 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Docker底层实现概览
发布日期:2016-2-27 20:2:29
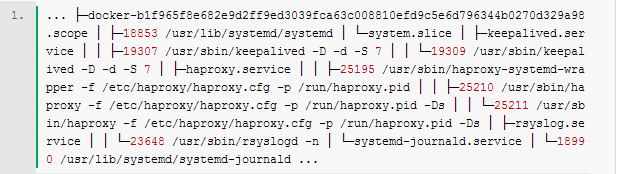
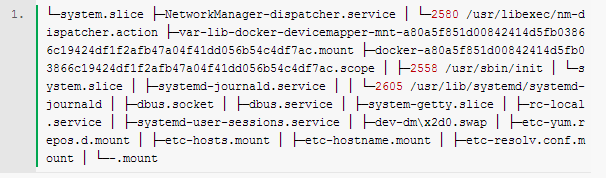
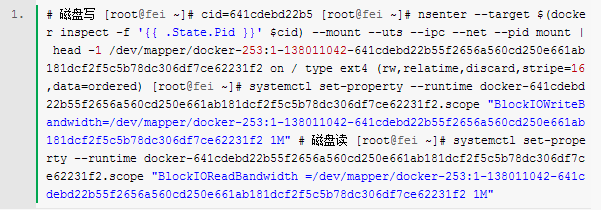
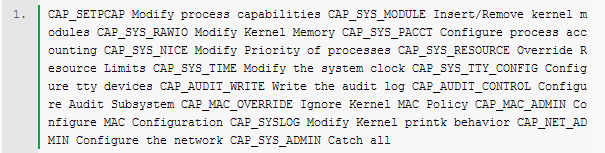
Docker解决了云(如阿里云)计算环境难于分发并且管理复杂,而用KVM、Xen等虚拟化又浪费系统资源的问题。Docker最初是基于lxc构建了容器引擎,为了提供跨平台支持,后又专门开发了libcontainer来抽象容器引擎。但是无论是libcontainer还是lxc,其底层所依赖的内核特性都是相同的。我们来看看docker都使用了技术来实现容器引擎的。 命名空间 Docker使用了pid、network、ipc、美mnt、uts等命名空间来隔离网络、文件系统、进程等资源。注意,由于Linux并不是namespace了所有东西(如cgroups、/sys、SELinux、/dev/sd*、内核模块等),仅靠这几个namespace是无法实现像KVM那样的完全资源隔离的。 pid namespace:实现进程隔离,容器只能看到自己的进程,并且每个容器都有一个pid为1的父进程,kill掉该进程容器内的所有进程都会停止; net namespace:实现网络隔离,每个容器都可以设置自己的interface、routers、iptables等;docker默认采用veth的方式将container中的虚拟网卡同host上的一个docker bridge: docker0连接在一起; ipc namespace:container中进程交互还是采用linux常见的进程间交互方法(interprocess communication - IPC), 包括常见的信号量、消息队列和共享内存。然而同 VM 不同的是,container 的进程间交互实际上还是host上具有相同pid namespace中的进程间交互,因此需要在IPC资源申请时加入namespace信息 - 每个IPC资源有一个唯一的 32 位 ID; mnt namespace:类似chroot,将一个进程放到一个特定的目录执行。mnt namespace允许不同namespace的进程看到的文件结构不同,这样每个 namespace 中的进程所看到的文件目录就被隔离开了。同chroot不同,每个namespace中的container在/proc/mounts的信息只包含所在namespace的mount point; uts namspace:允许每个container拥有独立的hostname和domain name, 使其在网络上可以被视作一个独立的节点而非Host上的一个进程; user namespace:每个container可以有不同的 user 和 group id, 也就是说可以在container内部用container内部的用户执行程序而非Host上的用户。 对于容器所依赖的内核文件系统(这些都是non-namespaced),为了保证安全性,docker将其限制为只读的: cgroups机制 cgroups 实现了对资源的配额和度量。 cgroups 的使用非常简单,提供类似文件的接口,在 /cgroup目录下新建一个文件夹即可新建一个group,在此文件夹中新建task文件,并将pid写入该文件,即可实现对该进程的资源控制。groups可以限制blkio、cpuset、cpu、cpuacct、devices、freezer、memory、net_cls、ns九大子系统的资源,以下是每个子系统的详细说明: blkio 这个子系统设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及usb等等。 cpuset 如果是多核心的cpu,这个子系统会为cgroup任务分配单独的cpu和内存。 cpu 这个子系统使用调度程序为cgroup任务提供cpu的访问。 cpuacct 产生cgroup任务的cpu资源报告。 devices 允许或拒绝cgroup任务对设备的访问。 freezer 暂停和恢复cgroup任务。 memory 设置每个cgroup的内存限制以及产生内存资源报告。 net_cls 标记每个网络包以供cgroup方便使用。 ns 名称空间子系统。 对于centos7来说,通过systemd-cgls来查看系统cgroups tree: 特权模式下的容器: cgroups配置方法: 1) cpu相对权重:docker run -it --rm -c 512,如果未设置,默认为1024 若在容器开启时没有设置cpu权重,可以在容器启动后修改,如 2) 设置cpu pin:docker run -it --rm --cpuset=0,1 3) 内存限制: docker run -it --rm -m 128m,默认swap为mem的两倍 若不设置-m 128m,则默认容器内存是不设限的 4) 磁盘IO限制,docker本身默认没有做磁盘io的限制,不过我们可以通过直接操作cgroups来实现 5) 磁盘大小,docker容器默认都会分配10GB的空间,如果想改变这个值,需要修改docker服务启动参数,并重启docker服务:docker -d --storage-opt dm.basesize=5G。其他磁盘相关的配置可以参考https://github.com/docker/docker/tree/master/daemon/graphdriver/devmapper。 Capability机制 Linux把原来和超级用户相关的高级权限划分成为不同的单元,称为Capability,这样就可以独立对特定的Capability进行使能或禁止。通常来讲,不合理的禁止Capability,会导致应用崩溃。 Docker默认为容器删除了以下capability: 若确实需要这些capability,可通过--cap-add or --cap-drop添加或删除,如docker run --cap-add all --cap-drop sys-admin -ti rhel7 /bin/sh。 Union FS 对于这种叠加的文件系统,有一个很好的实现是AUFS,在Ubuntu比较新的发行版里都是自带的,这个可以做到以文件为粒度的copy-on-write,为海量的container的瞬间启动,提供了技术支持,也会持续部署提供了帮助(注意,centos7系统是基于devicemapper来实现类似的功能的)。 AUFS支持为每一个成员目录(类似Git Branch)设定readonly、readwrite 和 whiteout-able 权限, 同时 AUFS 里有一个类似分层的概念, 对 readonly 权限的 branch 可以逻辑上进行修改(增量地, 不影响 readonly 部分的)。通常 Union FS 有两个用途, 一方面可以实现不借助 LVM、RAID 将多个disk挂到同一个目录下, 另一个更常用的就是将一个 readonly 的 branch 和一个 writeable 的 branch 联合在一起,Live CD正是基于此方法可以允许在 OS image 不变的基础上允许用户在其上进行一些写操作。Docker 在 AUFS 上构建的 container image 也正是如此。 Iptables, netfilter 主要用来做ip数据包的过滤,比如可做container之间无法通信,container可以无法访问host的网络,但可通过host的网卡访问外网等这样的网络策略 SELinux SELinux是一个标签系统,进程有标签,每个文件、目录、系统对象都有标签。SELinux通过撰写标签进程和标签对象之间访问规则来进行安全保护。 setrlimit 可以限制container中打开的进程数,限制打开的文件个数等 原文出自:http://blog.csdn.net/feiskyer/article/details/41246657 上一条: AWS re:Invent 2014回顾 下一条: Cloud Setuper 三剑客
|









 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved