 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 MySQL replication协议的深入解析
发布日期:2016-4-21 12:4:47
MySQL replication协议的深入解析 一、原因 go-mysql在最开始的时候只是简单的抽象mixer的代码,提供了一个基本的mysql driver以及proxy framework,但当我做到后面,突然觉得,既然研究了这么久mysql client/server protocol,那么就顺带把replication protocol也给弄明白好了。现在想起来,幸好当初决定实现了replication的支持,不然后续go-mysql-elasticsearch这个自动同步MySQL到Elasticsearch的工具,我还不可能在短时间完成。 其实MySQL replication protocol很简单,client向server发送一个MySQL binlog dump的命令,server就会源源不断的给client发送一个接一个的binlog event了。 二、Register 我们首先需要伪造一个slave,向master注册,这样的话master才会发送binlog event。注册很简单,就是向master发送COM_REGISTER_SLAVE命令,带上slave的相关信息。这里需要我们注意的是由于在MySQL的replication topology中,都需要使用一个唯一的server id来区别标示不同的server实例,因此这里我们伪造的slave也需要一个唯一的server id。 三、Binlog dump MySQL在最开始的时候只支持一种binlog dump方式,也就是指定binlog filename + position,向master发送COM_BINLOG_DUMP命令。在发送dump命令的时候,我们可以指定flag为BINLOG_DUMP_NON_BLOCK,这样master在没有可发送的binlog event之后,就会返回一个EOF package。不过通常对于slave来说,一直把连接挂着可能更好,这样能更及时收到新产生的binlog event。 在MySQL 5.6版本更新了之后,支持了另一种dump方式,也就是GTID dump,通过发送COM_BINLOG_DUMP_GTID命令实现,需要带上的是相应的GTID信息,在这里我觉得,如果只是单纯的实现一个能同步binlog的工具,使用最原始的binlog filename + position就够了,毕竟我们不是MySQL,解析GTID还是稍显麻烦的。这里,顺带吐槽一下MySQL internal文档,里面关于GTID encode的格式说明竟然是错误的,文档格式如图1所示: 但实际上最让人恼火的是n_sids的长度是8个字节。我当时debug了很久都没发现为啥GTID dump一直出错,直到查看了MySQL的源码,这个错误可以算是血的教训。
图1 MariaDB虽然也引入了GTID,但是并没有提供一个类似MySQL的GTID dump命令,仍是使用的COM_BINLOG_DUMP命令,不过稍微需要额外设置一些session variable,譬如要设置slave_connect_state为当前已经完成的GTID,这样master就能知道下一个event从哪里发送了。 四、Binlog Event 对于一个binlog event来说,它分为以下三个部分:
但实际我在处理event的时候,把post-header与payload当成了一个整体body。 MySQL的binlog event有很多版本,但这里笔者只关心version 4的,也就是从MySQL 5.1.x之后支持的版本。而且我也只支持这个版本的event解析,首先是不想写过多的兼容代码,另一个更主要的原因就在于现在几乎都没有人使用低版本的MySQL了。 Binlog event的header格式如图2所示:
图2 注释:
在v4版本的binlog文件中,第一个event就是FORMAT_DESCRIPTION_EVENT,格式如下面图3所示:
图3 需要我们关注的就是event type header length这个字段,它保存了不同event的post-header长度,通常我们都不需要关注这个值,但是在解析后面非常重要的ROWS_EVENT的时候,就需要它来判断TableID的长度了。这个后续在说明。 而binlog文件的结尾,通常(只要master不当机)就是ROTATE_EVENT或者STOP_EVENT。这里我们重点关注ROTATE_EVENT,格式如下面图4所示:
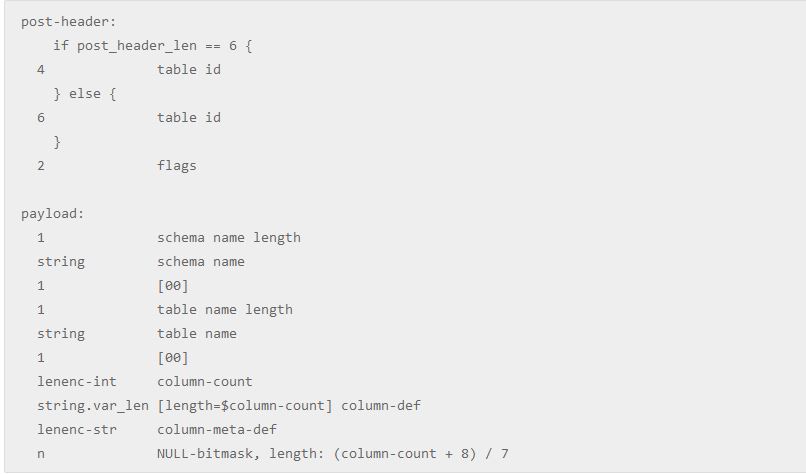
图4 它里面其实就是标明下一个event所在的binlog filename与position。这里需要注意,当slave发送binlog dump之后,master首先会发送一个ROTATE_EVENT,用来告知slave下一个event所在位置,然后才跟着FORMAT_DESCRIPTION_EVENT。 其实我们可以看到,binlog event的格式很简单,文档都有着详细的说明。通常来说,我们仅仅需要关注几种特定类型的event,因此只需要写出这几种event的解析代码就可以了,剩下的完全可以跳过。 五、Row Based Replication 如果真要说处理binlog event有啥复杂的,那铁定属于row based replication相关的ROWS_EVENT了,对于一个ROWS_EVENT来说,它记录了每一行数据的变化情况,而对于外部来说,是需要准确的知道这一行数据到底如何变化的,所以我们需要获取到该行每一列的值。而如何解析相关的数据,是非常复杂的。笔者也是看了很久MySQL,MariaDB源码,以及mysql-python-replication的实现,才最终搞定了这个个人觉得最困难的部分。 在详细说明ROWS_EVENT之前,我们先来看看TABLE_MAP_EVENT,该event记录的是某个table一些相关信息,格式如下面的图5所示:
图5 table id需要根据post_header_len来判断字节长度,而post_header_len就是存放到FORMAT_DESCRIPTION_EVENT里面的。这里需要注意,虽然我们可以用table id来代表一个特定的table,但是alter table或rotate binlog event等原因,master会改变某个table的table id,所以我们在外部不能使用这个table id来索引某个table。 TABLE_MAP_EVENT最需要关注的就是里面的column meta信息,后续我们解析ROWS_EVENT的时候会根据这个来处理不同数据类型的数据。column def则定义了每个列的类型。 ROWS_EVENT包含了以下三种event:
有以下3个版本:
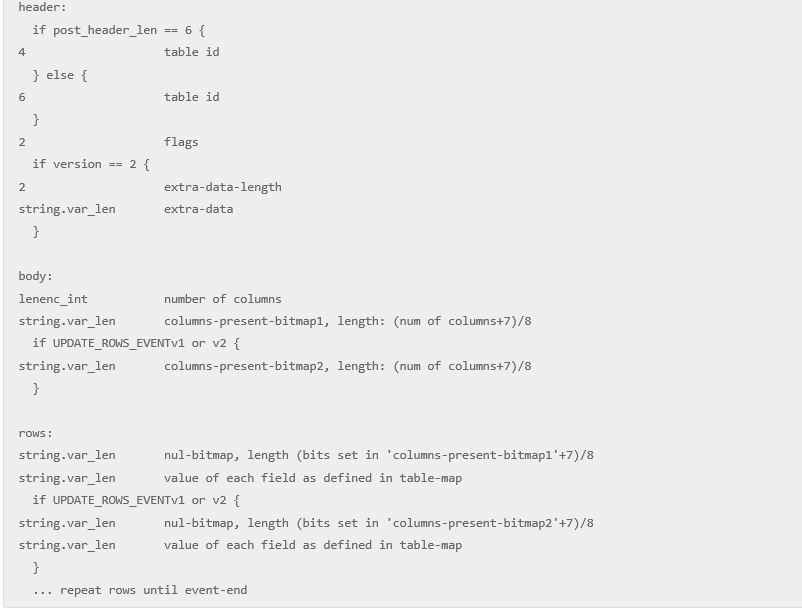
ROWS_EVENT的格式很复杂,如下面的图6所示:
图6 ROWS_EVENT的table id跟TABLE_MAP_EVENT一样,虽然table id可能变化,但ROWS_EVENT与TABLE_MAP_EVENT的table id是能保证一致的,所以我们也是通过这个来找到对应的TABLE_MAP_EVENT。 ROWS_EVENT里面对于各列状态都是采用bitmap的方式来处理的,目的是为了节省空间, 首先我们需要得到columns present bitmap的数据,这个值用来表示当前列的一些状态,如果没有设置,也就是某列对应的bit为0,表明该ROWS_EVENT里面没有该列的数据,外部直接使用null代替就成了。 然后就是null bitmap,这个用来表明一行实际的数据里面有哪些列是null的,这里最坑爹的是null bitmap的计算方式并不是(num of columns+7)/8,也就是MySQL计算bitmap最通用的方式,而是通过columns present bitmap的bits set个数来计算的,这个坑真的很大,为啥要这么设计,最主要的原因就在于MySQL 5.6之后binlog row image的格式增加了minimal和noblob,尤其是minimal,update的时候只会记录相应更改字段的数据,譬如我一行有16列,那么用2个byte就能搞定null bitmap了,但是如果这时候只有第一列更新了数据,其实我们只需要使用1个byte就能记录了,因为后面的铁定全为0,就不需要额外空间存放了,不过话说真有必要这么省空间吗? null bitmap的计算需要通过columns present bitmap的bits set计算,bits set其实也很好理解,就是一个byte按照二进制展示的时候1的个数,譬如1的bits set就是1,而3的bits set就是2,而255的bits set就是8了。 好了,得到了present bitmap以及null bitmap之后,我们就能实际解析这行对应的列数据了,对于每一列,首先判断是否present bitmap标记:
但是,因为我们得到的是一行数据的二进制流,我们怎么知道一列数据如何解析?这里,就要靠TABLE_MAP_EVENT里面的column def以及meta了。 column def定义了该列的数据类型,对于一些特定的类型,譬如MYSQL_TYPE_LONG, MYSQL_TYPE_TINY等,长度都是固定的,所以我们可以直接读取对应的长度数据得到实际的值。但是对于一些类型,则没有这么简单了。这时候就需要通过meta来辅助计算了。 譬如对于MYSQL_TYPE_BLOB类型,meta为1表明是tiny blob,第一个字节就是blob的长度,2表明的是short blob,前两个字节为blob的长度等,而对于MYSQL_TYPE_VARCHAR类型,meta则存储的是string长度。这里,笔者并没有列出MYSQL_TYPE_NEWDECIMAL,MYSQL_TYPE_TIME2等,因为它们的实现实在是过于复杂,笔者几乎对照着MySQL的源码实现的。 搞定了这些,我们终于可以完整的解析一个ROWS_EVENT了,顺带说一下,python-mysql-replication里面minimal/noblob row image的支持,也是笔者提交的pull request,貌似是笔者第一次给其他开源项目做贡献。 六、总结 实现MySQL replication protocol的解析真心是一件很有挑战的事情,虽然有点辛苦,但是让我更加深入的学习了MySQL的源码,为后续改进LedisDB的replication以及更深入的了解MySQL的replication打下了坚实的基础。 话说,现在成果已经显现,不然go-mysql-elasticsearch不可能如此快速实现,后续准备基于此做一个更新cache的服务,这样我们的代码里面就不会到处出现更新cache的代码了。 上一条: 你好!PostgreSQL 下一条: MySql语句:创建、授权、查询、修改
|







 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved