 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 支持连接池与结果集缓存的MySQL数据库JDBC通用框架的轻量级封装(一)
发布日期:2016-4-22 19:4:44
支持连接池与结果集缓存的MySQL数据库JDBC通用框架的轻量级封装(一) 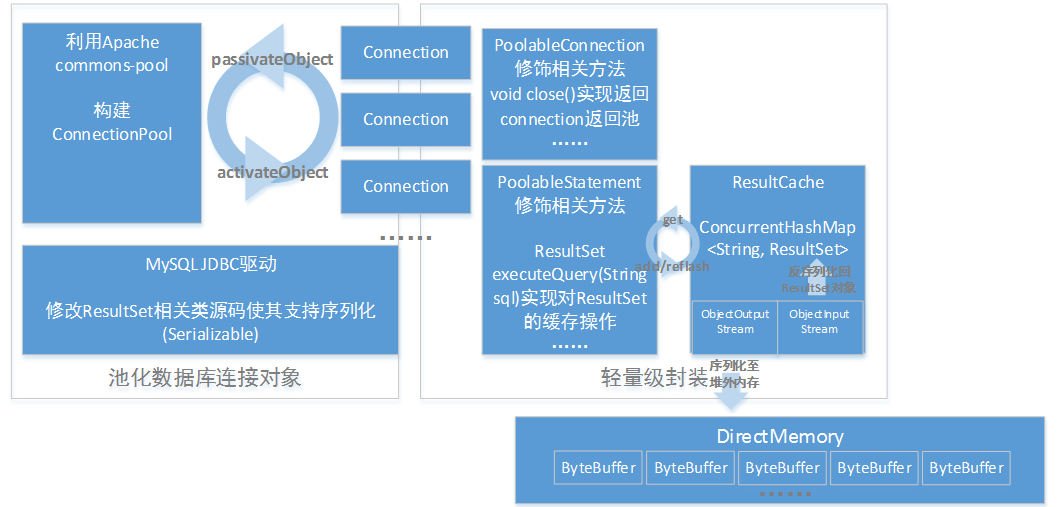 图1 结构图 一、数据库连接池构建方法 下面介绍了3种方法: 1、通过继承BasePooledObjectFactory类,利用Apache的Commons Pool实现了一个PoolableConnectionFactory类,实现了将JDBC数据库连接Connection对象包裹为一个PooledObject,并且通过create()方法实现创建Connection对象,利用重载passivateObject、destroyObject等方法来控制Connection对象在从连接池取出、到返回连接池、再到最终被销毁的整个生命周期的一些细节。代码片段已给出,如图1所示:
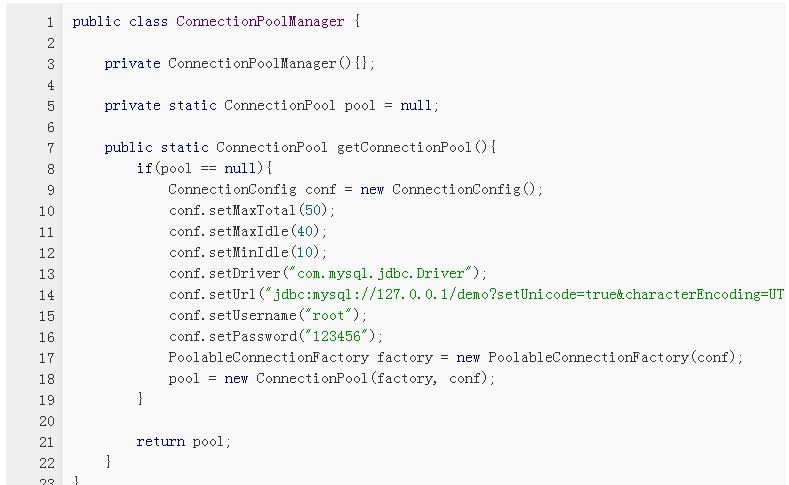
2、通过继承GenericObjectPool类实现一个ConnectionPool类,构造函数中的工厂类参数指向上述所构建的PoolableConnectionFactory对象; 3、提供一个单例模式的管理类ConnectionPoolManager,使得获取到的连接池对象唯一,代码片段已给出,如图2所示:
图2 二、通用方法的封装方式 以下给出了2中封装方式: 1、为了使最终利用该框架进行MySQL数据库开发的开发者在使用该框架时,只需通过简洁配置后,便可透明地使用数据库连接池和结果集缓存特性,需要对JDBC相关方法进行进一步封装,封装采用类装饰器的模式的方式,如建立PoolableConnection类,在构造函数中从连接池中取得一个Connection对象,代码片段已给出,如图3所示:
图3 其他主要的方法与Connection类保持一致,这样可以保证对开发者透明,代码片段已给出,如图4所示: 图4 另外,重点关注点是需要进行装饰的方法,如close()方法,当使用该方法时并不是要关闭Connection对象,而是需要将其返回到连接池中,代码片段已给出,如图5所示:
图5 2、为了实现结果集缓存,需要按上述封装思路,进一步构建如PoolableStatement和PoolablePreparedStatement类,以PoolableStatement类举例,PoolableStatement对象由PoolableConnection类中的createStatement方法产生,但实际的Statement对象是在PoolableStatement类的构造函数中由真正的Connection对象产生的,代码片段已给出,如图6所示:
图6 同样重点关注需要进行装饰的方法,如executeQuery(String sql)方法,当使用该方法时需要先通过sql参数生成key,利用key搜索缓存中是否已经缓存了对应的查询结果集,如果存在,就不需要对数据库进行物理查询,只需要从缓存中返回该结果集;如果不存,再进行物理查询,并对返回结果集创建新的缓存,代码片段已给出,如图7所示:
图7 以此类推,实现execute相关的各类方法,另外需要特别说明的一点是在进行非查询SQL时,当涉及的表格存在于缓存中时,需要锁住缓存,并刷新结果集,刷新策略可以采用立即方式或惰性方式。 三、结果集缓存设计和实现 1.结果集缓存实际是一个ConcurrentHashMap对象,ByteBuffer在JVM堆外空间申请了一片内存存储着被序列化的ResultSet对象,这是一种非常有效的内存利用方式,但需要对MySQL JDBC驱动的源代码进行修改,从而实现ResultSet对象及其内部需要被序列化的复杂对象支持序列化(Serializable),但是这种序列化是有策略的,为了节省内存空间,也将对ResultSet对象内部无需序列化的对象前添加transient关键字,一个典型的结果集缓存创建,代码片段已给出,如图8所示:
图8 2、接下来需要构建ResultSetCache类,对缓存实现控制方法,典型的包括增加一条缓存、取出一条缓存、清空缓存,当缓存达到容量和条数限制时的策略方法等,增加一条缓存代码片段已给出,如图9所示:
图9 取出一条缓存的参考代码片段已给出,如图10所示:
图10 四、框架的使用 框架使用代码片段已给出,如图11所示:
图11 从使用中可以看到达到了对开发者的框架内部实现细节的透明,开发者几乎不用了解任何数据库连接池和结果集缓存的细节。 五、该框架需要关注的技术细节 以下给出了2种技术细节: 1、ResultSet序列化问题:MySQL JDBC驱动中的ResultSet类以及相关复杂对象都是不支持序列化的,导致无法实现将ResultSet对象保持状态地序列化到一个JVM堆外内存空间中;解决方案是修改MySQL JDBC驱动源代码,对相关对象进行了序列化处理,但目前的处理细致性还不够,需要进一步分析进行精细控制; 2、非查询操作锁缓存问题:为了保持数据库的事务完整性要求,需要在处理非查询操作的SQL执行时锁住缓存,在处理完操作后,删除原来带有脏数据的缓存,并根据策略更新缓存;解决方案是目前在任何非查询操作的SQL执行时都会对整个缓存加锁,且全部查询操作都会等待解锁通知后才可以完成操作,当前的处理比较粗糙,需要进行对被操作表的提取,只对涉及到的表的查询进行锁等待。 上一条: MySQL数据库的优化 下一条: MySQL的数据库引擎
|
















 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved