 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 更新多行数据,然后把更新的结果读出来的SQL
发布日期:2016-4-23 22:4:35
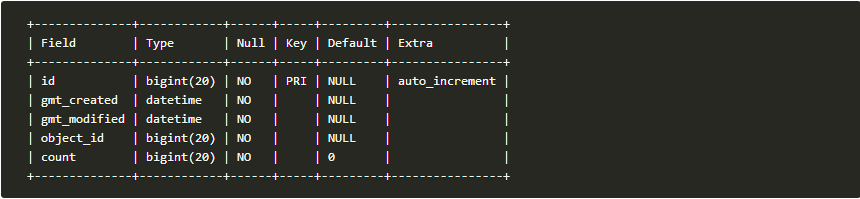
更新多行数据,然后把更新的结果读出来的SQL 考虑这样一种场景,可能还比较常见的:我们需要在关系数据库中更新一行或多行数据的多个字段,更新完了还不算,还得拿到被更新的某一个字段的结果。 再考虑这样一种场景:我们需要在关系数据库中更新一行或多行数据的多个字段,更新完了还不算,还得拿到这批被更新的记录的主键,以便操作其他的有关联的表。 这么说也许会比较抽象,就拿点赞计数来打个比方。 假设有这样一张表,就叫 likes 好了,记录了一个网站里面每个能被点赞的对象被赞的次数。id 是一个无业务含义的自增主键,gmt_xxx 分别是无业务含义的记录创建时间和记录更新时间。object_id 是能被点赞的对象的主键,相当于外键的作用,只不过由应用逻辑去保证关联表的数据一致性,数据库不感知;count 字段记录的是这个对象被赞的次数。 于是我们在页面上点了赞,前端页面就向后端服务 POST 一个请求, 后端服务要记录这次点赞行为。于是前端与后端工程师在点赞 API 的返回值上开始了讨论:是后端简单返回一个 OK 表示成功处理,前端收到 OK 后在页面上自行把点赞数 +1 呢,还是后端除了返回 OK 表示成功,还要返回当时这个对象的被赞次数,然后前端在页面上更新被赞次数? 做为一个后端工程师当然想实现为前者,一个 update 语句更新一下 gmt_modified 与 count 然后返回 OK 就搞定了,要不然还要多查一下。但是前端工程师就不乐意了,如果能让后端接口多返回点数据给前端多好,这么没头没脑的 +1 就把业务逻辑掺进来了,说好的后端负责数据前端负责展现呢。 前后端撕逼大战引起了产品经理的注意。产品经理说,返回当时的被赞次数能让用户感受到其他用户的热情,就这么定了,为了用户体验! 于是呢,后端工程师回去写出了这样的 SQL: update likes set gmt_modified = now(), count = count + 1 where object_id = ?; select count from likes where object_id = ?; 于是这样子就能写出基本满足功能的点赞 API 了! 注意到这两条 SQL 语句不在一个事务中,因此 select 语句拿到的 count 并不一定是它前面那条 update 更新的结果,可能被别的 update 更新了,所以用户不仅仅感受到了从点下鼠标开始,到数据库开始执行 update 这段时间内其他用户的热情,还感受到了从 update 执行后,到 select 开始执行这段时间内其他用户的热情。 发现这个问题以后,后端工程师就开始想,要是那个用户体验至上的产品经理觉得这个感受热情的时间窗口太长了,用户体验不好,想把后面那段从 update 到 select 的时间窗口拿掉,该怎么办?这个时间窗口要是有别的请求过来,数据肯定就污染了,得把别的请求挡在外面,没 select 完之前都别 update。 要如何把别的请求挡掉呢?加事务就可以了,而且事务隔离级别必须在 Read committed 及以上。事务一开始就用 update 给那一行用行锁给锁定了,别的请求只能等到 select 返回事务结束才可以去 update 同一行。 可是,为了这种小需求,这么随意就开一个事务,Code Review 的时候会被架构师驳回的吧?本来这种完全走索引的查询,服务器与数据库之间网络通信的时间开销就是数据库内查询的时间开销的好多倍,再来个 begin 与 commit 这两活宝,简直就是活生生把查询耗时翻倍的节奏。本来就只是在多表更新这种需要保证原子性的地方不得已开个事务,但是这种小需求也开事务的话,总有点杀鸡用牛刀的感觉。 网络通信的确是个麻烦事情,那么有没有办法把这个事务里面的网络通信开销减少一点呢?如果事务里面耗时减少,占用连接的时间就会相应减少,系统就可以承载更多的并发请求! 存储过程?如果把 begin,select,update,commit 四个语句写到一个存储过程里面,网络通信次数就从四次减少到一次,性能也就提升 75%!想归想做归做,之前总听架构师说,我们的系统是互联网架构,如果没有什么特别的理由,业务逻辑都得放在应用服务器中,数据库只做存储不做业务。这种小需求应该拿不出什么特别的理由去用存储过程吧。 有没有其他办法,既不用开启事务,而且还能够准确拿到 update 的结果呢?去 StackOverflow 看看吧~ 还真发现有人问了类似的问题,在7 年之前。虽然没法用一个查询搞定,但是还是有办法在不开事务的条件下实现的!借助一个变量,把更新的结果放到变量里,然后再在同一个 session 中把变量值读出来。的确是一种巧妙的做法。如下所示: update likes set gmt_modified = now(), count = @cnt := count + 1 where object_id = ?; select @cnt as count; 因为 Web 应用在和数据库交互的时候都会使用连接池,执行 SQL 前获取一个连接,然后在连接里执行一堆 SQL,然后再把连接还给连接池,所以我们基本上就不用担心 update 与 select 不在一个 session 的情况,一般来说只要代码保证 update 和 select 在同一个连接上执行就好了。 真的没有办法用一个查询搞定吗? 在这个问题被提出来的时候,在 MySQL 里面,还真是没有办法用一个查询搞定。甚至直到现在,在 Oracle 维护的官方版本的 MySQL 里头,还是没法用一个查询搞定。 但是这个世界上,MySQL 也有很多分支啊,除了彻底分裂出去的 MariaDB,还有 Percona 这个号称完全兼容 MySQL 的增强版。除了提供源码的 Percona,还有 Alibaba 维护的 AliSQL,还有数据库即服务的 阿里云 RDS。 如果你正在使用阿里云 RDS,可以尝试这样一种写法,把 update 与 select 合并为一条 SQL,进一步减少网络开销和数据库开销,提升了性能。 select count from update likes set gmt_modified = now(), count = count + 1 where object_id = ?; 需要注意的是,这个增强语法并没有在云数据库文档中明确给出,将其应用于生产环境前,最好先咨询相关专家。 做为例子,这里尝试列举几个适合使用 select from update 这种增强语法的场景。 第一个例子,分布式唯一主键生成器。 在面临较大的访问流量时,我们一般会将数据库水平拆分,成为数据库集群,数据根据分表字段散列到不同的数据库主从节点上。在单库单表的数据库中,我们的表的主键通常用的是一个自增的数字,但是水平拆分之后就不能这么用了,为了保证不同分表的数据依然满足主键唯一的约束,我们需要一个分布式的主键生成器。 暂且不论这个生成器如何实现,考虑到主键是 insert 操作必不可少的字段,主键生成器必须高性能高可用,一种策略就是批量获取主键并缓存在内存中,这样子可以成百上千倍地减少对主键生成器的请求。 select max_avaliable from update primary_keys set max_avaliable = max_avaliable + ? where primary_key = ?; 第一个参数传批量获取的数量 N,第二个参数传主键标识,这样子从读取到的最大可用主键开始,往前推 N 个都是可用的不重复的主键。 第二个例子,点赞。 第三个例子,电子商务系统中的库存扣减,和点赞正好是反向操作,点赞是加,库存是减。 基本上 select from update 适用于那些需要从更新的记录中读取一些字段的场景,特别是能够根据索引定位到少数的几条记录的时候,性能表现良好。 上一条: MySQL\SQL的语言基础 下一条: MySQL性能优化的经验
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved