 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 redis的双主设计
发布日期:2016-4-23 13:4:30
redis的双主设计 一、redis背景 redis是目前的背景:
二、redis主从复制介绍 redis支持树形的主从异步复制,并具有非阻塞、部分同步等特性,与mssql类似,下面我们将简单介绍下其实现原理以及目前redis主从复制模式在故障发生时的数据丢失情况。 三、实现原理 1.数据同步
2.数据传播 master实例会维护其slave实例列表,master实例在有更改操作发生时会通过连接建立时创建的socket向所有slave实例发送操作命令进行数据传播,同时也为了防止故障恢复slave重新连接master时每次都进行全量同步,master实例会内部维护一个缓冲区(积压空间)来缓存部分slave命令,以下所示的是master数据传播的具体过程:
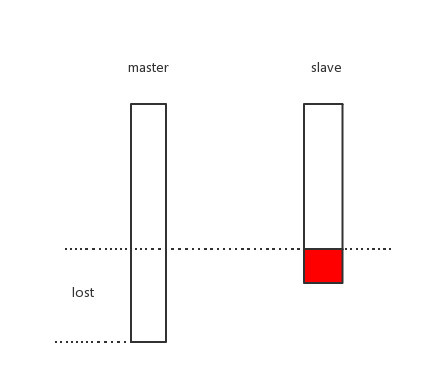
触发写入slave实例事件,进行异步传播;如果此刻正在进行数据同步操作则将命令写入缓冲区,待同步操作完成后再触发向slave实例写入事件。 3.数据丢失 其实redis主从模式并不能保证数据的100%完整,在网络故障、主库宕机这些情况下,提升slave为master时可能会丢失部分数据,如下面的图2所示,如果在某个时刻master的数据还未完全传播给slave时,master宕机等情况发生并将slave提升为master,这时原来master未传播的一部分数据将丢失。
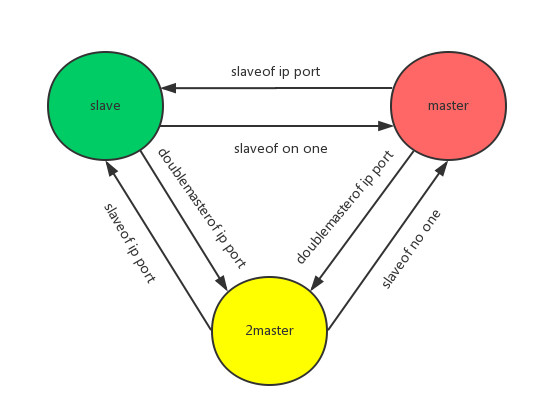
图2 四、双主复制设计 1.前提假设 目前我们由于时间精力的关系在进行双主设计时结合如下所示的实际项目需求进行了一些设计折衷,后续我们会继续完善相关设计。 上层保证某个时间点只有一个master在写 故障时允许丢失少量数据 2.总体设计 双主模块为了避免额外维护成本会完全在redis内部实现,双主两个实例各自创建一个socket进行彼此通信;加入双主复制后不会影响原有的主从复制模式,但如图3下图所示,主从复制实例可以通过我们新增的doublemasterof命令转化为双主复制,双主复制实例也可以通过原有的slaveof命令转换为主从复制实例。
图3 3.同步策略 redis双主实例网络故障恢复或重启等情况下会进行重新连接以同步彼此数据,主从模式下同步策略很简单,只需要从库同步主库数据即可,而双主模式下我们必须根据一定的策略来选出一个实例作为数据同步的对象,我们考虑到两种具体同步策略:
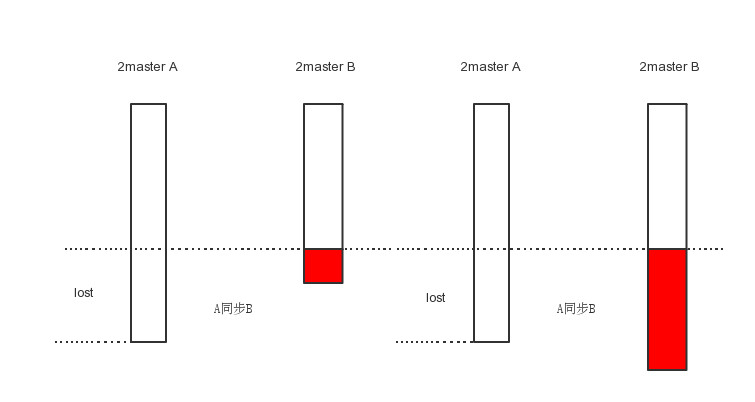
4.数据量同步策略 基于数据量的同步策略可以理解为数据量少的实例去同步数据量多的实例,这种同步策略在故障发生时数据已经全部传播到另外一个实例的情况下,故障恢复后可以保证数据完整性,但如下图所示,假如原来操作在双主A上执行,某一时刻双主A上的操作还未同步到双主B上发生了网络故障,上层会切到B上继续写入,当写入了图中红色所示大小的数据后网络故障恢复,这时进行数据同步时就有可能丢失A或B上的部分数据。
5.时间戳同步策略 我们会对于基于时间戳的同步策略,在redis内部维护双主实例的最近更新时间戳,故障恢复进行数据同步时时间戳较旧的实例会同步时间戳较新的实例;与基于数据量同步策略一样当故障发生时如果数据已经全部传播到另外实例则故障恢复后可以保证数据完整性,否则,如图4所示故障恢复后将丢失双主A实例的部分数据。
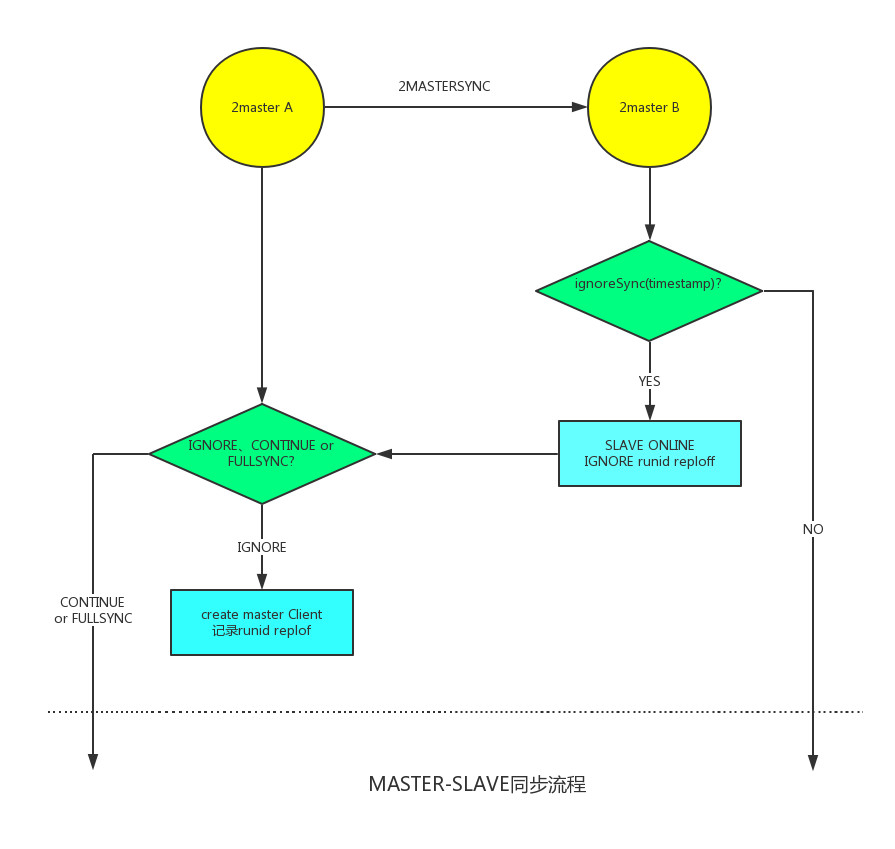
图4 六、我们的选择 我们会根据业务需求保证最新写入的数据不会丢失,因此具体实现上我们选择了基于时间戳的同步策略。 1.同步实现 我们在redis原有的全同步,部分同步的基础上增加了ignore resync策略以实现双主同步,具体实现如下面的图5所示,有以下所示的几个步骤:
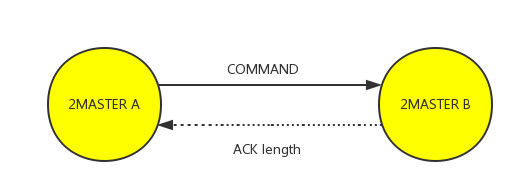
2.数据传播 redis会对一个双主实例的更改操作内部会通过双主实例建立连接时创建的socket异步传播给另一个双主实例,这里要解决的问题是要避免数据再次传播回来,具体实现上我们通过双主实例的runid进行判断,每个双主实例内部会维护其另外一个实例的runid信息,当有更改命令要执行时,我们会通过runid来判断该命令是否是其双主实例传播过来的,如果是将不再回传。 3.复制偏移量维护 redis主从实现机制上,当通信模块接收到主库的更改命令时会直接在从库上增加其复制偏移量来记录数据同步的位置,而对于双主实例我们知道为避免数据循环传播,双主实例A传播给双主实例B的命令不会回传过来,那么该如何维护其复制偏移量呢?设计上我们考虑了两种策略:
与策略二对比,策略一进一步保证了数据的完整性,但同时带来了一定的网络开销,两种策略都不能完全保证复制偏移量再网路故障下的正确性(策略一在ACK丢失的情况下无法保证复制偏移量正确),结合目前的需求为了不影响性能我们选择了策略二。 七、总结 结合目前项目的需求我们在redis内部实现了双主功能,但是也有一些需要改进的地方,欢迎大家提出意见,后面我们也会更新mssql的专题,敬请关注!
|





 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved