 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Web应用中数据库的基本概念
发布日期:2016-4-23 22:4:3
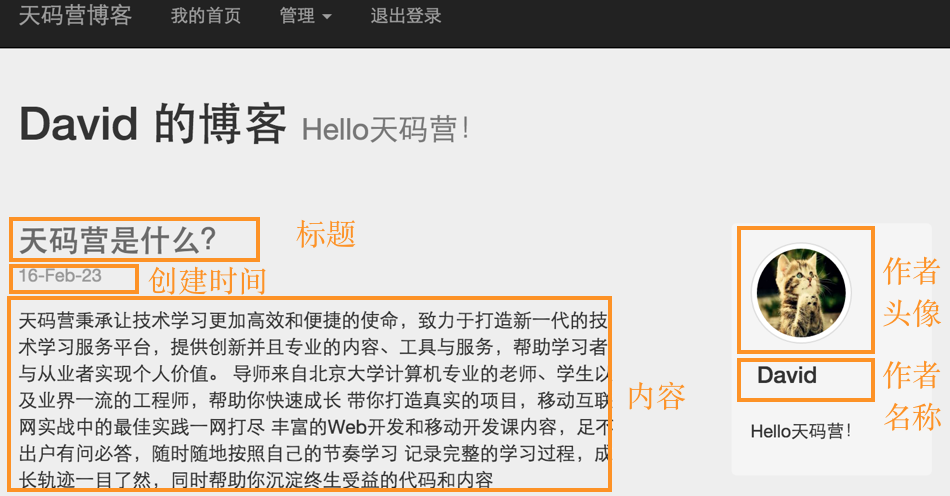
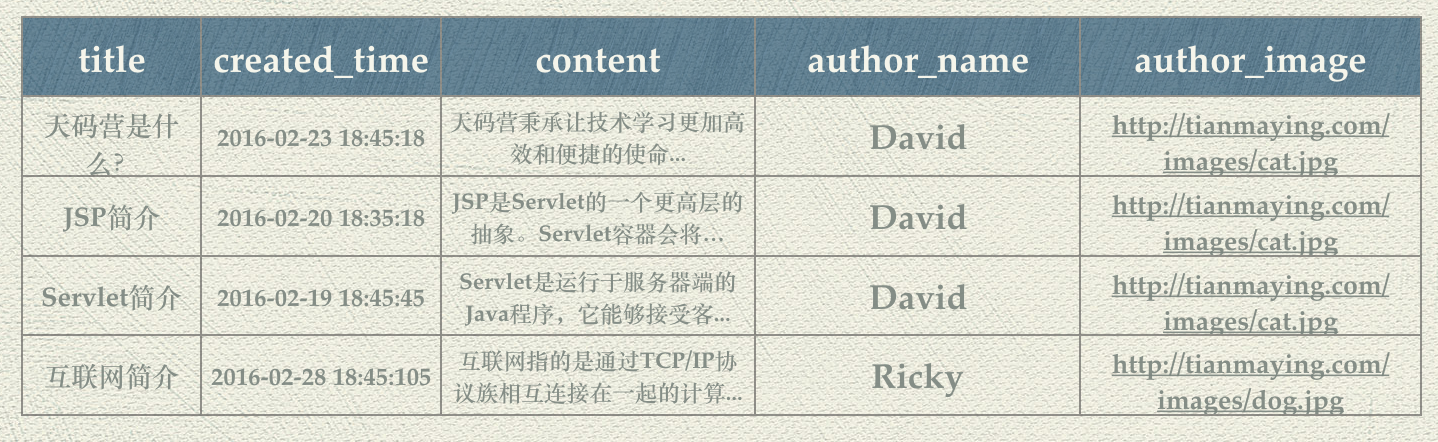
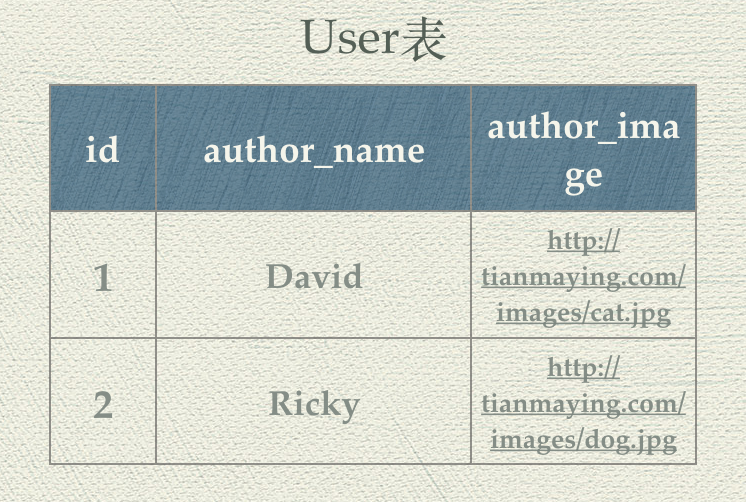
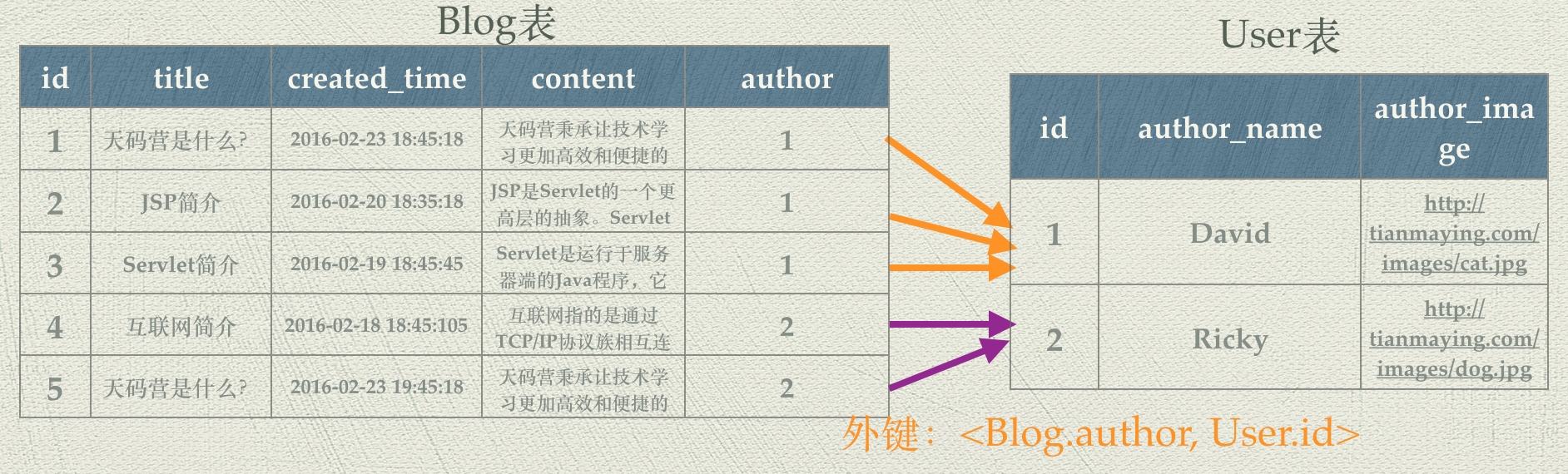
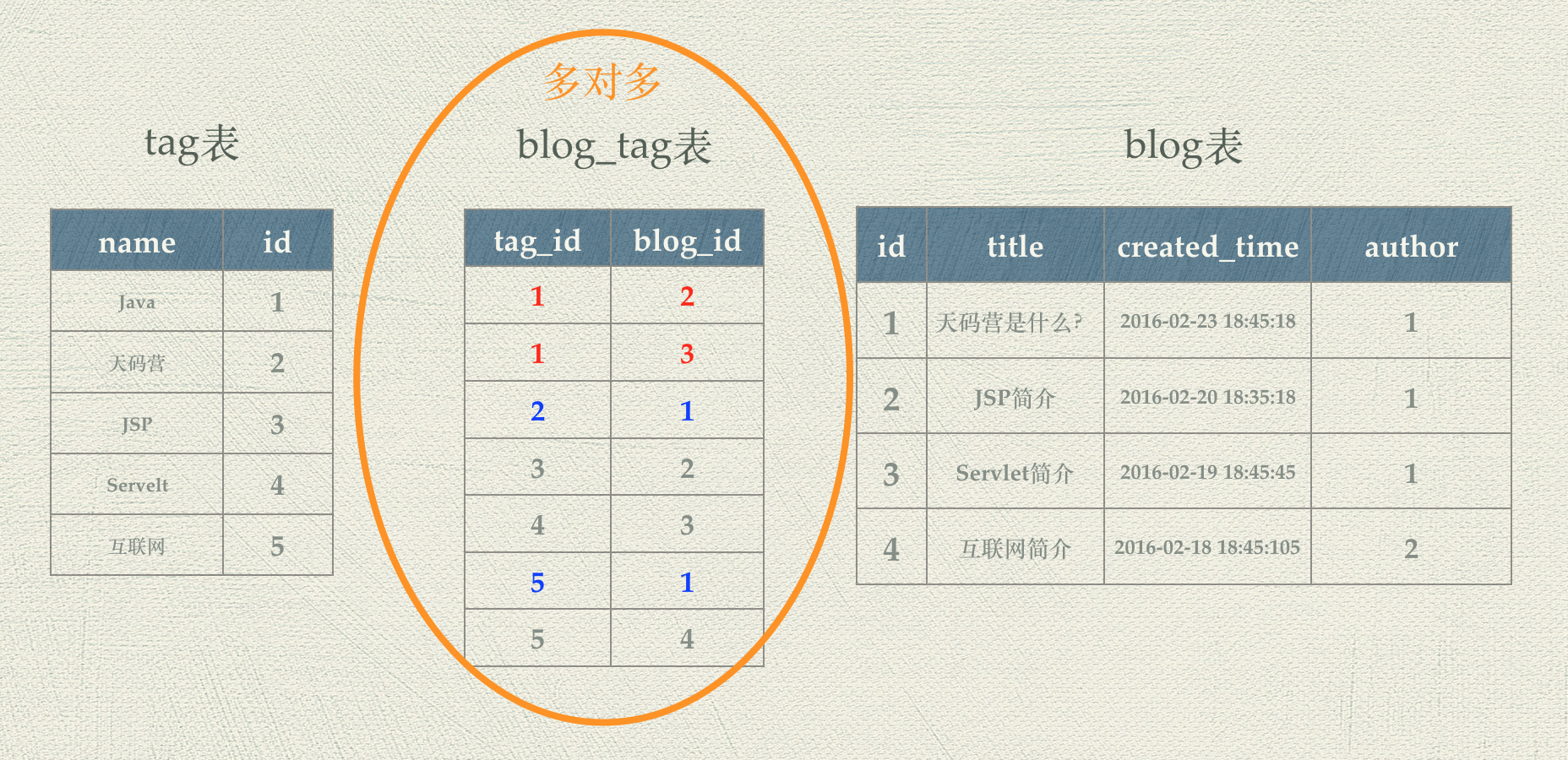
Web应用中数据库的基本概念 数据持久化 掌握了Servlet/JSP技术,我们已经可以创建动态的Web应用了。除了动态的Web界面,一个有价值的Web应用必然需要进行数据存储,开发上我们一般称之为数据持久化(Data Persistence)。从业务功能的角度出发,简单的应用可以认为就是数据的增删改查。比如一个产品级的博客应用,最核心的功能就是对博客内容的创建、修改、删除和查询,而这些功能都离不开Web服务器背后的数据库系统。 狭义地理解, “持久化”就是指把业务数据永久存储到数据库中;广义的来说,“持久化”包括和数据库相关的各种操作。将内存中的数据存入数据库就能够随时获取或者更新这些数据。所以让我们首先来了解一下数据库系统。 数据库简介 上个世纪60年代,数据库技术诞生,是计算机科学的一个重要的分支。当时计算机开始广泛地应用于数据管理,对数据的共享的要求越来越高。传统的文件系统已经不能满足人们的需要了。能够统一管理和共享数据的数据库管理系统(DBMS, Database Management System)应运而生。 DBMS的主要包括两个功能: 数据操纵功能:提供数据操纵语言(DML,Data Manipulation Language),用以实现对数据的基本操作(查询、插入、删除和修改) 数据定义功能:提供数据定义语言(DDL,Data Definition Language),用以定义数据库中的数据对象 数据库的运行管理和维护等,如数据的安全、完整性、并发和恢复等控制 自数据库从诞生以来,大致经历了以下几个阶段: 层次数据库与网状数据库 关系数据库 非关系型数据库 目前,非关系型数据库正在蓬勃的发展,比如Redis、MongoDB、BigTable等非关系型数据库已经被很多领域广泛的应用。 关系型数据库依然是Web开发中的主流数据库。我们将以使用最广泛的开源关系型数据库MySQL作为我们博客应用的数据库。 关系型数据库,是指使用关系模型来组织数据,使用集合代数等数学概念和方法来处理数据的一种数据库。在关系型数据库中,现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。不过我们这里先不深入其数学原理,我们以更形象的方式来理解关系型数据库的几个基本概念。 数据库表 关系可以认为就是一个二维表格,关系型数据库就是一组二维表格的集合,通过表格来描述和存数对象和对象之间的关系。 我们已经实现了博客页面,我们来分析一下这个页面: 从中我们看到,一篇博客至少具有以下信息: 博客标题 博客内容 创建时间 作者名称 作者头像 这些信息存储到数据库中,就这样一个blog表,如下图所示: 表中的每一列就是表的一个字段,对应Blog对象的一个属性;表中的每一张就是一条记录,对应于一篇具体的博客。 主键 数据存储起来之后我们需要非常方便得查询。接下来我们需要想一个问题:怎么才可以快速地识别出一条博客记录?一种方法是根据title来标识一条记录。如果Ricky也写了一篇名为“天码营是什么?”的博客呢?这时候title就不是唯一标识了。 这时我们可以给blog表,增加一个id字段,通过唯一的整数值来标识一条记录。能够唯一确定一条记录的字段就称为主键。 注意:多个字段可以一起作为一个表的主键,但是在开发中一般情况下我们使用自增的整数字段来作为主键。即每增加一条记录,记录的id的值就自动增加,这样就保证了每条记录的唯一性。` 字段的数据类型 表中的每个字段,与一个类的属性一样,具有数据类型。数据中有三种主要的数据类型:文本、数字和日期/时间类型。不同的数据类型拥有不同的特性,例如数字类型可以做一些数学操作,时间类型可以按照一定规则进行排序或筛选。同时,不同的数据类型在存储时是不一样,这就导致了不同的数据类型效率上有很大的差别。在后面的学习中,我们将会在数据库表的设计过程中讲解具体的数据类型,以及选择数据类型的最佳实践。 数据库表关系 一对一关系 我们可以把Blog的内容单独拿出来放在一张表中,命名为blog_content。那么blog_content和blog就是一对一的关系,一篇博客有其唯一的内容,一条内容也只会属于某一篇博客。 一对一关系相对不是很常见,但是依然有其应用场景。比如一篇博客信息中,占用空间的主要就是博客内容。将其独立出去,blog表的数据量就大大减小,在数据记录非常多时且如果需要频繁修改和访问blog表中的信息时,,可以极大的增加我们的读写效率。因为数据库表的存储的数据越少,读写效率越高。 一对多关系 观察Blog表中的数据,我们发现虽然只有David和Ricky两名作者,但是却出现了5次作者姓名和作者头像的信息,这样不仅浪费存储空间,带来潜在的不一致性等问题。 这样的表结构设计具有明显的不合理性。与类的设计需要符合面向对象的设计原则一样,表的设计也需要遵循一些范式来保证良好的表结构。 这里我们可以把作者的信息提取出来放到一个单独的user表中: 相应地需要修改blog表的结构: 我们发现blog表中多了一个author字段,保存的是User的id。这时就形成了一个外键约束。 我们说一个表具有外键,就是说表中一个字段或者几个字段的组合在另外一个表中是主键。回到场景中即:author有一个外键约束,外键是user表的主键id。 设置外键后,当往blog表中中插入数据时,数据库会自动检查插入数据的author字段,是否存在user表中存在对应的记录。如果不存在,数据库会抛出错误,拒绝插入,这样就可以保证数据的一致性和完整性。分为这样两个表同时也让分别维护博客信息和用户信息更为方便,处理逻辑得意分离。 user表与blog表是一种一对多的关系,其含义也很容易理解,一个用户可以创建多篇博客。其它两种关系我们在后面的内容中再行介绍。基于外键我们可以建立表与表之间的另外两种关系:一对一和多对多。 多对多关系 对后一种关系是多对多关系。假设我们希望给每篇博客设置标签,则一个标签可以对应多篇博客,一篇博客可以对应多个标签。标签数据可以通过定义个tag表来保存。而标签和博客的多对多关系,需要再单独定义一个表来描述,命名为blog_tag,这三个表如下所示: 从上图中可以看出,具有“Java”标签的文章有《JSP简介》与《Servlet简介》,对应blog_tag表的两条记录<1,2>,<1,3>;博客《天码营是什么》具有标签“互联网”和“天码营”对应1blog_tag1表的两条记录<2,1>,<5,1>。 总结 这节课我们学习了数据库的一些基础概念,我们可以大致的了解该如何针对一个需求来进行数据库的设计,我们已经有了一个感性的认识。具体如何操作来去创建一张数据库表以及创建他们之间的关系呢?接下来,我们先安装好MySQL数据库,然后学习如何通过结构化查询语言(SQL)来操作数据库。 上一条: MySQL性能优化的经验
|










 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved