 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 MSSQL死锁产生的原因与解决方法
发布日期:2016-4-17 11:4:52
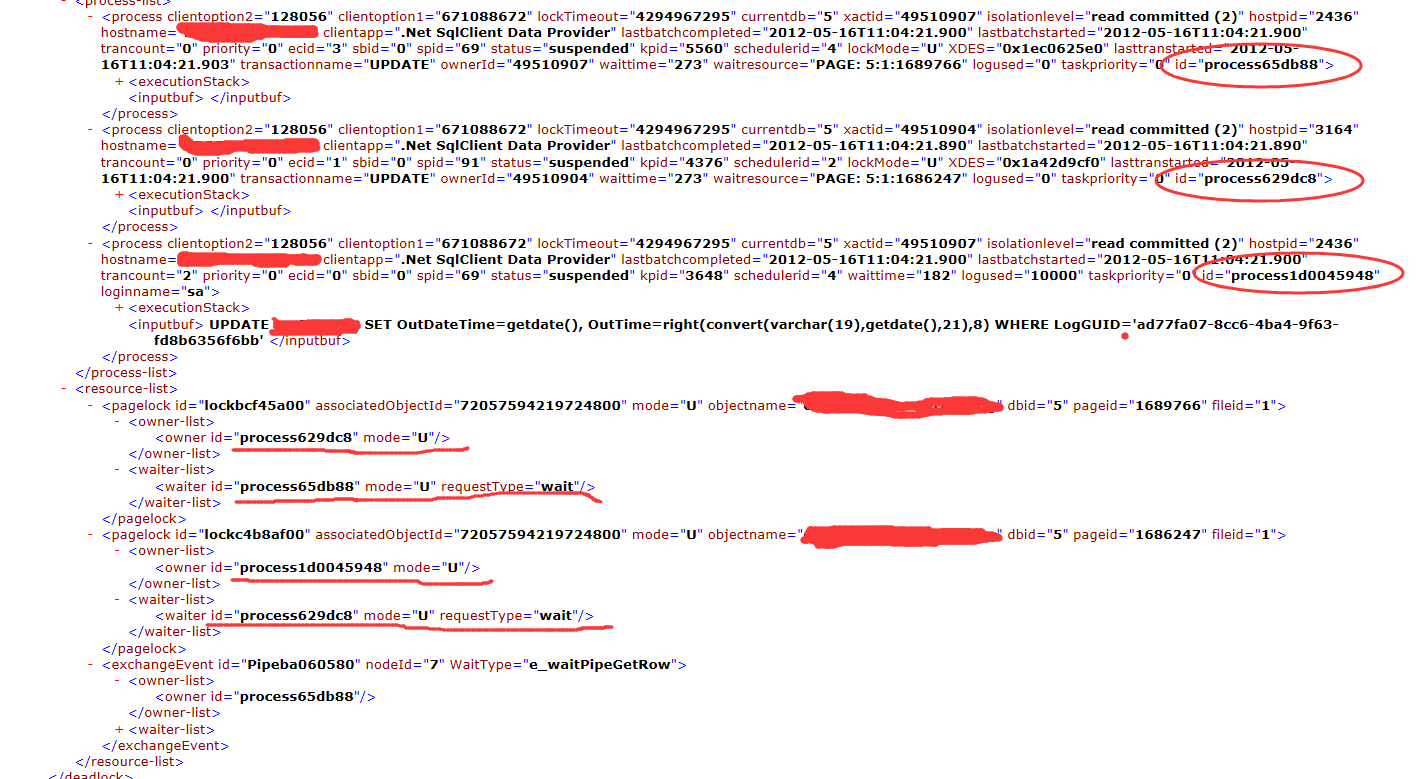
MSSQL死锁产生的原因与解决方法 一、 死锁是什么? 死锁是指两个或者两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若没有外力作用,它们都将无法继续推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等的进程就称为死锁进程. 二、 死锁产生的四个必要条件 1、互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放 2、不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放 3、请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放 4、环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源 这四个条件是死锁的必要条件,只要系统发生死锁,那么这些条件必然成立,而只要上述条件有一个不满足,那么就不会发生死锁。 三、 处理死锁的方法 1) 锁模式 1.独占锁(X) 对资源独占的锁,一个进程独占地锁定了请求的数据源,那么别的进程无法在此数据源上获得任何类型的锁。独占锁一致持有到事务结束。 2.共享锁(S) 由读操作创建的锁,防止在读取数据的过程中,其它事务对数据进行更新;其它事务可以并发读取数据。共享锁可以加在表、页、索引键或者数据行上。在SQL SERVER默认隔离级别下数据读取完毕后就会释放共享锁,但可以通过锁提示或设置更高的事务隔离级别改变共享锁的释放时间。 3.更新锁(U) 更新锁实际上并不是一种独立的锁,而是共享锁与独占锁的混合。当SQL SERVER执行数据修改操作却首先需要搜索表以找到需要修改的资源时,会获得更新锁。 更新锁与共享锁兼容,但只有一个进程可以获取当前数据源上的更新锁, 其它进程无法获取该资源的更新锁或独占锁,更新锁的作用就好像一个序列化阀门(serialization gate),将后续申请独占锁的请求压入队列中。持有更新锁的进程能够将其转换成该资源上的独占锁。更新锁不足以用于更新数据—实际的数据修改仍需要用到独占锁。对于独占锁的序列化访问可以避免转换死锁的发生,更新锁会保留到事务结束或者当它们转换成独占锁时为止。 4. 特殊锁模式(Sch_s,Sch_m,BU) SQL SERVER提供3种额外的锁模式:架构稳定锁、架构修改锁、大容量更新锁。 5. 意向锁(IX,IU,IS) 意向锁并不是独立的锁定模式,而是一种指出哪些资源已经被锁定的机制。 如果一个表页上存在独占锁,那么另一个进程就无法获得该表上的共享表锁,这种层次关系是用意向锁来实现的。进程要获得独占页锁、更新页锁或意向独占页锁,首先必须获得该表上的意向独占锁。同理,进程要获得共享行锁,必须首先获得该表的意向共享锁,以防止别的进程获得独占表锁。 6.键范围锁 键范围锁是在可序列化隔离级别中锁定一定范围内数据的锁。保证在查询数据的键范围内不允许插入数据。 7.转换锁(SIX,SIU,UIX) 转换锁不会由SQL SERVER 直接请求,而是从一种模式转换到另一种模式所造成的。SQL SERVER 2008支持3种类型的转换锁:SIX、SIU、UIX.其中最常见的是SIX锁,如果事务持有一个资源上的共享锁(S),然后又需要一个IX锁,此时就会出现SIX。 2) 锁粒度 SQL SERVER 可以在表、页、行等级别锁定用户的数据资源即非系统资源(系统资源是用闩锁来保护的)。此外SQL SERVER 还可以锁定索引键和索引键范围。 通过sys.dm_tran_locks视图可以查看谁被锁定了(如行,键,页)、锁的模式以及特定资源的标志符。基于sys.dm_tran_locks视图创建如下视图用于查看锁定的资源以及锁模式(通过这个视图可以查看事务锁定的表、页、行以及加在数据资源上的锁类型)。 CREATE VIEW dblocks AS SELECT request_session_id AS spid, DB_NAME(resource_database_id) AS dbname, CASE WHEN resource_type='object' THEN OBJECT_NAME(resource_associated_entity_id) WHEN resource_associated_entity_id=0 THEN 'n/a' ELSE OBJECT_NAME(p.object_id) END AS entity_name, index_id, resource_type AS RESOURCE, resource_description AS DESCRIPTION, request_mode AS mode, request_status AS STATUS FROM sys.dm_tran_locks t LEFT JOIN sys.partitions p ON p.partition_id=t.resource_associated_entity_id WHERE resource_database_id=DB_ID() 3) 如何跟踪死锁 通过选择sql server profiler 事件中的如下选项就可以跟踪到死锁产生的相关语句。 4) 死锁案例分析 在上述案例中process65db88, process1d0045948为语句1的进程,process629dc8 为语句2的进程; 语句2获取了1689766页上的更新锁,在等待1686247页上的更新锁;而语句1则获取了1686247页上的更新锁在等待1689766页上的更新锁,两个语句等待的资源形成了一个环路,造成死锁。 5) 如何解决死锁 针对如上死锁案例,分析其对应语句执行计划如下: 通过执行计划我们可以看出,在查找需要更新的数据时使用的是索引扫描,比较耗费性能,这样就造成锁定资源时间过长,增加了语句并发执行时产生死锁的概率。 处理方式: 1. 在表上建立一个聚集索引。 2. 对语句更新的相关字段建立包含索引。 优化后该语句执行计划如下: 优化后的执行计划使用了索引查找,将大幅提升该查询语句的性能,降低了锁定资源的时间,同时也减少了锁定资源的范围,这样就降低了锁资源循环等待事件发生的概率,对于预防死锁的发生会有一定的作用。 死锁是无法完全避免的,但如果应用程序适当处理死锁,对涉及的任何用户及系统其余部分的影响可降至最低(适当处理是指发生错误1205时,应用程序重新提交批处理,第二次尝试大多能成功。一个进程被杀死,它的事务被取消,它的锁被释放,死锁中涉及到的另一个进程就可以完成它的工作并释放锁,所以就不具备产生另一个死锁的条件了。) 四、 预防死锁的方法 阻止死锁的途径就是避免满足死锁条件的情况发生,为此我们在开发的过程中需要遵循如下原则: 1、尽量避免并发的执行涉及到修改数据的语句。 2、预先规定一个加锁顺序,所有的事务都必须按照这个顺序对数据执行封锁。如不同的过程在事务内部对对象的更新执行顺序应尽量保证一致。 3、要求每一个事务一次就将所有要使用到的数据全部加锁,否则就不允许执行。 4、使用尽可能低的隔离级别。 5、每个事务的执行时间不可太长,对程序段的事务可考虑将其分割为几个事务。在事务中不要求输入,应该在事务之前得到输入,然后快速执行事务。 6、编写应用程序,让进程持有锁的时间尽可能短,这样其它进程就不必花太长的时间等待锁被释放。 7、数据存储空间离散法。该方法是指采用各种手段,将逻辑上在一个表中的数据分散的若干离散的空间上去,以便改善对表的访问性能。主要通过将大表按行或者列分解为若干小表,或者按照不同的用户群两种方法实现。 上一条: Redis介绍以及安装 下一条: Redis启动项Config的配置
|








 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved