 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 剖析 redis 数据淘汰策略
发布日期:2016-4-16 11:4:57
剖析 redis 数据淘汰策略 一、概述 与mysql不一样的是,redis 允许用户设置最大使用内存大小 server.maxmemory,在内存限定的情况下,这是很有用的。比如在一台 8G 机子上部署了 4 个 redis 服务点,每一个服务点分配 1.5G 的内存大小,这会减少内存紧张的情况,由此获取更为稳健的服务。 redis 内存数据集大小上升至一定大小的时候,就会施行数据淘汰策略。redis 提供以下 6种数据淘汰策略:
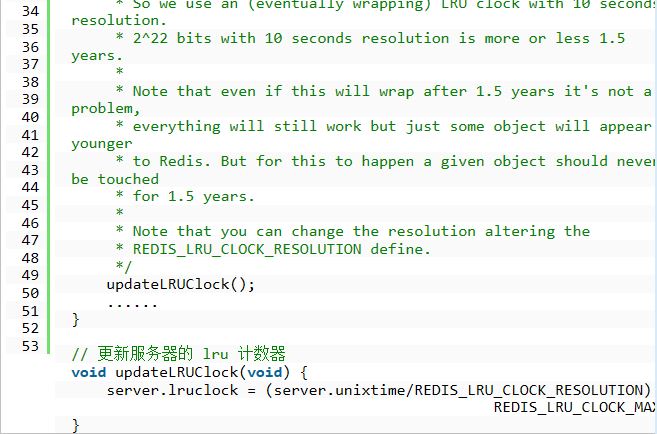
redis 确定驱逐某个键值对后,就会删除这个数据并,并且将这个数据变更消息发布到本地(AOF 持久化)与从机(主从连接)。 二、LRU 数据淘汰机制 在服务器配置中保存了 lru 计数器 server.lrulock,就会定时(redis 定时程序 serverCorn())更新,server.lrulock 的值是根据 server.unixtime 计算出来的。 此外,从 struct redisObject 中可以发现,每一个 redis 对象都会设置相应的 lru。我们能想象的是,每一次访问数据的时候,就会更新 redisObject.lru。 LRU 数据淘汰机制是这样的,可以参考以下程序:在数据集中随机挑选几个键值对,取出其中 lru 最大的键值对淘汰。因此,你会发现,redis 并不是保证取得所有数据集中最近最少使用(LRU)的键值对,而只是随机挑选的几个键值对中的。
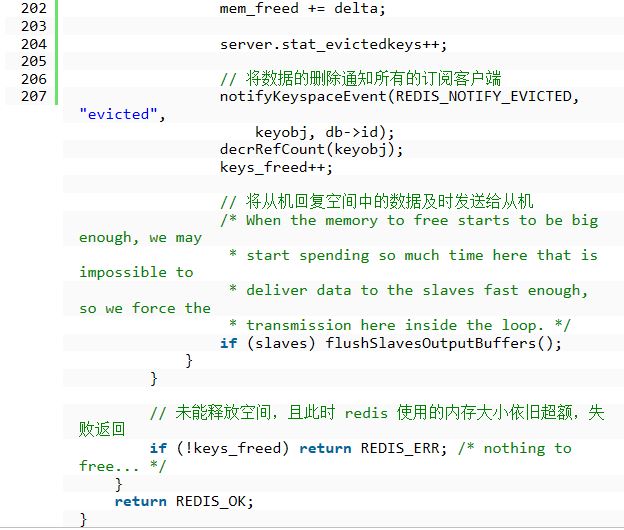
代码1 三、TTL 数据淘汰机制 redis 数据集数据结构中保存了键值对过期时间的表,即 redisDb.expires。与 LRU 数据淘汰机制类似,TTL 数据淘汰机制是这个样子的:从过期时间的表中随机挑选几个键值对,取出其中 ttl 最大的键值对将其淘汰。你也会发现,redis 并不是保证取得所有过期时间的表中最快过期的键值对,而只是随机挑选的几个键值对中的。 四、总结 redis 每服务客户端执行一个命令的时候,就会检测使用的内存是否超额。若超额,就进行数据淘汰。如下面的代码所示:
后面我们会更新一些关于mysql的文章,敬请关注。
|










 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved