 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Celery 与Redis 的入门
发布日期:2016-4-24 17:4:17
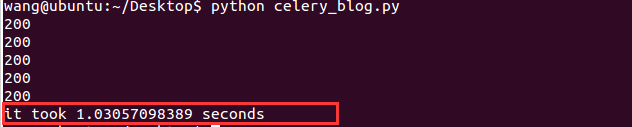
Celery 与Redis 的入门 一、Celery 1.简介 Celery 为一个广泛应用于网络应用程序的任务处理系统。 它可以在下面的情况下使用: 在请求响应周期中做网络调用。服务器应当立即响应任何网络请求。如果在请求响应周期内需要进行网络调用,则应在周期外完成调用。比如当用户在网站上注册时,需要发送激活邮件。发送邮件是一种网络调用,耗时2到3秒。用户应该无需等待这2到3秒。所以发送激活邮件应当在请求响应周期外完成,celery 就能实现这一点。 将一个由几个独立部分组成的大任务分成多个小任务。如果你想知道脸书用户的时间流。脸书提供不同的端点来获取不同的数据。譬如,一个端点用以获取用户时间流中的图片,一个端点获取用户时间流中的博文,一个端点得到用户的点赞信息等。如果你的函数需要和脸书的5个端点依此通信,每个网络调用平均耗时2秒,你将需要10秒完成一次函数执行。但你可以把这项工作分为5个独立的任务(你很快就会发现这很容易做到),并让 celery 来处理这些任务。Celery 可以并行地同这5个端点通信,在2秒之内就能得到所有端点的响应。 2.简单的 celery 例子 假如我们有一个函数,并传给它一个网址列表。该函数需要获取这些网址的响应。 2.1没有使用 celery 参考代码已给出,如下所示: 创建文件celery_blog.py: import requests import time def func(urls): start = time.time() for url in urls: resp = requests.get(url) print resp.status_code print "It took", time.time() - start, "seconds" if __name__ == "__main__": func(["http://oneapm.com", "http://jd.com", "https://taobao.com", "http://baidu.com", "http://news.oneapm.com"]) 运行,如下所示: python celery_blog.py 输出结果如图1所示:
2.2 使用 celery 调用 celery 的程序中最重要的组成部分是 celery worker。
celery worker 与你的应用程序/脚本是不同的进程,彼此是独立运行。因此你的应用程序/脚本和 celery 需要一些方法来相互沟通。 应用程序代码需要把任务放在 celery worker 可以取出并执行的位置。例如,应用程序代码将任务放在消息队列中,celery worker 从消息队列领取任务并执行任务。我们将使用 Redis 作为消息队列。 注意:
修改文件 celery_blog.py,参考代码如下: from celery import Celery app = Celery('celery_blog',bloker='redis://localhost:6379/1') @app.task def fetch_url(url): resp = requests.get(url) print resp.status_code def func(urls): for url in urls: fetch_url.delay(url) if __name__ == "__main__": func(["http://oneapm.com", "http://jd.com", "https://taobao.com", "http://baidu.com", "http://news.oneapm.com"]) 代码解释:我们需要一个 celery 实例来启动程序,因此创建了一个名为 app 的 celery 实例。 在以下3个终端中启动:
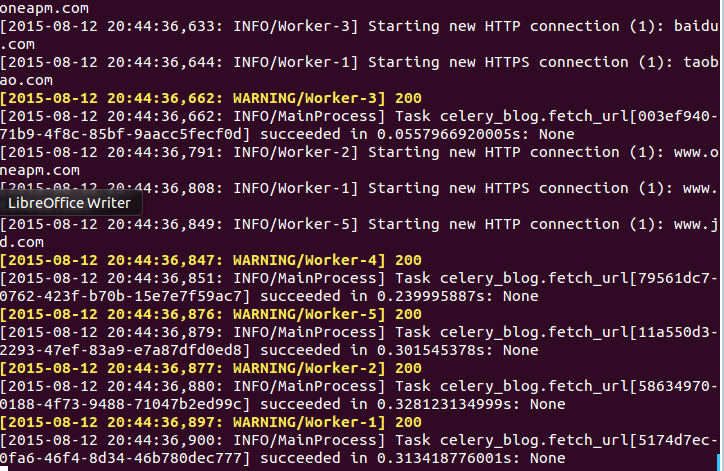
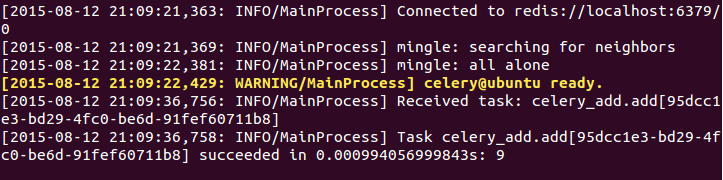
可以看到第二个终端输出如图2所示: 2.3 将 celery 代码与配置保存在不同文件中 从上面的例子中,我们只写了一个 celery 任务。但是您的项目可能涉及多个模块,您可能希望在不同的模块中有不同的任务。因此让我们将 celery 配置移到单独的文件中。 创建 celery_config.py from celery import Celery app = Celery('celery_config', broker='redis://localhost:6379/0', include=['celery_blog']) 修改 celery_blog.py 代码如下所示: import requests from celery_config import app @app.task def fetch_url(url): resp = requests.get(url) print resp.status_code def func(urls): for url in urls: fetch_url.delay(url) if __name__ == "__main__": func(["http://oneapm.com", "http://jd.com", "https://taobao.com", "http://baidu.com", "http://news.oneapm.com"]) 停掉之前的 celery worker ,运行以下代码: celery worker -A celery_config -l info -c 5 打开 ipython ,运行如下所示的命令: In [1]: from celery_blog import func In [2]: func(["http://oneapm.com", "http://jd.com", "https://taobao.com", "http://baidu.com", "http://news.oneapm.com"]) 输出如图3所示: 2.4 在不同文件中添加新的任务 您可以添加新的模块,并在该模块中定义一个任务。用以下内容创建一个模块 celery_add.py,参考代码如下所示: from celery_config import app @app.task def add(a, b): return a + b 改变 celery_config.py 包含新的模块 celery_add.py,如下所示: from celery import Celery app = Celery('celery_config', broker='redis://localhost:6379/0', include=['celery_blog', 'celery_add']) 在 ipython 输入以下代码: In [1]: from celery_add import add In [2]: add.delay(4, 5) 输出如图4所示: 三、在不同的机器上分开使用 Redis 与 celery 目前为止,我们的脚本celery worker 与Redis 都运行在同一机器中。其实并无这种必要,这三者可以运行在不同机器上。 celery 任务涉及到网络请求,所以,在网络优化的机器上使用 celery worker 能提高任务运行速度。Redis 是一种内存数据库,在内存优化的机器上运行效率更高。 在上面的例子,我将在本地系统运行脚本和 celery worker,在分开的服务器上运行 Redis。 修改 celery_config.py 为以下代码: app = Celery('celery_config', broker='redis://192.168.118.148:6379/0', include=['celery_blog']) 现在我运行任何任务,脚本都将把他放在 Redis 运行的服务器(192.168.118.148)上面。 celery worker 也同 192.168.118.148 沟通,在这个 Redis 服务器上得到任务并执行它。 请注意:您必须使用正在运行 redis-server 的服务器地址。我的服务器已停止Redis,所以你将无法连接到 Redis。 以后会更新关于mssql的文,关注mssql的朋友请期待。 参考文章:Getting started with Celery and Redis 上一条: 数据库连接池的理解与使用
|





 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved