 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Spark和Mysql(JdbcRDD)整合开发
发布日期:2016-4-13 12:4:52
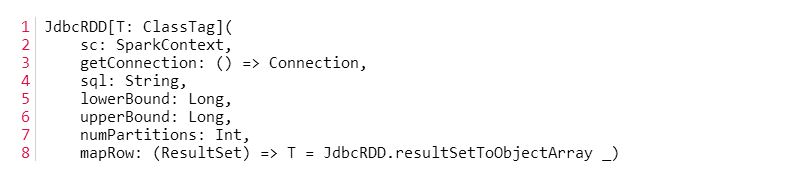
Spark和Mysql(JdbcRDD)整合开发 Spark的功能非常强大,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《Hive的整合》。我们今天的主题是聊聊Spark与Mysql的组合开发。 图1 在Spark中提供了一个JdbcRDD类,该RDD就是读取JDBC中的数据并转换成RDD,之后我们就可以对该RDD进行各种的操作。我们先看看该类的构造函数,如图2所示:
这个类带了很多参数,关于这个函数的各个参数的含义,我觉得直接看英文就可以很好的理解,如下面所示:
我来翻译一下。
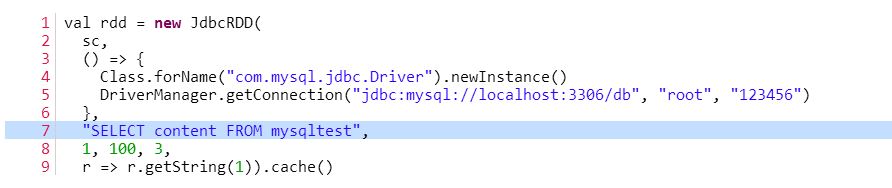
下面我们说明如何使用该类,请参考下图的代码。
代码比较简短,主要是读mysqltest 表中的数据,并统计ID>=1 && ID < = 100 && content.contains("success")的记录条数。我们从代码中可以看出JdbcRDD的sql参数要带有两个?的占位符,而这两个占位符是给参数lowerBound与参数upperBound定义where语句的上下边界的。从JdbcRDD类的构造函数我们可以知道,参数lowerBound与参数upperBound都只能是Long类型的,并不支持其他类型的比较,这个使得JdbcRDD使用场景比较有限。而且在使用过程中sql参数必须有类似 ID >= ? AND ID < = ?这样的where语句,若你写成下面所示的形式:
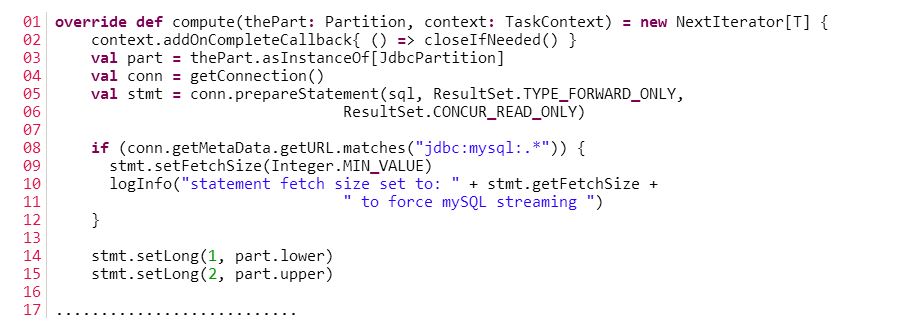
那在运行的时候会出现以下的错误: 看下面JdbcRDD类的compute函数的实现就可以知道了:
不过令人高兴的是,我们可以自定义一个JdbcRDD,修改上面的计算思路,这样就可以得到符合我们自己要求的JdbcRDD。 注: 在写本文的时候,本来我想提供一个JAVA例子,但是JdbcRDD类的最后一个参数很不好传,网上有个哥们是这么说的: I don't think there is a completely Java-friendly version of this class. However you should be able to get away with passing something generic like "ClassTag.MODULE. 下面的英文是我发邮件到Spark开发组询问如何在Java中使用JdbcRDD,Spark开发组的开发人员给我的回复信息如下: 所以我也只能放弃。若你知道怎么用Java实现,欢迎留言。 下一条: Flume-ng和Mysql整合开发
|









 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved