 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 redis在运维数据分析中的去重统计方式
发布日期:2016-4-21 10:4:41
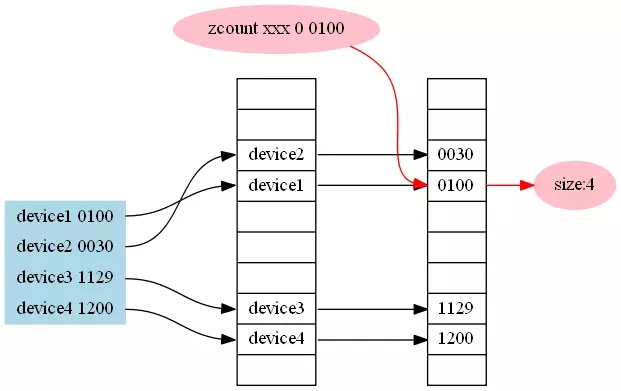
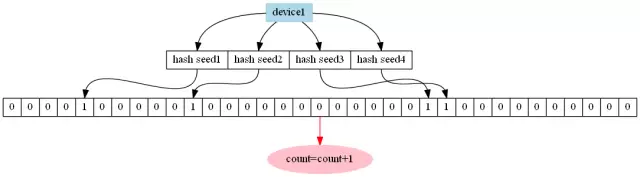
redis在运维数据分析中的去重统计方式 概述 广通软件旗下优云大数据平台开发工程师胡翀,通过自己多年在统计平台的数据的分析和存储领域的摸爬滚打,从实践经验角度和大家分享下redis在运维数据分析中的去重统计方式。为了避免混淆,本文中对于redis的数据结构做如下约定: SET:saddkey member STRING:setbit key offset value ZSET:zaddkeyscoremember HYPERLOGLOG:pfadd key element 名词约定: 维度:比如版本、操作系统类型、操作系统版本、运营商、设备型号、网络类型等 复合维度:由两个或多个维度交错产生的维度,比如某个版本下的某个设备型号。 去重统计在数据化运维的指标计算环节,并不是一个陌生的字眼,甚至可以说,在大部分的数据指标的中间计算过程中,最终会分为以下几种数据集: 最大,最小,稳定性,叠加,去重统计。 这5种指标前面4种在实时处理框架或者大部分NoSQL中使用相对较小的开销即可完成计算,基础指标计算的大部分计算瓶颈还是落在io上面,而导致io瓶颈的问题源自于数据维度的划分与聚合,特别是对于去重统计类型的数据,如果有一种需要实时显示的去重指标,维度的切分对于io上的开销简直是一种灾难。 例如 定我们需要获取手机终端中某个应用版本中的某个设备型号或者某个系统的活跃设备数。那么,目前市场中的设备型号有几百种,各种系统版本x系统类型也有许多,对指标的去重统计来说每多一个维度,需要的内存开销就要多上一倍,2个维度交叉产生的复合维度可能多达上百个,3个维度的交叉产生的复合维度可能数以千计。 因此,对于实时显示的去重统计类型指标,最好的处理方式就是在设计时尽量规避这种指标。如果实在是无法规避,那么我们需要做的牺牲一部分插入时的性能或者空间上的性能换来该部分指标在读取时不是o(n)的。 下面简单介绍几种在开发中基于redis研究出来的几种数据去重方式。 1.基于set的去重统计 这种结构的数据应该是最好理解的统计方式,也是常规的统计方式之一,直接把要去重的部分作为member插入一个set中,需要统计的时候直接使用scard统计该数据集的基数,对于时间等维度信息,可以放在key中,然后拿取的时候通过拼接维度字段的形式拿取。如下图所示: 优点:使用简单,统计精确。 缺点:无法达成实时统计的功能,要一分钟统计一次的话需要使用expire命令设置一个很短的回收时间,单一维度时占用空间过大,信息聚合成本过大,有几个维度就需要几倍的内存空间,3个以上复合维度时基本不需要考虑此方案。 适用场景:需要统计的去重内容的基数非常小的情况下可以考虑,在优云mobile中,对于用户基数较小的影响设备数的计算采用了此种方式。 2.基于zset的去重统计 传统的基于跳表/B树的统计方式,key为维度信息,score为时间,member为设备id等原子信息,通过zcount可以拿取所有的成员数量。如下图所示: 优点:插入和统计都是o(log(N))的,可以精确统计从现在开始到某个时间点的用户,可以保留原子数据。 缺点:只可以自定义时间域上的左区间,对于右区间只能定义为现在时间,否则会出现统计值比实际值偏小的情况(因为同一个设备如果出现两次,则会移除旧的那条),单一维度时占用空间过大,有几个维度就需要几倍的内存空间,3个以上复合维度时基本不需要考虑此方案。 适用场景:对于查看从现在开始1分钟 5分钟 10分钟 等各种时间跨度的用户基数时可以考虑,在优云mobile中,采用了这种方案来统计活跃设备数,早期开发时我们将各种时间维度和各种复合维度全部放在了redis中,结果发现内存开销过大,现在的版本我们只存放了最近2分钟的一些简单维度的数据。 3.基于hyperloglog的去重统计 hyperloglog是一种基于概率的统计方式,在redis的2.8.9版本后出现的新数据结构 详细的内容可以查看这几篇文章: http://blog.codinglabs.org/tag.html#基数估计 优点:每个hyperloglog只需要12K的空间,并且误算率只有0.81%,不同的纪录之间可以进行聚合,也就是可以通过聚合统计出任意时间范围的去重结果,统计单个hyperloglog时时间复杂度为o(1)。 缺点:对于统计结果要求较为精确的场合并不是非常适用 适用场景:在对误算率要求不高的情况下,同bitset。 4.基于bitset的去重统计 将终端用户id映射为一个bitset上的一个bit,利用现代处理器的特性进行快速计算。如下图所示: 优点:统计结果精确,对于不同维度可以使用and或者or进行聚合,数据具有原子性,通过较少的操作就可以做到跨维度的计算。 缺点:不适用于分钟级别的统计,并且用户id的映射较为麻烦。如果使用hash的方式进行映射,将会不可避免的产生hash碰撞,如果使用用户id进行映射,那么必然需要维护一份用户id映射表,这份映射表放在内存中会占用大量空间,放在磁盘中则会导致整个系统的处理速率降低。 备注: java中的bitset在一个byte字节上是由低位到高位进行存储,redis中则是由高位到低位进行存储。 适用场景:适用于需要储存原子数据并进行较大时间跨度或者自由拼接时间跨度聚合的场景。 5.基于布隆过滤器的去重统计 布隆过滤器是一种改良的bit映射方案,通过使用多种不同的hash种子,可以做到在较低误判率以及较高的空间利用率的情况下进行统计,redis中并没有布隆过滤器这个数据结构,不过可以通过lua脚本的方式实现一个布隆过滤器,详细源码可见: https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter1 优点:对于200万用户不超过万分之一误算率的统计,只需要8M左右redis内存即可完成统计,万分之一的误算率是在插入的不同设备数达200万次时才拥有的误算率,在这之前的误算率是从0开始线性增长的,在大多数情况下这个误算率应该是可以容忍的。 缺点:布隆过滤器的统计结果无法聚合 适用场景:对于一些需要实时显示的内容并且维度较少的内容,可以采用此数据结构,在优云mobile中,总览页面的活跃设备数采用了此方案来实时显示今日活跃设备数。 作者简介 胡翀 广通软件旗下—优云软件打杂初级java开发工程师一枚,现任优云大数据平台开发工程师,负责统计平台的数据的分析和存储。广通软件十多年来耕耘于运维管理软件研发和服务咨询,面向数据中心、互联网、物联网三个领域提供整合化的运维工具和服务。微信公众号: broada_ops 上一条: Redis配置文件参数说明 下一条: Redis源码速览
|





 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved