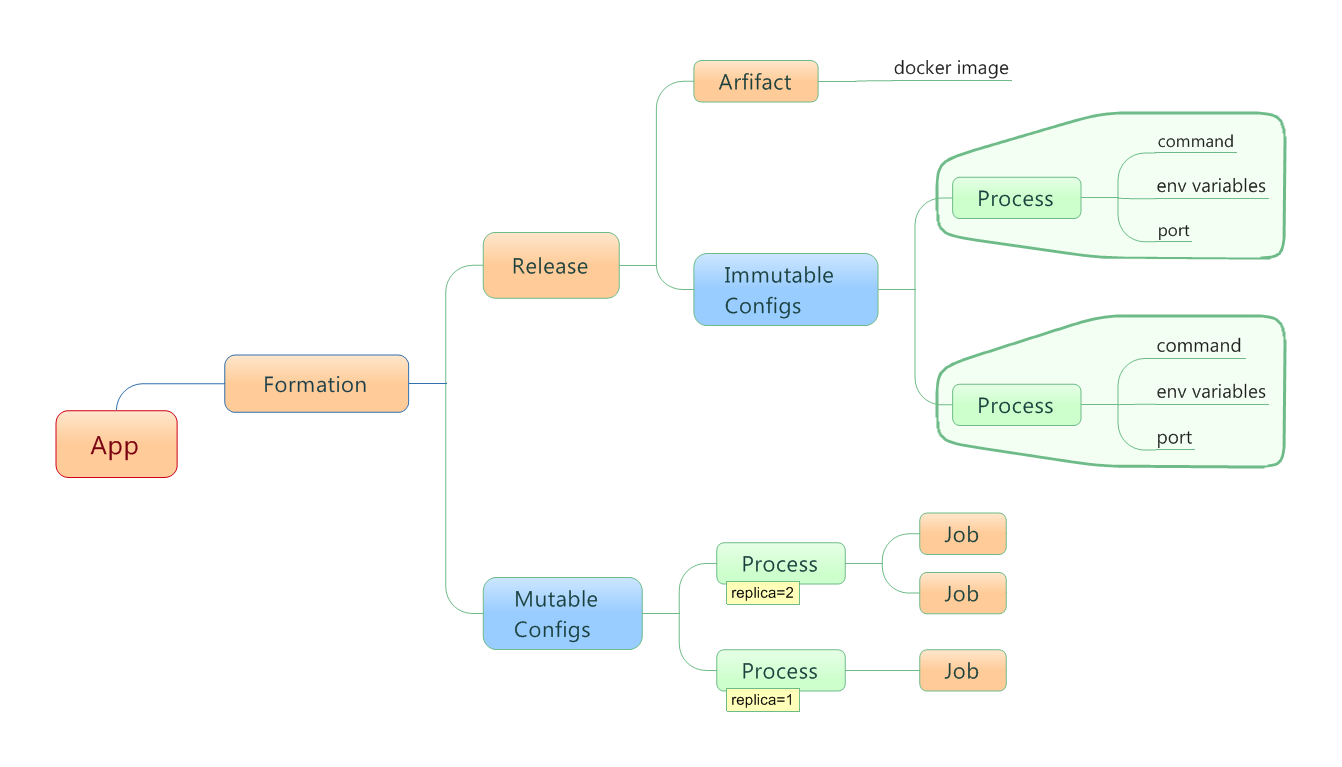
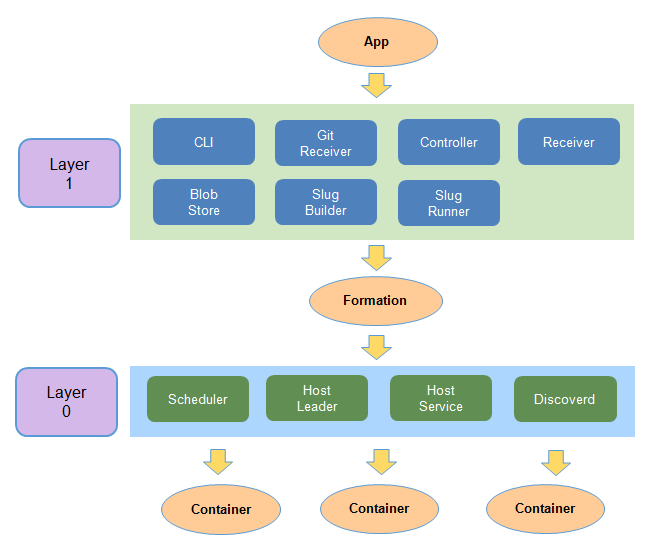
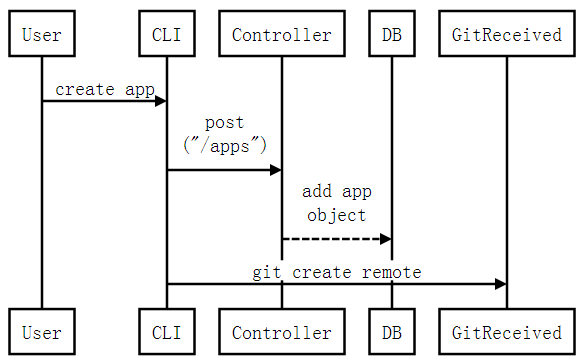
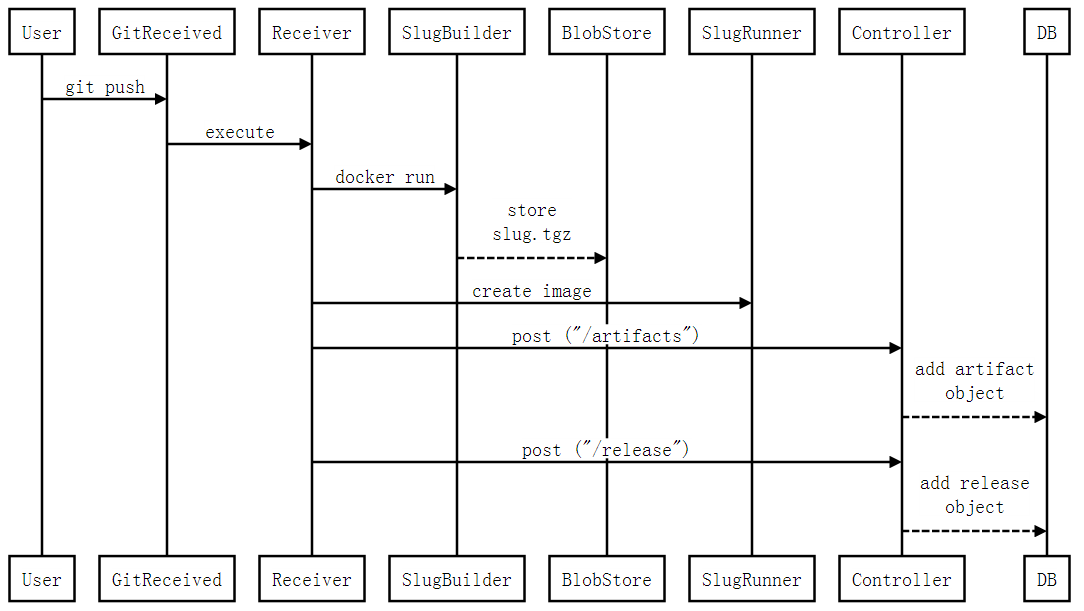
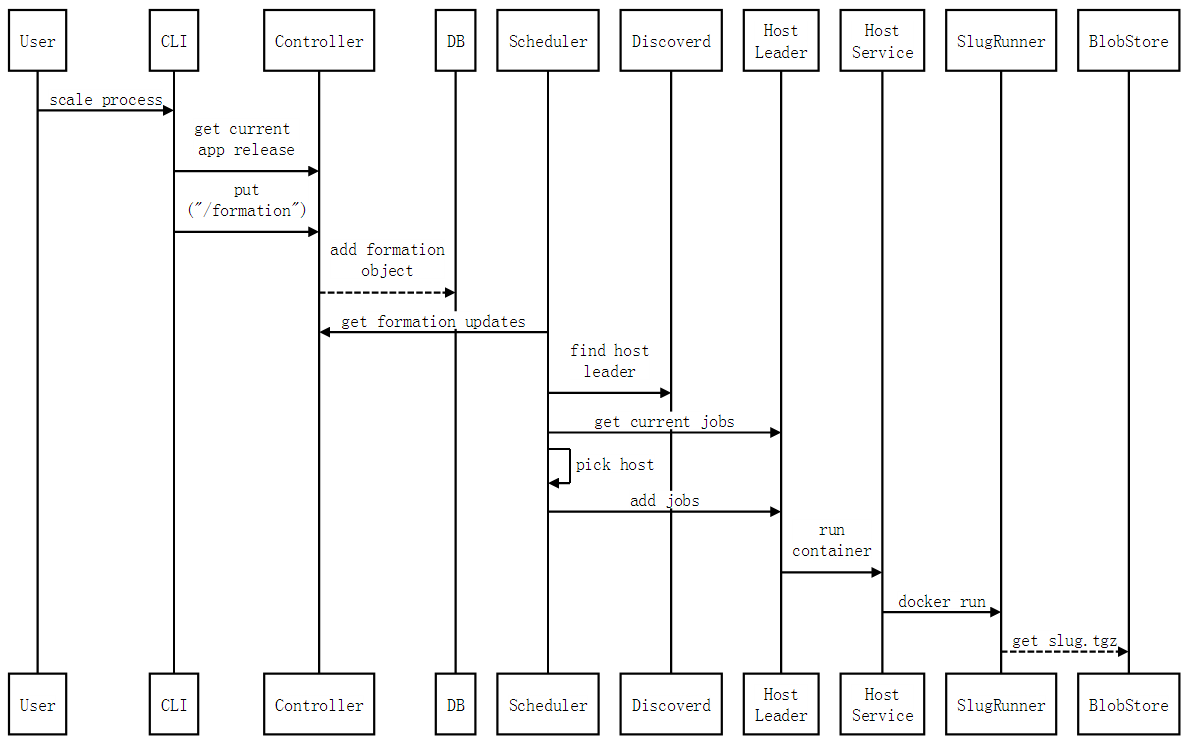
Flynn是一个开源的PaaS平台,可自动构建部署任何应用到Docker容器集群上运行,其功能特性与组件设计大量参考了传统的PaaS平台Heroku。本文旨在从使用动机、层次架构、基本对象、功能组件、基本工作流这几个方面对Flynn做总体的介绍。 为什么需要Flynn 为了便于理解Flynn的作用与功能,让我们先来看看应用程序从开发到构建再到部署再到运行分别需经历的几个实体状态: 更具体一点,以一个Java程序为例来描述: 进程:运行Java程序的实体。一个Java程序可以起多个进程,每个进程启动不同的主类(实现了main()方法的类,一个JAR包可以包含多个主类)。 源代码:包括*.java、log4j.properties、pom.xml等文件。 部署配置:比如每个进程的启动命令、环境变量、系统属性等。通常,这些配置会写在一个启动脚本里面。 发布包:源代码被编译打包后生成一个JAR包,这个就是发布包。 引入Docker后,发布包变成封装了JAR包与JDK环境的镜像,进程变成在相互隔离的容器里运行。但从源代码到镜像、从镜像到运行容器这两步转换过程需要用户人工的操作。尤其是后者的转换,涉及到集群资源调度、配置管理、自动部署、容器管控等一系列的复杂流程。更进一步,在运行阶段还涉及扩缩容、错误处理、日志查看、运行监控等运维需求,若全部人工操作将耗费巨大的工作量。 此时类似Flynn这样的PaaS出场了,基于Docker之上进一步封装了整个构建、部署、运行工作流,使得用户只需要简单地提交代码就可以完成开发到运行的快速转换: 开发到构建:用户通过git提交源代码,由Flynn自动构建镜像,并提供版本的管理——用户可以创建新版本(提交新代码或修改部署配置)、回滚老版本等。 部署到运行:Flynn自动选择运行机器(如阿里云主机),为每个进程副本部署启动单独的容器,并提供进程的管理——用户可以做扩缩容、查看日志、监控状态等。 Flynn的基本对象 下面我们来看看发布包、部署配置、进程这三个实体在Flynn中是怎样抽象的。如下图所示是其基本对象的关系描述: App:表示一个应用,所有其他对象都是围绕App而展开。 Artifact:表示应用的发布包,实际上对应一个Docker镜像。 Formation: 是应用运行态的抽象表示。它在Release的基础上增加了可变(mutable)的动态配置,即每个进程的副本(replica)个数。 Job: 是进程副本的抽象表示,每个Job对应一个运行容器。因此,在后文中可以看到,Job是资源调度的基本单元。 Process:表示应用的进程。通过一个镜像可以启动多个不同的进程,每个进程运行在自己单独的容器里。 Release:是应用发布态的 抽象表示。它在Artifact的基础上增加了一些不可变(immutable)的静态配置,比如每个进程的启动命令行、环境变量、绑定端口、等。要修改 这些配置,需要生成一个新Release。Release这种不可变性是为了方便做Rollback,即应用随时可以回退到之前的Release。 Flynn的层次架构 如下图所示,Flynn的架构自下而上分为两个层级——Layer 0和Layer 1。简单地理解,可以认为Layer 1负责接受用户请求,封装成应用的运行指令,再由Layer 0解决在哪里运行、以什么方式运行的问题。具体一点讲,Layer 0面向的对象是Formation,负责将底层的集群资源封装成可执行Formation的一台主机;Layer 1面向的对象是App,负责将App从源代码构建成Artifact,进而封装成Formation提交给Layer 0去执行。 这种分工明确的层次划分,使整个系统非常灵活,相互松耦合,便于任意组件的替换(比如,甚至可以把Layer 0替换成不用容器去执行Formation)。 Flynn的功能组件 下面总结一下组成两个层级的各个组件及其功能(所有组件自身都可以运行在容器里): Layer 0 Discoverd:基于etcd的服务发现模块,提供容器间的发现机制。实际上,Flynn自身的组件间通讯也是通过Discoverd来相互发现的。 Host Leader:一个特殊的Host Service,做为"cluster leader",负责维护整个集群的状态信息(比如有哪些机器、每台机器上运行的Job等),并提供给Scheduler用于资源调度。 Host Service: 运行在集群每台机器上的agent,负责管控运行在本机(如阿里云主机)的容器,并收集运行状态信息。 Scheduler: 资源调度器,定期从Layer 1获取Formation的更新,再根据每个Formation的部署配置生成一个个的Job,最后从集群中选择合适的机器去运行这些Job。 Layer 1 BlobStore: HTTP文件服务器,用于上传/下载slug包。 CLI:提供给用户使用的命令行工具。 Controller:为Flynn系统的入口, 封装了核心对象(比如app/artifact/release/job)的增删改查操作,以RESTFul接口方式提供给外部客户和内部组件调用。它维 护的REST对象将持久化到postgre数据库。Layer 0的Scheduler就是通过Controller的接口来获取Formation更新的。 GitReceiver:接受用户git push源代码的SSH服务器。接受到git push后将触发Receiver。 Receiver:基于buildpack机制, 利用SlugBuilder从源代码包构建slug包。buildpack和slug都是从Heroku借鉴过来的概念。简单地理解,buildpack 是一组用于构建源代码的脚本,buildpack可以多种多样,每个buildpack可构建某种类型的源代码,这种类型可以是不同的语言(比如 Java、PHP)、不同的构建方式(比如maven、gradle);而slug则是buildpack构建生成的部署包,包含了编译输出文件、依赖库 文件等运行环境。 SlugRunner:运行slug包,会从BlobStore下载应用的slug包。 SlugBuilder:接受源代码包,基于某种buildpack构建生成slug包。选择哪一种buildpack可以显式地指定,也可以由SlugBuilder根据源文件自动匹配。 Flynn的工作流 下面通过一个例子来展示Flynn各个组件的工作流。使用Flynn来构建部署应用最基本的流程是以下三步: 1、用户创建app: flynn create myapp 2、用户提交app代码: git push flynn master 3、用户扩容app的进程: flynn scale web=2 对比Kubernetes Kubernetes是Google开源的Docker容器集群管理系统,为容器化的应用提供资源调度、部署运行、服务发现、扩容缩容等整一套功能,更详细地介绍请参考作者的另一篇文章《Kubernetes初探:原理及实践应用》。 在应用的抽象上,Flynn与Kubernetes有本质的区别:Flynn的应用管理单元是App,只对应一个Docker镜像,但可由这个镜像来启动多个进程,并且每个进程可以单独扩缩容;而Kubernetes的应用管理单元是 Pod,可对应多个不同的Docker镜像,并且Pod内的各个容器保证会运行在相同的机器上,整个Pod作为扩缩容的基本单位。 另外一个根本的区别是Kubernetes不提供镜像构建与版本管理的功能。因此,Kubernetes只能看成是面向容器而不是面向应用的系统。当然,我们可以在Kubernetes之上扩充这些功能。 对比Deis 与Flynn类似,Deis也是受到Heroku的启发,基于Docker之上构建的PaaS平台。因此,从功能特性到应用抽象,两者是大同小异。 至于两者的差异,了解不是很多,这里提三点: 第一,Deis是用Python开发的, 而Flynn是Go; 第二,Deis依赖于CoreOS,而Flynn因为所有组件都可运行在容器里,没有OS的依赖; 第三,Deis在构建阶段,除了 buildpack方式构建外,还支持Dockerfile与镜像直接上传两种方式,相对Flynn更为灵活。 原文出自:http://blog.csdn.net/zhangjun2915/article/details/41266133
|





 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved