 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Redis 源码深度剖析
发布日期:2016-4-26 16:4:40
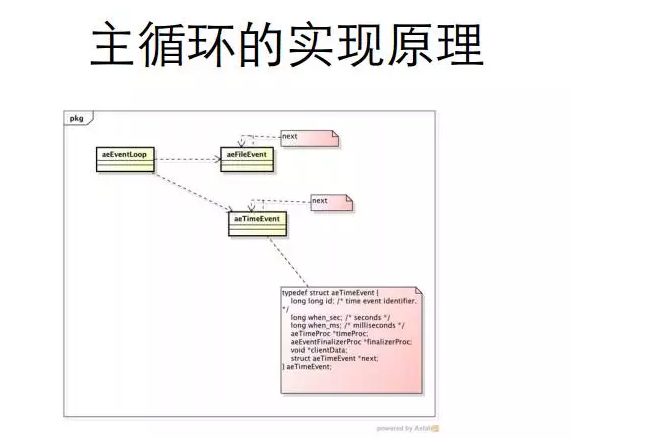
原文链接:http://t.cn/RyuxZQJ 其实Redis 很简单,懂 C 语言的同学花一个下午,就可以把它的来龙去脉都研究懂。但是,它麻雀虽小五脏俱全。一个常见的软件,例如 Redis,跑起来该用的东西可能都用一些,如果我们把 Redis 搞懂了,要分析一款其他的软件,思路可能也是差不多的,所以我借这个机会,跟大家分享一下我们解剖一个软件的过程。 本文分享 Redis,主要通过以下所示的几个步骤。 一、 启动过程 如图1所示: 首先,我们来看一下 Redis 的一个启动过程。任何一款软件,它的很多C语言实现的过程,都是从 main 函数这个漏斗开始的。一般任何软件设计的时候,不管是 Redis,还是阿帕奇,或乱七八糟的东西,一般 Main 函数都定义在跟它软件名字一样的. C 文件里面,里面 main 函数执行的过程分以下的几步: 1.Redis 会设置一些回调函数,当前时间,随机数的种子。回调函数实际上什么?举个例子,比如 Q/3 要给 Redis 发送一个关闭的命令,让它去做一些优雅的关闭,做一些扫尾清楚的工作,这个工作如果不设计回调函数,它其实什么都不会干。其实 C 语言的程序跑在操作系统之上,Linux 操作系统本身就是提供给我们事件机制的回调注册功能,所以它会设计这个回调函数,让你注册上,关闭的时候优雅的关闭,然后它在后面可以做一些业务逻辑。 2.不管任何软件,肯定有一份配置文件需要配置。首先在服务器端会把它默认的一份配置做一个初始化。 3.Redis 在 3.0 版本正式发布之前其实已经有筛选这个模式了,但是这个模式,我很少在生产环境在用。Redis 可以初始化这个模式,比较复杂。 4.解析启动的参数。其实不管什么软件,它在初始化的过程当中,配置都是由两部分组成的。第一部分,静态的配置文件;第二部分,动态启动的时候,main,就是参数给它的时候进去配置。 5.把服务端的东西拿过来,装载 Config 配置文件,loadServerConfig。 6.初始化服务器,initServer。 7.从磁盘装载数据。 8.有一个主循环程序开始干活,用来处理客户端的请求,并且把这个请求转到后端的业务逻辑,帮你完成命令执行,然后吐数据,这么一个过程。 二、服务器的模型 如图2所示: 接下来看一下 Redis 服务器的模型。Redis 实现的过程当中,基于不动的操作系统,封装了不同的模型。举个例子,它在 Linux 上面是基于 epoll 做了一个封装,不管怎么样,它都是以 ae_epoll.c 封装的。封装过程当中有三个步骤,我们用原生调用 epoll 的时候也是三个步骤完成。第一个步骤,aeApiCreate,就是 epoll 的一个池子,先创建了一个池子的东西。第二、通过 ApiAddEvent 调用 epoll 这个函数,可以往 epoll 池子里面注册事件。第三、ApiPoll,通过 epoll_wait 来获取已经响应的事件。 三、Redis 在服务端初始化 epoll 如图3所示: 首先,在 main 函数初始化过程当中调用了 innitServer,其实就是调用刚才讲的 aeCreateEvent ,创建了 epoll 池子。然后调用函数,设定 EVENTLOOP_FDSET_INCR。然后设置回调函数,注册的事件响应之后要干活,这是一个循环调用的过程。如何调呢?我们把 aeCreateEvent 这个函数展开,里面有两个过程,Event如果这个死循环在调用的过程当中,可以跟两类事件发生交道。第一类事件,aeflieEvent。第二类事件,aeTimeEvent。由于 Redis 针对 epoll 再做一次封装的时候,它实现了一个定时器,这个定时器可以把你想要注册到这个定时器里面的一些事件注册进去。举个例子,比如内存淘汰的时候,是一个 LRU 的一个算法,你注册到这个定时器,比如内存达到某个大小,比如限制两兆,当它大于两兆的时候要淘汰,这个时候定时器在这个场景下面就会发生作用。 四、主循环的实现原理 如图4所示; Redis 真正的主循环的原理,大致可以分成以下三步: 1.查找一些优先要处理的事件。什么叫优先要处理?你在调用API的时候,这个 API 可能作为 Redis 的使用者不会去关注。但是作为 Redis 的开发者他可能会关注到。你首先要让 Redis 执行一个东西,它这个时候会优先去做处理。 2.假如说没有优先处理实践,则执⾏aeApiPoll 来处理 epoll 中的就绪事件。 3.处理定时器任务。 五、服务器整体架构图 如图5所示;
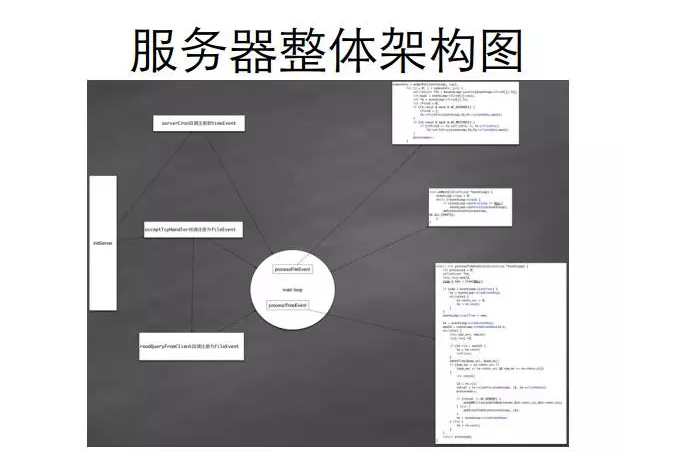
我们可以通过图5这张图回顾一下它整体服务器的架构,其实就是这么一回事。最中间圆圈,代表了一个死循环。死循环要跑的时候,要干哪些活?我们把逻辑注册到某个池子里面,比如注册到 epoll 的池子里面,或注册到定时器当中。它都是通过一些回调函数注册的。比如 TCP 的时间要响应,就不停的执行,这么一个过程,Redis 本身实现也不是太复杂。 当你启动 Redis 的时候,它本身就是一个单进程,单线程的模式。所以,我们在事件处理过程当中,要做到非常小心,精确的做一些控制,因为你的事件一旦进到 Redis 里面,比如我们简单的让 Redis 做一个技术器加法运算,如果加法运算时间花的很多,后面的规模可能就一直等在那里,执行不下去了,因为它是单线程,单进程的。所以说,如果你让 Redis 同步在执行的过程当中,它必然是 CPU 密集型的运算,而且能很快计算完毕,把结果推送给你。 六、请求协议 如图6所示: 其实请求的协议,在前面 main 函数执行过程当中会 initSever,在 initSever 过程当中我们会注册一个 acceptTcpHandler 回调函数,然后这个函数就会被调用了。Redis 请求协议分称以下两种:
如果不是各*开头,就是 inline 协议。 首先,看 inline 的协议,调用 processInline 这个函数比较简单,当你把数据发送给服务端,任何的软件都会把这个数据丢到一个缓存区,Redis 里面有一个 querybuf 结构,执行到缓存区,然后存入到 client 的 arg 数组,argc 代表了参数的格式。processMultibulkBuffer 协议,我们这里有三个参数的数量,比如 3,指的是长度 3,具体就是这么一个过程。如图7所示: 当我们把这数据完全解析完之后,这个时候就知道它是什么命令了。比如刚才 Set 命令已经解析完,我们知道它是一个 Set 命令,并且知道它的参数是什么。这时候我们会调用 processcommand 这个函数,执行的过程分成以下所示的 12 个步骤:
在命令真正的执行过程当中,Redis 分成了两个步骤。第一种,假如已经用了刚才讲的事务处理模式,Redis 会把命令在 Q 里面存起来。所以,真正到 EXEC 之前,打开事务模式,把丢过来的命令先在 Q 存起来,真正执行的时候再执行。第二种,假如不是事务模式,这个时候它就会去真正调用这个 proc 函数,把 Redis 命令真正在后台执行。例如,刚才提到的事务模式,通过 MULTI 关键词输入,后面就起到命令模式,如果后面不调用,它就不会真正执行。 七、命令执行过程 如图8所示:
刚才事务执行时候的命令过程,会把队列里面的命令一个一个拿出来,然后去执行的过程。一个正常命令的执行过程,主要是分成以下几个步骤:
AddReply 会注册写事件到 epoll 里面去,通过 prepareClientToWrite。第二、会调用 _addReplyToBuffer 数据写到 buf 中。下一次执行的时候才会循环这个动作,这样每次做的时候,TPS 在单线程,单进程的情况下还能达到理想的状况。第三、假如 buf 为不够大,会添加到链表里面去。 其实 RedisDb 最最核心的实现就是一个置顶的实现,跟mysql一样,比如有存数据的置顶,就是要不要过期,其实也是存在置顶里面。举个例子,有些请求它其实会阻塞的,阻塞到哪里?有一个阻塞器置顶。当阻塞已经就绪了,有一个就绪的 1 K的置顶,还可以坚持某个 K。置顶的具体实现,就不再讲了。 九、核心数据结构 如图9所示
由于我们最终服务器其实都跟核心的数据结构操作相关。首先,看 string 这个东西,其实 string 就是一个 struct 指针,可以描述长度,还剩余多少等等这些东西。看一下 struct 指针到底怎么指的,它会把 sdshdr 放到内存的前面,把 buf 放到内存的后面。Redis 检索怎么查找到 sdshdr 这个区域,一般通过目前 buf 最前置的指针减去 sdshdr 这个长度,就知道 sdshdr 在哪里。如图10所示 我们知道字符串其实就是一个 struct 结构,接下来看一下 hash 结构怎么实现的。hash 本质是基于 ziplist 的实现,关于 ziplist 的实现,ziplist 通过文本定义了一个数据结构。其实 ziplist 可以认为里面是一个一个的元素。我们理解 hash_max 的时候,有一个 hash_max_ziplist_value 的结构,就是通过这张图描述的这种方式把里面的东西捞出来了。当然,ziplist 在存储 hash 的时候,hash 通过两种方式存的。第一、ziplist 这种结构。因为 ziplist 具体的长度是可以设置的,当你的长度超过了某个数值之后,它就会转成 dict 的这个结构,最最原始的 dict 的结构,这样它存储的时候都存到 dict 的结构体里面去了。如图11所示: list 其实就是我们通常用的比较经典的这种双向链表,头指针,尾指针,定义了 list。接下来还有一个 set。其实 Redis set 还是存在 dict 这样的结构里面的,因为 list 只有 Velue 没有 Key。Redis 还有一个数据结构叫 Sorted Sets,它是为了加速检索的过程,用到以空间换时间的方式。举个例子,可能有些场景用搜索引擎构建的时候,觉得太麻烦,会建几张表做索引,其实 Sorted Sets 也是一样的,就是通过 span 结构实现了多级索引查询的过程。可以在这个 Velue 之上通过多级指针进行检索。Redis里面有一个 pub/sub_channels 这么一个属性,当有什么东西要给客户端的时候,会到这个队列里面查看有没有注册上来的客户端。 事务处理当中,可能还要注意以下几点:
持久化 rdb 的过程,其实 Redis 服务器分成两个步骤,第一、rdb 的持久化,第二、AOF 的持久化,基于 rdb 的持久化方式,服务器启动的时候,首先会调用 serverparamslen 的函数,然后 rdb 的工作会把内存里面存的数据,原封不动的拷贝,存储到本地磁盘当中去。rdbSave 不是让组件程序看这个活,我们需要 fork 一个子进程专门做 rdeSave 的数。
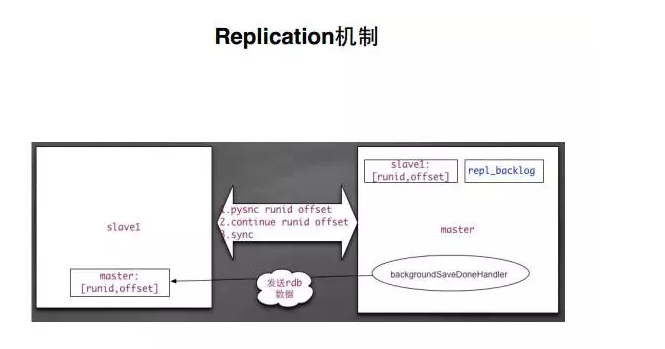
aof 存储的格式和刚才我们请求协议里面讲到的协议是一模一样的,就是纯文本的,比如 set 什么东西,就是一模一样的东西存在这个文件里面。假如开启了 aof 这个功能,会把你历史执行的命令记录原封不动都存在里面,这样这个文件会越来越大。当然,Redis 提供给我们一个功能,可以把 aof 命令压缩。在每次 Redis 重启之后,如果开启了 aof 功能,就会重载 aof 文件中的数据执行命令。然后 Redis 提供了 rewriteaof 定期压缩的功能,其实就是把 db 中的数据重新生成一份新的 aof。 Redis 的内存分配还是比较简单,不像 memorycash。Redis 通过调用原生的函数直接向操作系统申请内存。当内存不停的申请,在使用一段时间之后,Redis 会处罚一些淘汰的策略。这个淘汰分成两种,一种是主动淘汰,举个例子,当我们在调用 RandomKey 等这些函数的时候,首先会主动的淘汰一些内存,这个就叫主动淘汰。还有一种淘汰是 lru 的淘汰,当你在执行的过程当中,如果内存不够,就会处罚 lru 的淘汰算法。另外,还有被动淘汰,前面讲到因为我们在 main 函数调用真正的 epoll 死循环的前置有一个 beforeSleep,beforeSleep 函数里面会在 databasesCron 定时器都调用 activeExpireCycle。 十、Replication 机制 如图12所示:
RedisReplication 的机制,分为客户端请求和服务器的处理。我们启动客户端的时候,main 函数里面会调用 serverCron,在 serverCron 里又会调用ReplicationCron 这个函数,每隔一秒钟会触发这个函数。 Replication 机制的工作原理。假如说,我们支持 psync 这个协议,服务端会发送我现在的 runid 和 offset。相当于 rdb 同步到哪个地方了,会把 offset 发送给客户端,每个客户端都会保持一个 cashed_master 节点,就是长链接断掉之后,还会有一个 cashed_master 在。假如不支持 psync 协议,则发送 sync 协议。
十一、定制开发 Redis 如图13所示: 首先,在 Redis.c 文件找到 RedisCommandTable,添加命令,比如添加“test”,testCommannd,-5 的函数。 第二、添加命令处理函数。完了我们要修改这个 makefile 文件,最终编译打包。其实真正做的时候没有那么简单,因为 Redis 在内部,你在调用过程当中,会用到它很多内部的函数,类似mysql。所以,你要真正的完整开发定制一个 Redis,步骤是这样,但是需要把这些函数从头到尾学习一遍,如果你自己又去开发函数,会把 Redis 搞得乱七八糟,很糟糕,可能不一定能跑的很好。
上一条: MySQL常用维护命令与操作 下一条: MySQL 5.7 GA 版本正式发布
|













 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved