 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Uber数据大迁徙
发布日期:2016-4-23 20:4:3
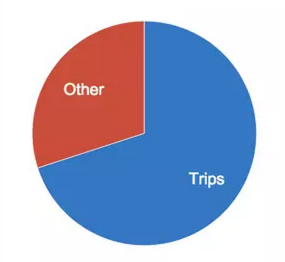
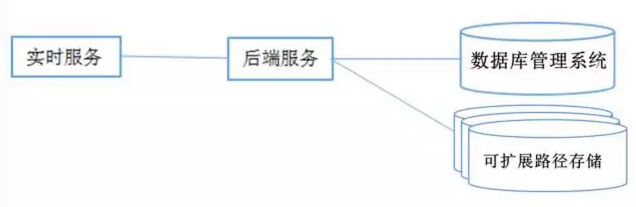
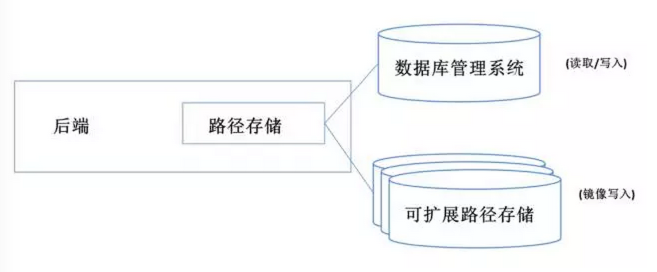
Uber数据大迁徙 如果你必须要在几个星期内迁移数以亿计的数据和100多个服务项目,而且同时还要保持UBER被几百万的乘客正常使用,这还是一个非常艰辛的任务,而以下这个故事就是关于数十名工程师是如何帮助UBER在2014年迁移到Mezzanine的故事。 2014年年初,我们面临了一个非常严峻的现实问题,是关于我们的路径的增长(一个月约增长了20%),所以在年底之前用于存储路径的存储容量将会不够用。我们因此推出Mezzanine项目这一盛举来解决这个特别的问题。数据大迁移的日期定为万圣节(10月31日),而这恰是交通量会非常高的一天。 背景 就像大多数基于网络服务的公司那样,UBER后端系统一开始是采用“单一化”的软件架构,其中包括一群应用服务器与一个单独的数据库。这个系统主要是写在Python编程语言之下,以及使用的SQLAlchemy(开源软件)作为ORM -layer(对象关系映射层面)到数据库。原来的架构在少数城市运行较少的车次路径是够用的。到2014年年初,这个架构已演变成接近100个服务项目的真正以服务为导向的体系结构了。这个系统的高层次的图像如下所示: 实时服务负责执行规划路径,后端服务负责计算乘客的付账、给司机的费用,以及侦查欺骗、做分析、和管理城市等职能。上面图中的大问题是:我们仍然依赖于单一的PostgreSQL (数据库管理系统)来存储大部分的数据。下面的饼图显示了数据是如何在数据库中分配的: Trips(路径)数据占用比例最大,是(现在仍然是)增长最快的数据,也形成了最多的IOPS(每秒钟输入输出)。我们使用路径数据是为了为了提高服务,比如说像uberPOOL,给乘客与司机提供支持,防止欺诈行为,以及开发与测试新的功能,比如说在旧金山的搭乘建议。因此,我们开展了Mezzanine项目来重新构建系统,它看起来如下图所示: 新的路径存储 第一个设计决定是对路径存储的数据库选择。我们简短的需求列表如下所示: 操作上稳健(无数据丢失,支持备份,复制到二级数据中心,便于排除故障,可预测的,业务专长)。 高写入可用性。我们总是希望能够坚持稳定路径存储。短期可读性也可以,因为后端会批量运作。 水平扩展存储容量和IOPS(每秒钟输入输出)。 任何操作都不会死机(扩大的存储,备份,添加索引,添加数据,等等)。 二级索引支持。路径根据用户,城市的不同而产生不同的结果。 列表的最后一个项目是在解决一个非常直接的痛点。PostgreSQL(数据库管理系统)中的路径表增加过快,以至于任何操作比如增加一个新的列或添加新的索引会引起的死机。这使得开发新的功能变得越来越烦琐。 我们决定,用一个导向柱,无模式的方法,其中数据(JSON blobs)被路径-UUID(通用唯一识别码)、列名和任选的时间戳一起形成一个格状索引,它可以像一个整体的数据模型那样很好地工作。这个模型通过划分多个行来横向扩展分片,并且通过无模式来支持我们快速发展的文化。新的列可以添加,和新的字段也可以被添加而不需要重建模块。 我们评估了各种NoSQL(不同于传统的关系数据库的数据库管理系统的统称)的具有上述特点风格的数据库。但是由于我们的操作经验或者是产品本身的不成熟,所以我们并不认为这些数据库适合用来存储我们的路径数据。 受到博客文章的启发,比如这个启发来自FriendFeed的,我们决定建立我们自己的简单,可以分片数据存储的MySQL(开放源代码的关系数据管理系统)。我们建立的系统的主要特点是: 分片:每一行分为一组固定的分片,用来设置时间。通常情况下,我们使用4096。每个分片对应于一个MySQL(开放源代码的关系数据管理系统)表,以及这些分片由多个的MySQL服务器来分配。分片可以在MySQL服务器之间移动来控制负载平衡,而且容量可以在线增加。我们通常通过把MySQL一分为二来扩展服务器。 缓冲写入:如果其中细胞需要被写入的分片到不可用(或慢),我们会将数据写入一个待定表中在任何其它可用的MySQL服务器里。一旦分片可用了之 分片二级指标:指标可以在列多个字段来制作,而且由一个特定的键来(例如,用户UUID)分片。它们就如MySQL表一样在运作并在后台回填。如果我们需要改变的指数(例如,添加字段),我们可以创建一个新的版本,回填它,然后通过改变指数别名切换到新的版本,这些都不会使应用程序死机。 后就可以重播了。由于幂等和交换数据模型,这始终是安全的,不会需要跨主机的协调。 追加(无更新)数据模型:它仅支持一个只追加数据模型中,一旦它被写入后,就不能进行修改。这对于存储交易数据,并希望防止数据损坏的系统是非常有用的。由于是只追加模型,修改会自然幂等和交换。这意味着我们可以重播订单的最新状态,并得到同样的结果。(后来我们知道了只追模型也是由拉姆达架构支持的)。 整个系统,我们简单地把它称之为无模式来表示对它的敬意,整个系统都是用Python来编写的。最初的版本大概花了5个月左右的时间从创意到生产部署。 从SQLAlchemy(开源软件)到Schemaless(无模式) 编写一个新的可扩展的数据存储一个从无到有的创举。 使用PostgreSQL数据库来重建一个实时系统的关键部分因而撬动了一个面向列的数据库是一个完全不同的游戏。显然,路径数据是UBER后端系统代码的一个组成部分,所以这个任务会触及大多数的工程团队。 在这部分的项目中的主要里程碑是: 把所有的用户身份都变为了UUID(用户唯一识别码)。 在Schemaless(无模式)上做路径的列型布局(例如,新路径的数据模型)。 回填从PostgreSQL到无模式的数据。 镜像写入到PostgreSQL和Schemaless(无模式)。 在Schemaless(无模式)中重写所有的查询。 验证。 在真正可以开始大迁移之前,首要任务就是从用户身份到用户唯一识别码的迁移,因为原代码依赖于自动递增的PostgreSQL 数据库标识符。几百条SQL查询需要被重写。这些SQL查询都是在SQLAlchemy的Python代码的形式,并且包括通过模型关系显式或间接的查询。这些都需要被重写,从而方便在新的无模式中连接应用程序的接口,这是一个受限制的应用程序接口,它不支持联接针对PostgreSQL中其他表格。 我们最初的目标是直接删除的路径表中的SQLAlchemy的路径模型和查询的用户。从本质上讲,我们希望得到下图所示结构: 路径存储的API(应用程序接口),这是一个基于无模式的实现兼容的API。路径存储就像一个开关,一个查询要么可以通过PostgreSQL或通过Schemaless(无模式)。因此,我们在PostgreSQL的数据模型之上模拟了无模式API作为代码的重新构建。 当所有写入被镜像到无模式,我们可以在无模式里重播所有查询并且验证在后台的结果。因此,我们几乎可以立即开始评估,在Schemaless(无模式)数据和PostgreSQL中的数据是一致的。因为验证将负载到数据库(这是已经重负载),我们使用了概率方法来控制我们把对PostgreSQL数据库的额外负载。这里有一个意外收获,数据建模,回填,重构和无模式发展可以并行,以及这些可以有所不断进步和加大。 执行 Mezzanine迁移过程中我们旧金山总部的会议室。 Mezzanine项目的最终危机持续了6周时间。我们大多数人都聚在一个“作战室”,把剩余SQLAlchemy的代码转换到新的路径存储库里面去,完成回填,设计与重建索引的工作,就像是一个“强迫症患者”那样不断地去做改进与验证的工作。 2014年万圣节前一天,我们已经准备把路径存储从PostgreSQL搬到Schemaless(无模式)数据库去。所有工程组队员们当天早上6点就都出现在了旧金山的办公室里。如果出现了问题,所有队员就可以马上进行排查,而且我们有一整个工作时间来进行修复。但是那天竟然没有出任何问题!对于UBER平台来说,它一切正常。 教训总结 要使用UUID(通用唯一识别码):请始终使用的UUID。如果你一开始的时候都用ID,但当你开始大量增长时,就会要做更多繁复的工作。 保持数据层简单:它必须是便于调试和故障的排除。性能指标是特别有价值的。把MySQL(开放源代码的关系数据管理系统)作为低级别的存储层,使我们能够非常快速地构建一个强大的系统。 NoSQL(不同于传统的关系数据库的数据库管理系统的统称)是强大的:用分片指标的结合列式的方发把数据层的性能变化直接呈现给程序员。通过正确的抽象描述,它使同时在应用服务器层和数据层写解决方案变得简单。 有一个学习曲线:从编写代码对有限的查询功能的关键价值存储,转变成直接写在一个ORM或SQL上,这个变化是需要时间来掌握和过渡的。幂等替代交易。 试错:不要期望第一次就能获得数据模型。做好多试几次和部分回填的准备。 快速完成:做最后的迁移要迅速而快捷。随着功能的开发,它总是一个要不断达到的目标,因此,你需要比代码库的其余部分移动得更快。 UBER积极心态!有一个积极和敢做的态度会使全队全力以赴创造辉煌。 自从我们迁移了大数据以来,我们就已经增加了一倍的路径存储了,而且实现了零死机,并且实施了许多性能与运营方面的改进。在此之上,无模式数据库现在也被其它很多服务项目使用。 上一条: 三大缓存框架ehcache、redis与memcache的介绍 下一条: MongoDB的8个方面
|






 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved